

{kind=link}
Each database constructed for real-time analytics has a elementary limitation. Whenever you deconstruct the core database structure, deep within the coronary heart of it you will discover a single element that’s performing two distinct competing features: real-time knowledge ingestion and question serving. These two components operating on the identical compute unit is what makes the database real-time: queries can replicate the impact of the brand new knowledge that was simply ingested. However, these two features instantly compete for the obtainable compute assets, making a elementary limitation that makes it tough to construct environment friendly, dependable real-time purposes at scale. When knowledge ingestion has a flash flood second, your queries will decelerate or trip making your software flaky. When you might have a sudden surprising burst of queries, your knowledge will lag making your software not so actual time anymore.
This modifications at present. We unveil true compute-compute separation that eliminates this elementary limitation, and makes it potential to construct environment friendly, dependable real-time purposes at large scale.
Study extra concerning the new structure and the way it delivers efficiencies within the cloud on this tech discuss I hosted with principal architect Nathan Bronson Compute-Compute Separation: A New Cloud Structure for Actual-Time Analytics.
The Problem of Compute Competition
On the coronary heart of each real-time software you might have this sample that the information by no means stops coming in and requires steady processing, and the queries by no means cease – whether or not they come from anomaly detectors that run 24×7 or end-user-facing analytics.
Unpredictable Information Streams
Anybody who has managed real-time knowledge streams at scale will let you know that knowledge flash floods are fairly widespread. Even probably the most behaved and predictable real-time streams could have occasional bursts the place the quantity of the information goes up in a short time. If left unchecked the information ingestion will utterly monopolize your whole real-time database and end in question gradual downs and timeouts. Think about ingesting behavioral knowledge on an e-commerce web site that simply launched a giant marketing campaign, or the load spikes a fee community will see on Cyber Monday.
Unpredictable Question Workloads
Equally, while you construct and scale purposes, unpredictable bursts from the question workload are par for the course. On some events they’re predictable based mostly on time of day and seasonal upswings, however there are much more conditions when these bursts can’t be predicted precisely forward of time. When question bursts begin consuming all of the compute within the database, then they’ll take away compute obtainable for the real-time knowledge ingestion, leading to knowledge lags. When knowledge lags go unchecked then the real-time software can not meet its necessities. Think about a fraud anomaly detector triggering an in depth set of investigative queries to grasp the incident higher and take remedial motion. If such question workloads create extra knowledge lags then it is going to actively trigger extra hurt by growing your blind spot on the actual unsuitable time, the time when fraud is being perpetrated.
How Different Databases Deal with Compute Competition
Information warehouses and OLTP databases have by no means been designed to deal with excessive quantity streaming knowledge ingestion whereas concurrently processing low latency, excessive concurrency queries. Cloud knowledge warehouses with compute-storage separation do supply batch knowledge hundreds operating concurrently with question processing, however they supply this functionality by giving up on actual time. The concurrent queries is not going to see the impact of the information hundreds till the information load is full, creating 10s of minutes of information lags. So they aren’t appropriate for real-time analytics. OLTP databases aren’t constructed to ingest large volumes of information streams and carry out stream processing on incoming datasets. Thus OLTP databases usually are not suited to real-time analytics both. So, knowledge warehouses and OLTP databases have hardly ever been challenged to energy large scale real-time purposes, and thus it’s no shock that they haven’t made any makes an attempt to deal with this difficulty.
Elasticsearch, Clickhouse, Apache Druid and Apache Pinot are the databases generally used for constructing real-time purposes. And if you happen to examine each considered one of them and deconstruct how they’re constructed, you will note all of them wrestle with this elementary limitation of information ingestion and question processing competing for a similar compute assets, and thereby compromise the effectivity and the reliability of your software. Elasticsearch helps particular objective ingest nodes that offload some components of the ingestion course of corresponding to knowledge enrichment or knowledge transformations, however the compute heavy a part of knowledge indexing is completed on the identical knowledge nodes that additionally do question processing. Whether or not these are Elasticsearch’s knowledge nodes or Apache Druid’s knowledge servers or Apache Pinot’s real-time servers, the story is just about the identical. A number of the techniques make knowledge immutable, as soon as ingested, to get round this difficulty – however actual world knowledge streams corresponding to CDC streams have inserts, updates and deletes and never simply inserts. So not dealing with updates and deletes shouldn’t be actually an possibility.
Coping Methods for Compute Competition
In observe, methods used to handle this difficulty typically fall into considered one of two classes: overprovisioning compute or making replicas of your knowledge.
Overprovisioning Compute
It is rather widespread observe for real-time software builders to overprovision compute to deal with each peak ingest and peak question bursts concurrently. This can get value prohibitive at scale and thus shouldn’t be a great or sustainable answer. It is not uncommon for directors to tweak inside settings to arrange peak ingest limits or discover different methods to both compromise knowledge freshness or question efficiency when there’s a load spike, whichever path is much less damaging for the appliance.
