

{kind=link}
 |
I’m excited to announce Amazon S3 Information, a brand new file system that seamlessly connects any AWS compute useful resource with Amazon Easy Storage Service (Amazon S3).
Greater than a decade in the past, as an AWS coach, I spent numerous hours explaining the elemental variations between object storage and file techniques. My favourite analogy was evaluating S3 objects to books in a library (you may’t edit a web page, you must substitute the entire guide) versus recordsdata in your pc that you may modify web page by web page. I drew diagrams, created metaphors, and helped clients perceive why they wanted totally different storage sorts for various workloads. Effectively, at this time that distinction turns into a bit extra versatile.
With S3 Information, Amazon S3 is the primary and solely cloud object retailer that gives fully-featured, high-performance file system entry to your knowledge. It makes your buckets accessible as file techniques. This implies modifications to knowledge on the file system are mechanically mirrored within the S3 bucket and you’ve got fine-grained management over synchronization. S3 Information might be connected to a number of compute assets enabling knowledge sharing throughout clusters with out duplication.
Till now, you had to decide on between Amazon S3 price, sturdiness, and the companies that may natively devour knowledge from it or a file system’s interactive capabilities. S3 Information eliminates that tradeoff. S3 turns into the central hub for all of your group’s knowledge. It’s accessible instantly from any AWS compute occasion, container, or operate, whether or not you’re operating manufacturing functions, coaching ML fashions, or constructing agentic AI techniques.
You possibly can entry any basic objective bucket as a local file system in your Amazon Elastic Compute Cloud (Amazon EC2) situations, containers operating on Amazon Elastic Container Service (Amazon ECS) or Amazon Elastic Kubernetes Service (Amazon EKS), or AWS Lambda features. The file system presents S3 objects as recordsdata and directories, supporting all Community File System (NFS) v4.1+ operations like creating, studying, updating, and deleting recordsdata.
As you’re employed with particular recordsdata and directories by means of the file system, related file metadata and contents are positioned onto the file system’s high-performance storage. By default, recordsdata that profit from low-latency entry are saved and served from the excessive efficiency storage. For recordsdata not saved on excessive efficiency storage equivalent to these needing massive sequential reads, S3 Information mechanically serves these recordsdata instantly from Amazon S3 to maximise throughput. For byte-range reads, solely the requested bytes are transferred, minimizing knowledge motion and prices.
The system additionally helps clever pre-fetching to anticipate your knowledge entry wants. You’ve gotten fine-grained management over what will get saved on the file system’s excessive efficiency storage. You possibly can resolve whether or not to load full file knowledge or metadata solely, which implies you may optimize to your particular entry patterns.
Beneath the hood, S3 Information makes use of Amazon Elastic File System (Amazon EFS) and delivers ~1ms latencies for energetic knowledge. The file system helps concurrent entry from a number of compute assets with NFS close-to-open consistency, making it very best for interactive, shared workloads that mutate knowledge, from agentic AI brokers collaborating by means of file-based instruments to ML coaching pipelines processing datasets.
Let me present you the way to get began.
Creating my first Amazon S3 file system, mounting, and utilizing it from an EC2 occasion is simple.
I’ve an EC2 occasion and a basic objective bucket. On this demo, I configure an S3 file system and entry the bucket from an EC2 occasion, utilizing common file system instructions.
For this demo, I take advantage of the AWS Administration Console. You too can use the AWS Command Line Interface (AWS CLI) or infrastructure as code (IaC).