Make Replicas of your Information
The opposite strategy we’ve seen is for knowledge to be replicated throughout a number of databases or database clusters. Think about a major database doing all of the ingest and a reproduction serving all the appliance queries. When you might have 10s of TiBs of information this strategy begins to turn out to be fairly infeasible. Duplicating knowledge not solely will increase your storage prices, but additionally will increase your compute prices because the knowledge ingestion prices are doubled too. On high of that, knowledge lags between the first and the reproduction will introduce nasty knowledge consistency points your software has to cope with. Scaling out would require much more replicas that come at a good greater value and shortly your entire setup turns into untenable.
How We Constructed Compute-Compute Separation
Earlier than I am going into the small print of how we solved compute competition and carried out compute-compute separation, let me stroll you thru a couple of essential particulars on how Rockset is architected internally, particularly round how Rockset employs RocksDB as its storage engine.
RocksDB is likely one of the hottest Log Structured Merge tree storage engines on the earth. Again once I used to work at fb, my workforce, led by superb builders corresponding to Dhruba Borthakur and Igor Canadi (who additionally occur to be the co-founder and founding architect at Rockset), forked the LevelDB code base and turned it into RocksDB, an embedded database optimized for server-side storage. Some understanding of how Log Structured Merge tree (LSM) storage engines work will make this half simple to comply with and I encourage you to confer with some wonderful supplies on this topic such because the RocksDB Structure Information. In order for you absolutely the newest analysis on this house, learn the 2019 survey paper by Chen Lou and Prof. Michael Carey.
In LSM Tree architectures, new writes are written to an in-memory memtable and memtables are flushed, once they replenish, into immutable sorted strings desk (SST) information. Distant compactors, just like rubbish collectors in language runtimes, run periodically, take away stale variations of the information and stop database bloat.
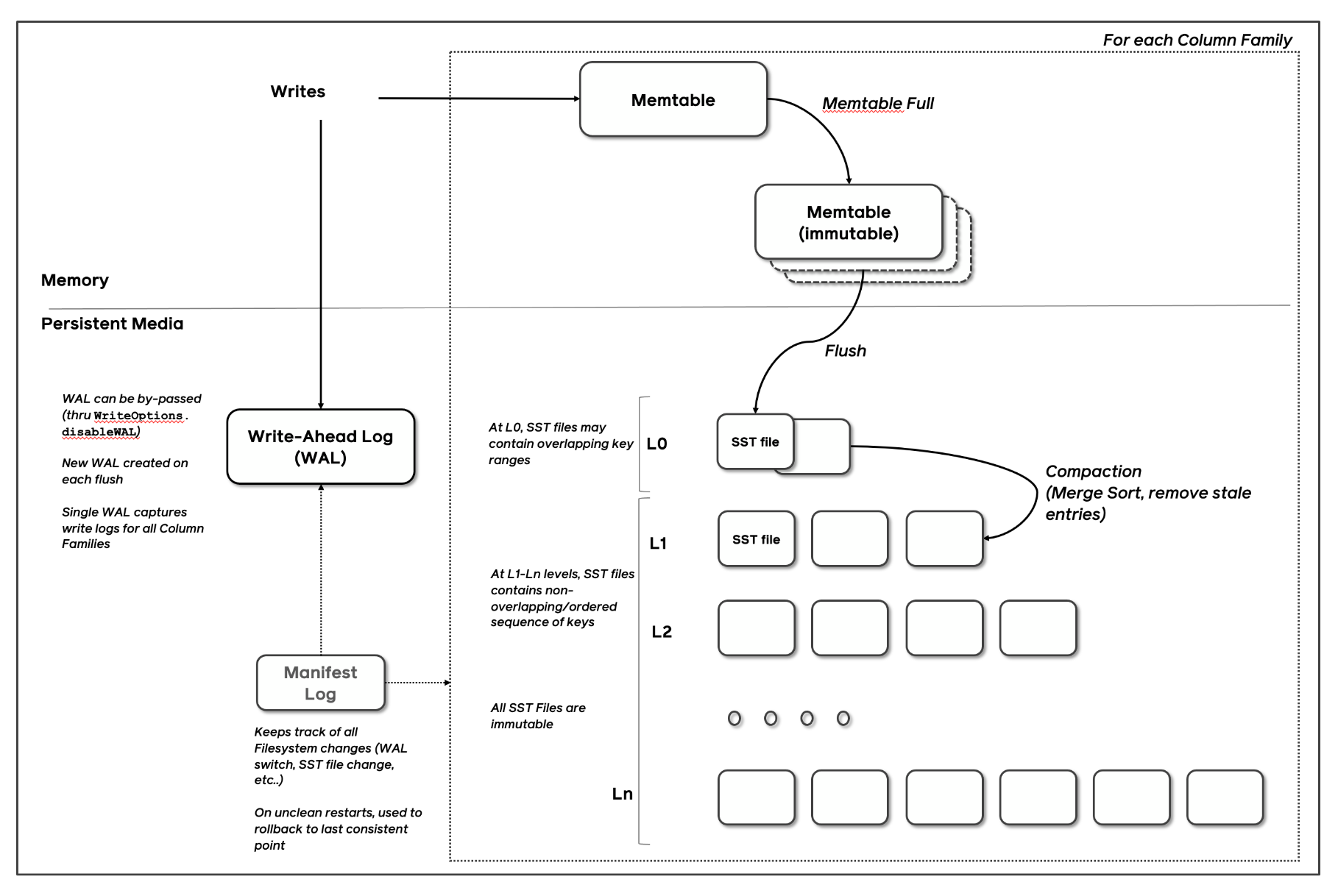
Each Rockset assortment makes use of a number of RocksDB cases to retailer the information. Information ingested right into a Rockset assortment can be written to the related RocksDB occasion. Rockset’s distributed SQL engine accesses knowledge from the related RocksDB occasion throughout question processing.
Step 1: Separate Compute and Storage
One of many methods we first prolonged RocksDB to run within the cloud was by constructing RocksDB Cloud, wherein the SST information created upon a memtable flush are additionally backed into cloud storage corresponding to Amazon S3. RocksDB Cloud allowed Rockset to utterly separate the “efficiency layer” of the information administration system chargeable for quick and environment friendly knowledge processing from the “sturdiness layer” chargeable for guaranteeing knowledge is rarely misplaced.
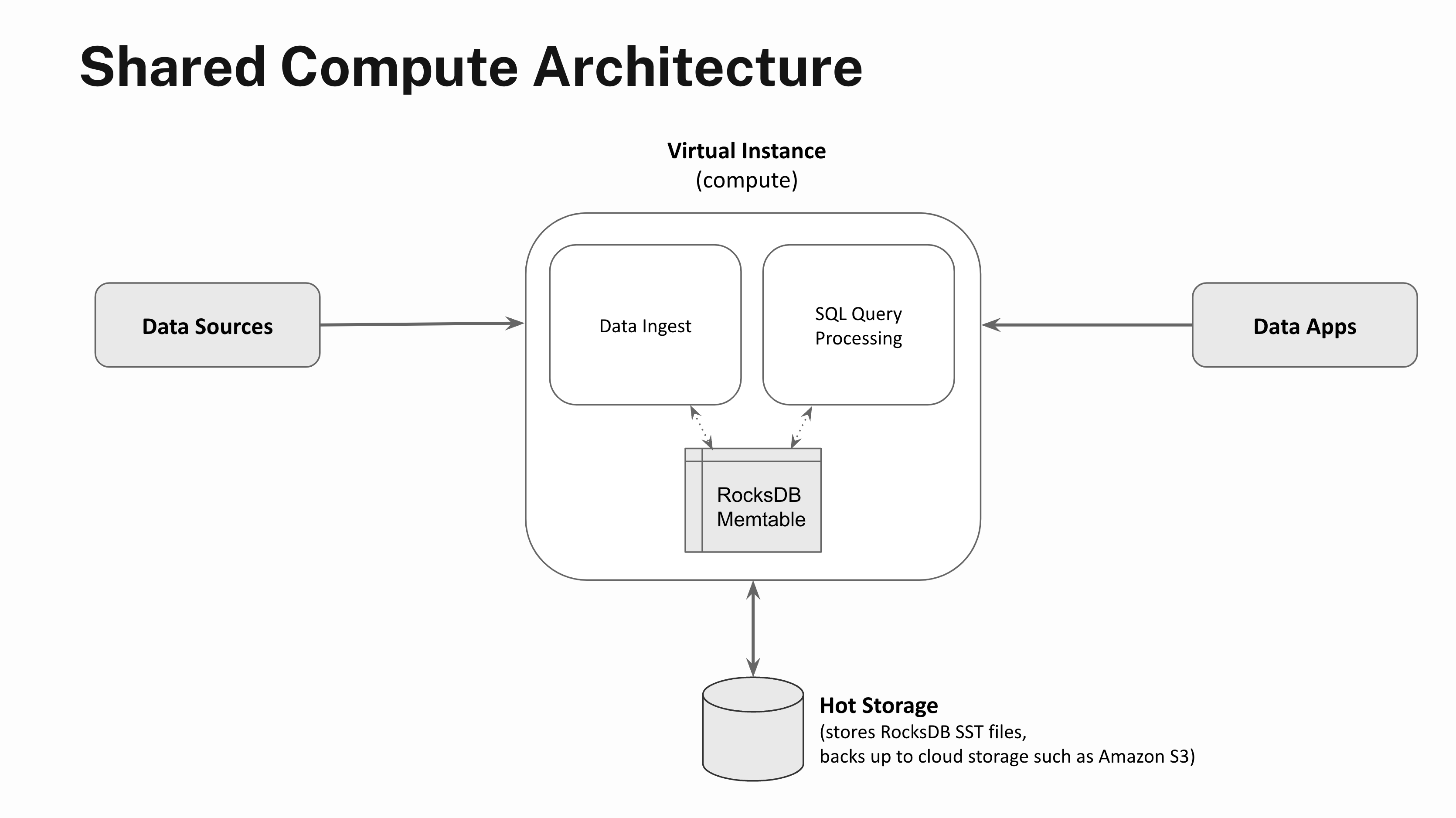
Actual-time purposes demand low-latency, high-concurrency question processing. So whereas constantly backing up knowledge to Amazon S3 offers sturdy sturdiness ensures, knowledge entry latencies are too gradual to energy real-time purposes. So, along with backing up the SST information to cloud storage, Rockset additionally employs an autoscaling sizzling storage tier backed by NVMe SSD storage that enables for full separation of compute and storage.