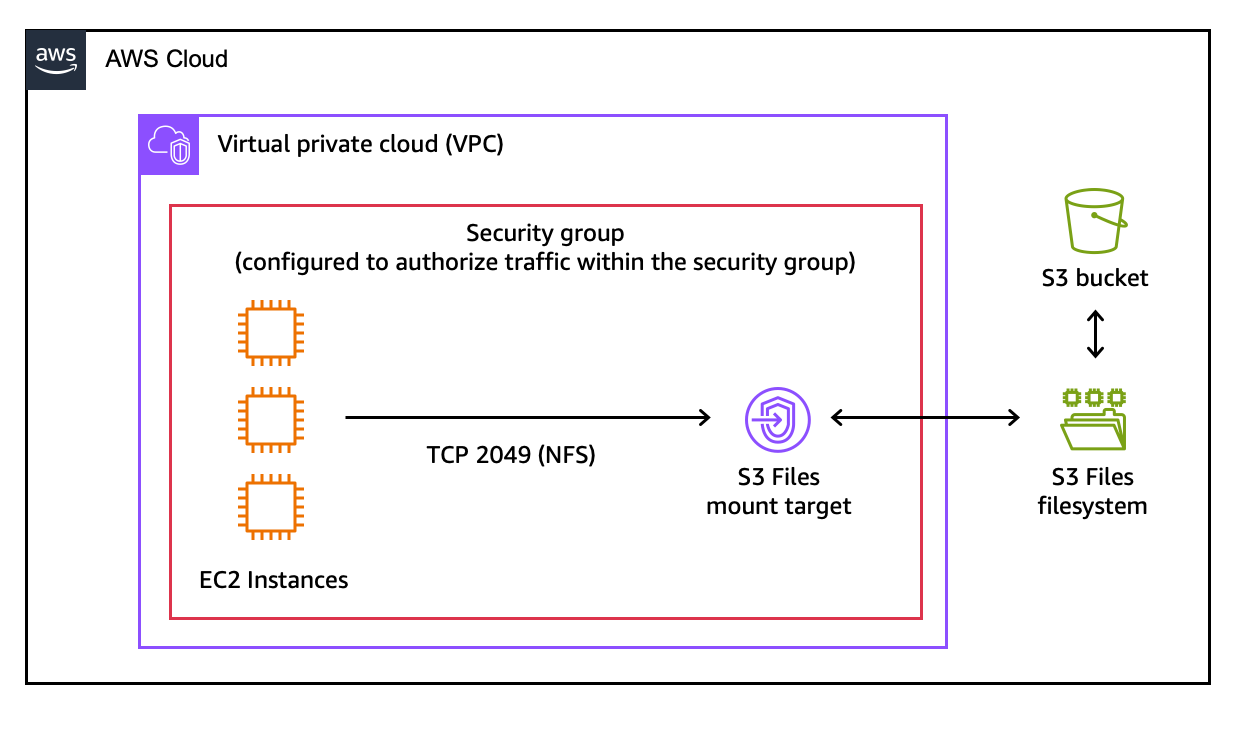
Right here is the structure diagram for this demo.
 Step 1: Create an S3 file system.
Step 1: Create an S3 file system.
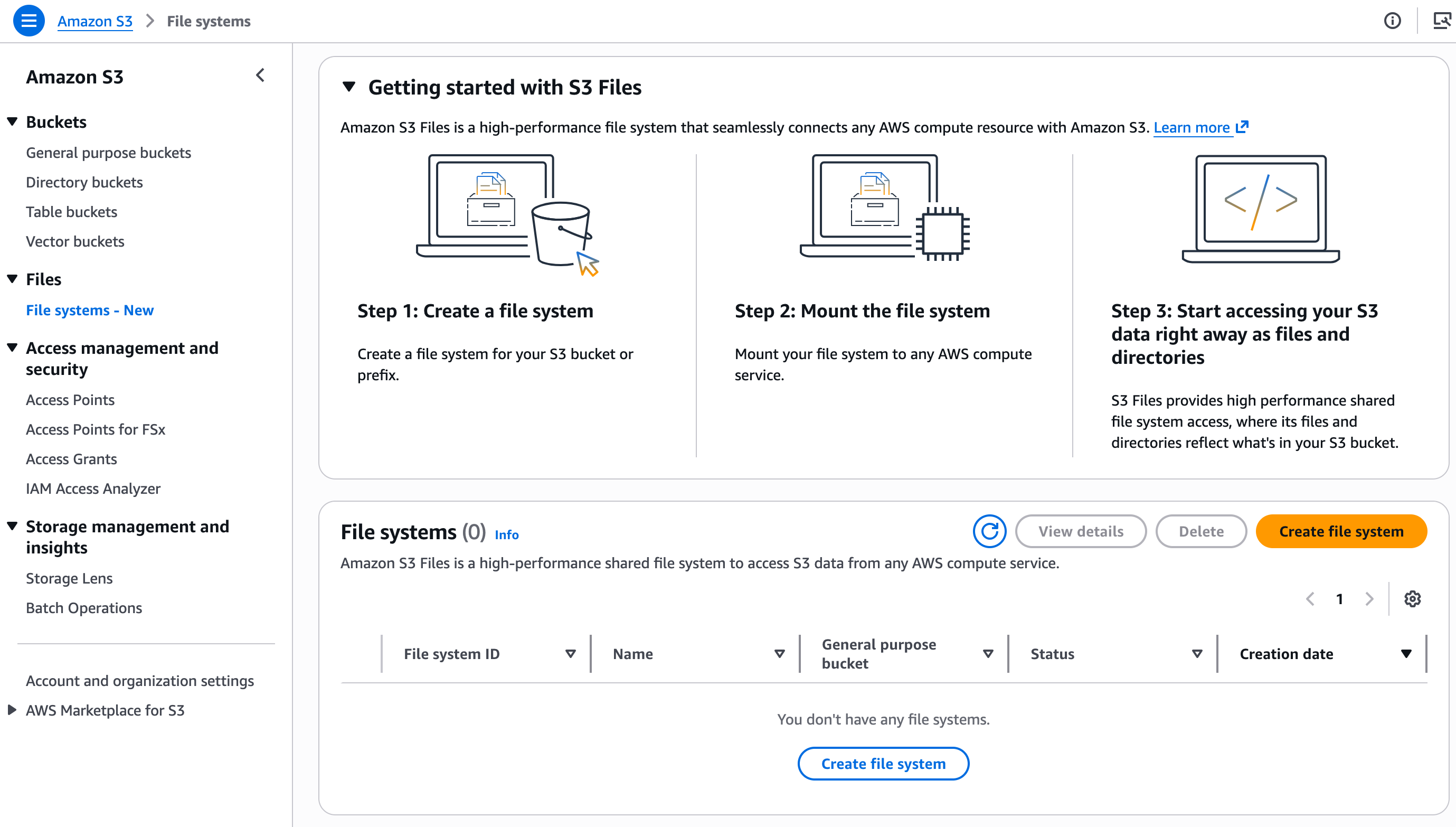