Compute models spun as much as carry out streaming knowledge ingest or question processing are known as Digital Situations in Rockset. The recent storage tier scales elastically based mostly on utilization and serves the SST information to Digital Situations that carry out knowledge ingestion, question processing or knowledge compactions. The recent storage tier is about 100-200x sooner to entry in comparison with chilly storage corresponding to Amazon S3, which in flip permits Rockset to offer low-latency, high-throughput question processing.
Step 2: Separate Information Ingestion and Question Processing Code Paths
Let’s go one degree deeper and have a look at all of the totally different components of information ingestion. When knowledge will get written right into a real-time database, there are basically 4 duties that have to be finished:
- Information parsing: Downloading knowledge from the information supply or the community, paying the community RPC overheads, knowledge decompressing, parsing and unmarshalling, and so forth
- Information transformation: Information validation, enrichment, formatting, sort conversions and real-time aggregations within the type of rollups
- Information indexing: Information is encoded within the database’s core knowledge constructions used to retailer and index the information for quick retrieval. In Rockset, that is the place Converged Indexing is carried out
- Compaction (or vacuuming): LSM engine compactors run within the background to take away stale variations of the information. Notice that this half isn’t just particular to LSM engines. Anybody who has ever run a VACUUM command in PostgreSQL will know that these operations are important for storage engines to offer good efficiency even when the underlying storage engine shouldn’t be log structured.
The SQL processing layer goes by means of the everyday question parsing, question optimization and execution phases like some other SQL database.
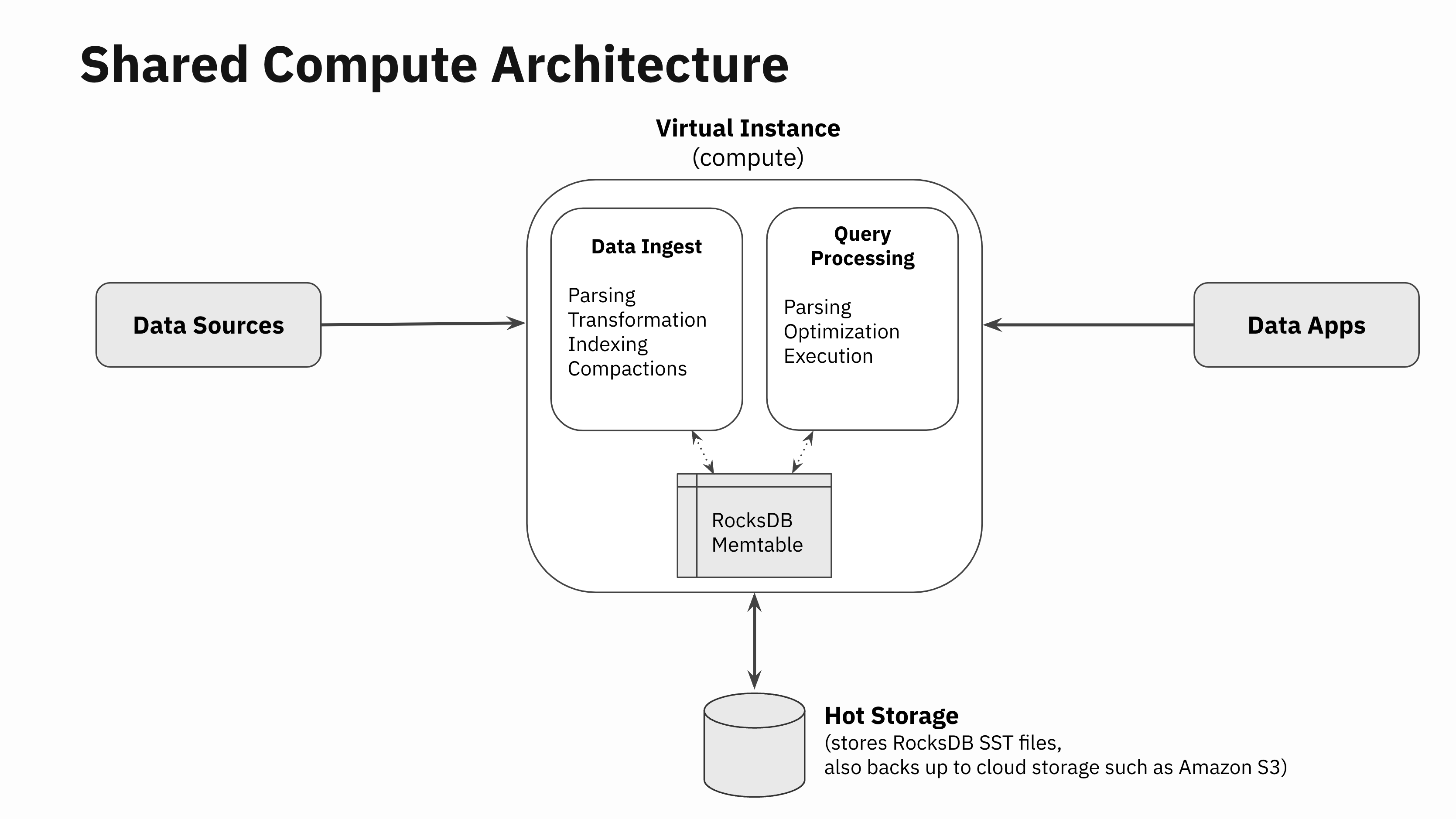
Constructing compute-compute separation has been a long run purpose for us because the very starting. So, we designed Rockset’s SQL engine to be utterly separated from all of the modules that do knowledge ingestion. There aren’t any software program artifacts corresponding to locks, latches, or pinned buffer blocks which can be shared between the modules that do knowledge ingestion and those that do SQL processing exterior of RocksDB. The info ingestion, transformation and indexing code paths work utterly independently from the question parsing, optimization and execution.