On the Amazon S3 part of the console, I select File techniques after which Create file system.
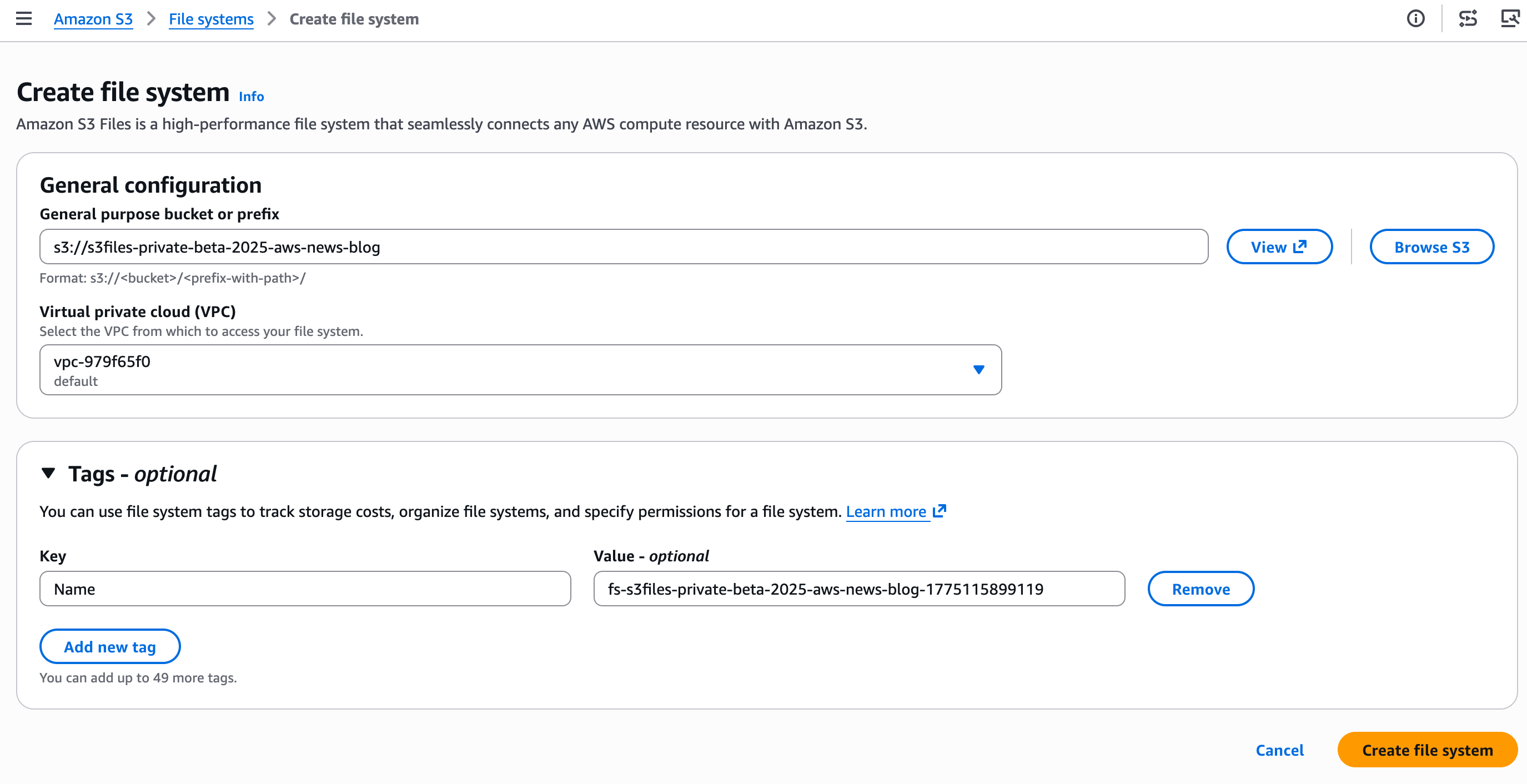
I enter the identify of the bucket I need to expose as a file system and select Create file system.