RocksDB helps multi-version concurrency management, snapshots, and has an enormous physique of labor to make numerous subcomponents multi-threaded, remove locks altogether and scale back lock competition. Given the character of RocksDB, sharing state in SST information between readers, writers and compactors might be achieved with little to no coordination. All these properties enable our implementation to decouple the information ingestion from question processing code paths.
So, the one cause SQL question processing is scheduled on the Digital Occasion doing knowledge ingestion is to entry the in-memory state in RocksDB memtables that maintain probably the most lately ingested knowledge. For question outcomes to replicate probably the most lately ingested knowledge, entry to the in-memory state in RocksDB memtables is crucial.
Step 3: Replicate In-Reminiscence State
Somebody within the Seventies at Xerox took a photocopier, cut up it right into a scanner and a printer, linked these two components over a phone line and thereby invented the world’s first phone fax machine which utterly revolutionized telecommunications.
Related in spirit to the Xerox hack, in one of many Rockset hackathons a couple of 12 months in the past, two of our engineers, Nathan Bronson and Igor Canadi, took RocksDB, cut up the half that writes to RocksDB memtables from the half that reads from the RocksDB memtable, constructed a RocksDB memtable replicator, and linked it over the community. With this functionality, now you can write to a RocksDB occasion in a single Digital Occasion, and inside milliseconds replicate that to a number of distant Digital Situations effectively.
Not one of the SST information should be replicated since these information are already separated from compute and are saved and served from the autoscaling sizzling storage tier. So, this replicator solely focuses on replicating the in-memory state in RocksDB memtables. The replicator additionally coordinates flush actions in order that when the memtable is flushed on the Digital Occasion ingesting the information, the distant Digital Situations know to go fetch the brand new SST information from the shared sizzling storage tier.