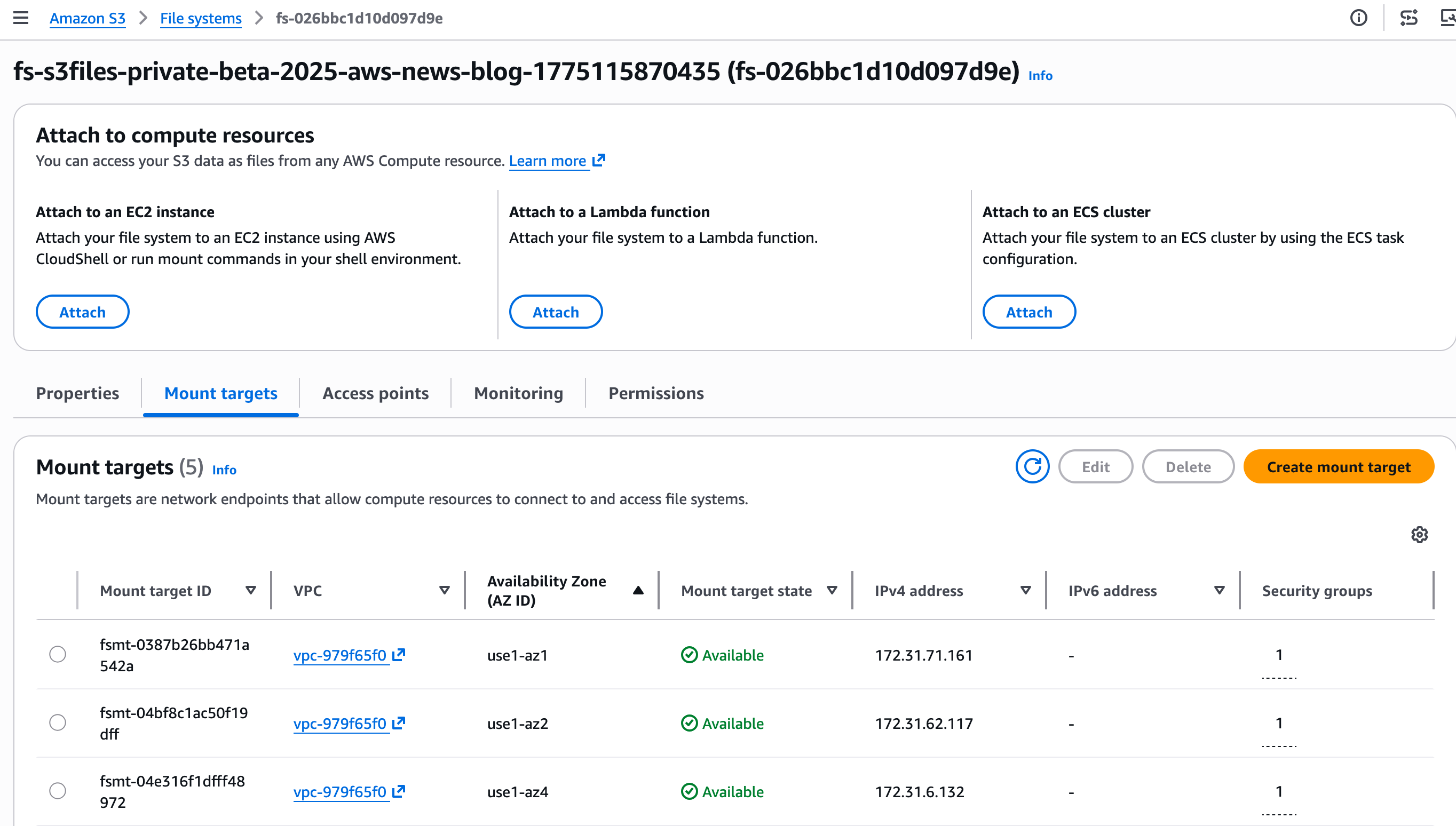
Step 2: Uncover the mount goal.
A mount goal is a community endpoint that can dwell in my digital non-public cloud (VPC). It permits my EC2 occasion to entry the S3 file system.
The console creates the mount targets mechanically. I take notes of the Mount goal IDs on the Mount targets tab.
When utilizing the CLI, two separate instructions are essential to create the file system and its mount targets. First, I create the S3 file system with create-file-system. Then, I create the mount goal with create-mount-target.
Step 3: Mount the file system on my EC2 occasion.
After it’s related to an EC2 occasion, I sort:
sudo mkdir /residence/ec2-user/s3files sudo mount -t s3files fs-0aa860d05df9afdfe:/ /residence/ec2-user/s3files
I can now work with my S3 knowledge instantly by means of the mounted file system in ~/s3files, utilizing commonplace file operations.
Once I make updates to my recordsdata within the file system, S3 mechanically manages and exports all updates as a brand new object or a brand new model on an present object again in my S3 bucket inside minutes.
Adjustments made to things on the S3 bucket are seen within the file system inside just a few seconds however can typically take a minute or longer.
# Create a file on the EC2 file system
echo "Hi there S3 Information" > s3files/hiya.txt
# and confirm it is right here
ls -al s3files/hiya.txt
-rw-r--r--. 1 ec2-user ec2-user 15 Oct 22 13:03 s3files/hiya.txt
# See? the file can also be on S3
aws s3 ls s3://s3files-aws-news-blog/hiya.txt
2025-10-22 13:04:04 15 hiya.txt
# And the content material is an identical!
aws s3 cp s3://s3files-aws-news-blog/hiya.txt . && cat hiya.txt
Hi there S3 InformationIssues to know
Let me share some essential technical particulars that I believe you’ll discover helpful.
One other query I steadily hear in buyer conversations is about selecting the best file service to your workloads. Sure, I do know what you’re considering: AWS and its seemingly overlapping companies, holding cloud architects entertained throughout their structure evaluation conferences. Let me assist demystify this one.
S3 Information works greatest while you want interactive, shared entry to knowledge that lives in Amazon S3 by means of a excessive efficiency file system interface. It’s very best for workloads the place a number of compute assets—whether or not manufacturing functions, agentic AI brokers utilizing Python libraries and CLI instruments, or machine studying (ML) coaching pipelines—must learn, write, and mutate knowledge collaboratively. You get shared entry throughout compute clusters with out knowledge duplication, sub-millisecond latency, and computerized synchronization together with your S3 bucket.
For workloads migrating from on-premises NAS environments, Amazon FSx gives the acquainted options and compatibility you want. Amazon FSx can also be very best for high-performance computing (HPC) and GPU cluster storage with Amazon FSx for Lustre. It’s significantly beneficial when your functions require particular file system capabilities from Amazon FSx for NetApp ONTAP, Amazon FSx for OpenZFS, or Amazon FSx for Home windows File Server.
Pricing and availability
S3 Information is on the market at this time in all business AWS Areas.
You pay for the portion of knowledge saved in your S3 file system, for small file learn and all write operations to the file system, and for S3 requests throughout knowledge synchronization between the file system and the S3 bucket. The Amazon S3 pricing web page has all the main points.
From discussions with clients, I consider S3 Information helps simplify cloud architectures by eliminating knowledge silos, synchronization complexity, and handbook knowledge motion between objects and recordsdata. Whether or not you’re operating manufacturing instruments that already work with file techniques, constructing agentic AI techniques that depend on file-based Python libraries and shell scripts, or getting ready datasets for ML coaching, S3 Information lets these interactive, shared, hierarchical workloads entry S3 knowledge instantly with out selecting between the sturdiness of Amazon S3 and value advantages and a file system’s interactive capabilities. Now you can use Amazon S3 because the place for all of your organizations’ knowledge, realizing the info is accessible instantly from any AWS compute occasion, container, and performance.
To be taught extra and get began, go to the S3 Information documentation.
I’d love to listen to how you utilize this new functionality. Be happy to share your suggestions within the feedback beneath.