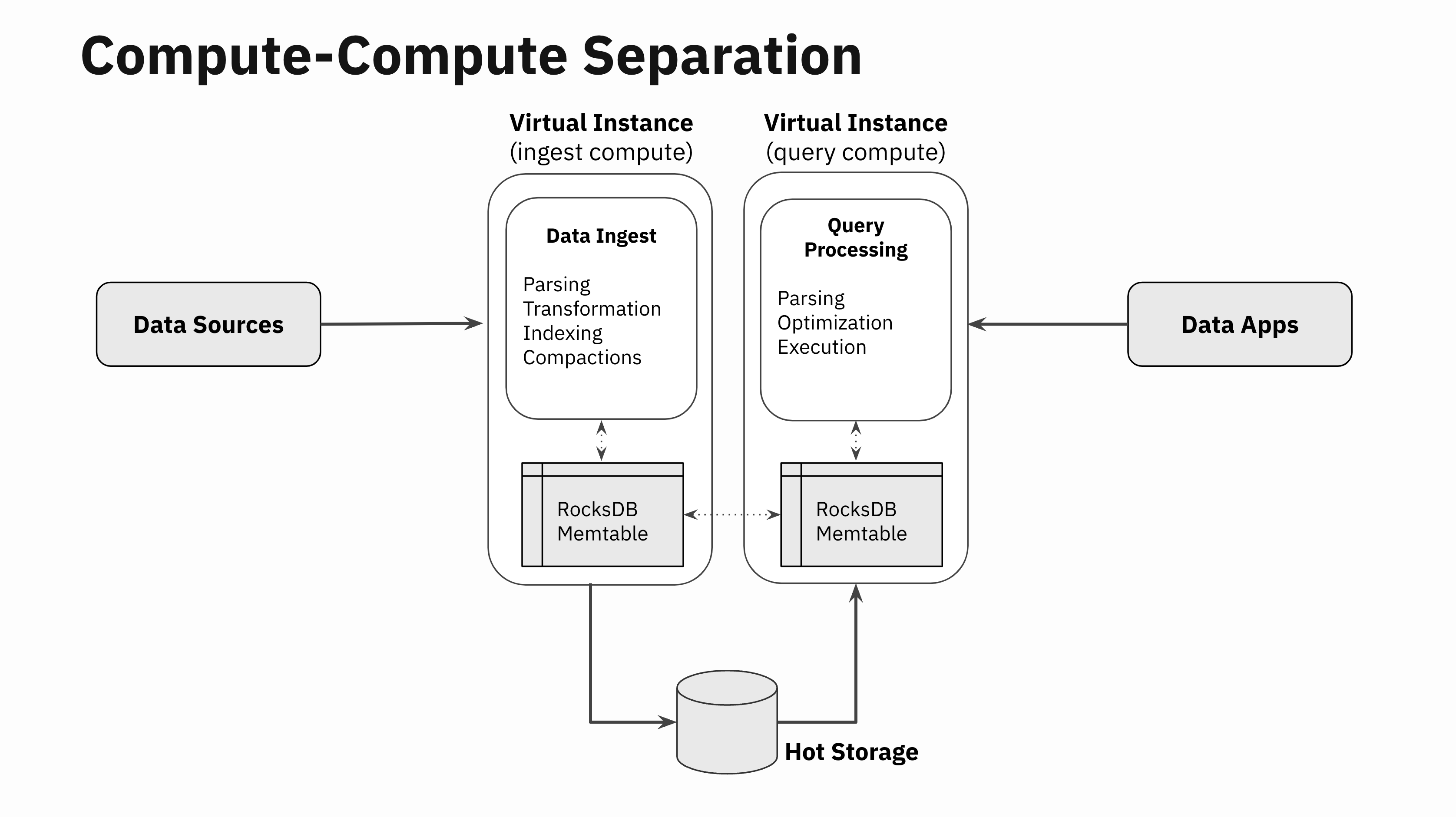
This easy hack of replicating RocksDB memtables is an enormous unlock. The in-memory state of RocksDB memtables might be accessed effectively in distant Digital Situations that aren’t doing the information ingestion, thereby essentially separating the compute wants of information ingestion and question processing.
This explicit methodology of implementation has few important properties:
- Low knowledge latency: The extra knowledge latency from when the RocksDB memtables are up to date within the ingest Digital Situations to when the identical modifications are replicated to distant Digital Situations might be stored to single digit milliseconds. There aren’t any huge costly IO prices, storage prices or compute prices concerned, and Rockset employs effectively understood knowledge streaming protocols to maintain knowledge latencies low.
- Sturdy replication mechanism: RocksDB is a dependable, constant storage engine and may emit a “memtable replication stream” that ensures correctness even when the streams are disconnected or interrupted for no matter cause. So, the integrity of the replication stream might be assured whereas concurrently retaining the information latency low. It is usually actually essential that the replication is occurring on the RocksDB key-value degree in any case the most important compute heavy ingestion work has already occurred, which brings me to my subsequent level.
- Low redundant compute expense: Little or no extra compute is required to duplicate the in-memory state in comparison with the whole quantity of compute required for the unique knowledge ingestion. The best way the information ingestion path is structured, the RocksDB memtable replication occurs after all of the compute intensive components of the information ingestion are full together with knowledge parsing, knowledge transformation and knowledge indexing. Information compactions are solely carried out as soon as within the Digital Occasion that’s ingesting the information, and all of the distant Digital Situations will merely choose the brand new compacted SST information instantly from the new storage tier.
It must be famous that there are different naive methods to separate ingestion and queries. A technique can be by replicating the incoming logical knowledge stream to 2 compute nodes, inflicting redundant computations and doubling the compute wanted for streaming knowledge ingestion, transformations and indexing. There are numerous databases that declare comparable compute-compute separation capabilities by doing “logical CDC-like replication” at a excessive degree. You have to be doubtful of databases that make such claims. Whereas duplicating logical streams could seem “ok” in trivial instances, it comes at a prohibitively costly compute value for large-scale use instances.
Leveraging Compute-Compute Separation
There are quite a few real-world conditions the place compute-compute separation might be leveraged to construct scalable, environment friendly and sturdy real-time purposes: ingest and question compute isolation, a number of purposes on shared real-time knowledge, limitless concurrency scaling and dev/check environments.
Ingest and Question Compute Isolation
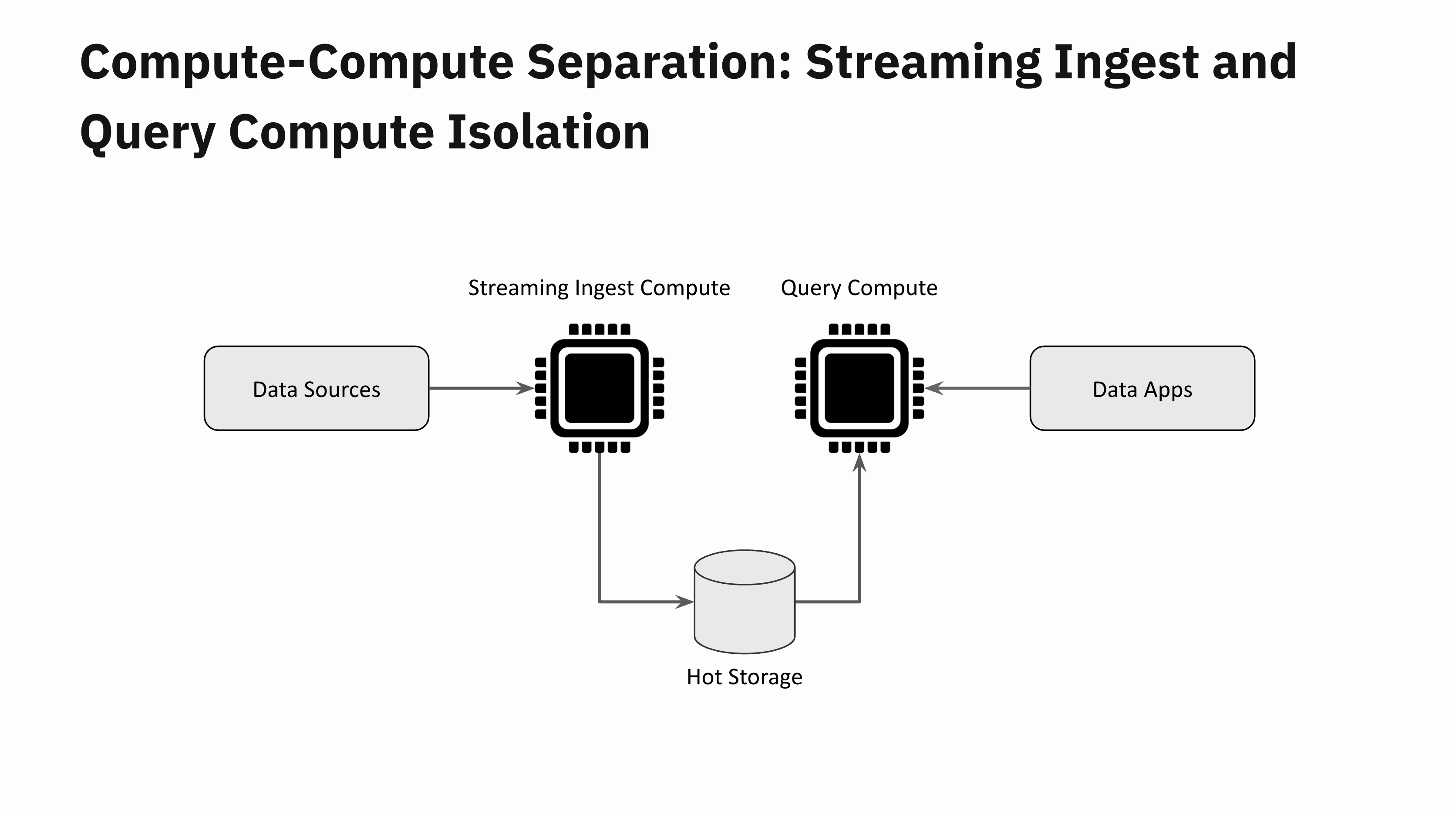
Think about a real-time software that receives a sudden flash flood of latest knowledge. This must be fairly easy to deal with with compute-compute separation. One Digital Occasion is devoted to knowledge ingestion and a distant Digital Occasion one for question processing. These two Digital Situations are absolutely remoted from one another. You may scale up the Digital Occasion devoted to ingestion if you wish to hold the information latencies low, however regardless of your knowledge latencies, your software queries will stay unaffected by the information flash flood.
A number of Purposes on Shared Actual-Time Information
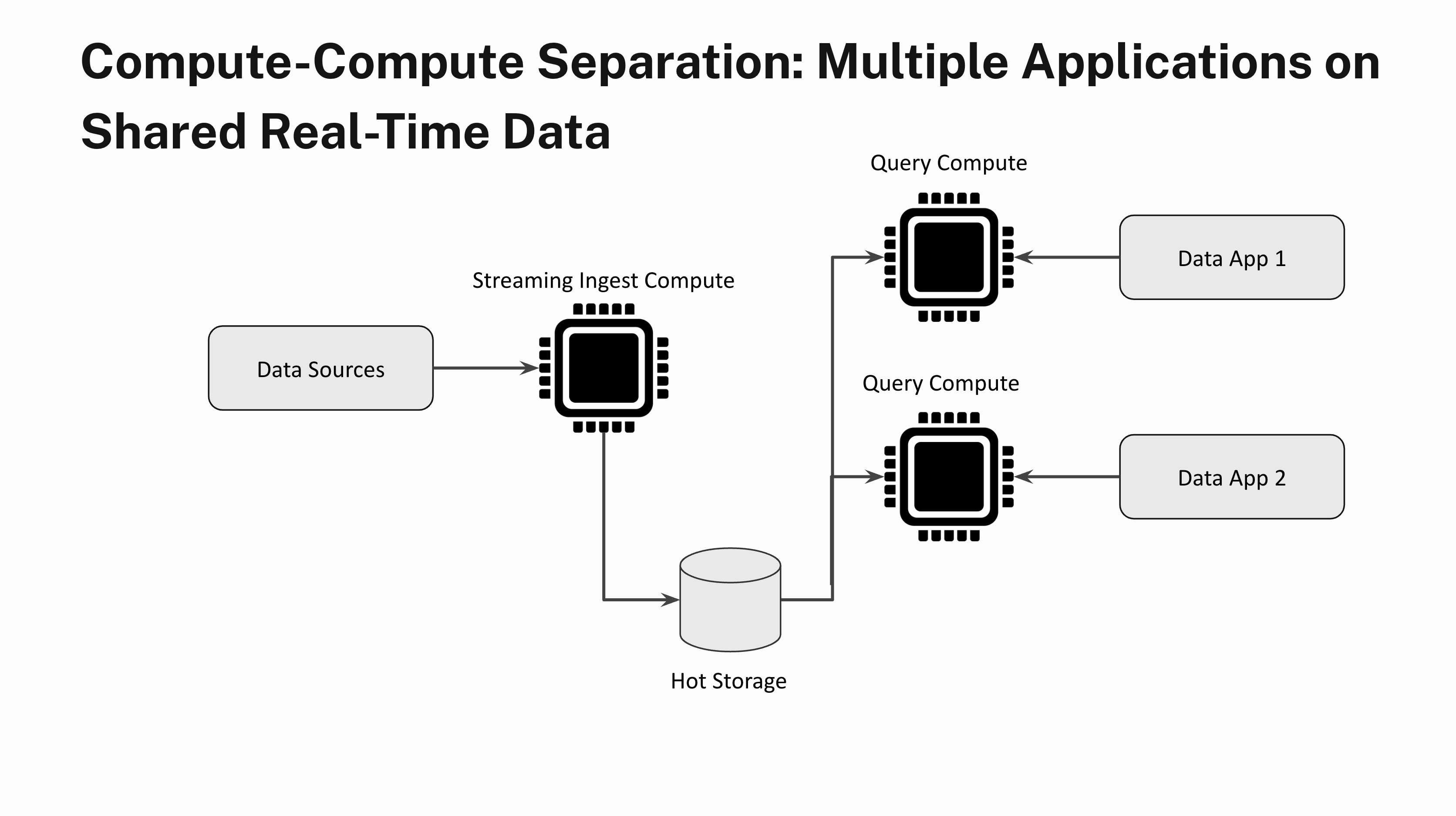
Think about constructing two totally different purposes with very totally different question load traits on the identical real-time knowledge. One software sends a small variety of heavy analytical queries that aren’t time delicate and the opposite software is latency delicate and has very excessive QPS. With compute-compute separation you may absolutely isolate a number of software workloads by spinning up one Digital Occasion for the primary software and a separate Digital Occasion for the second software.
Limitless Concurrency Scaling
Limitless Concurrency Scaling
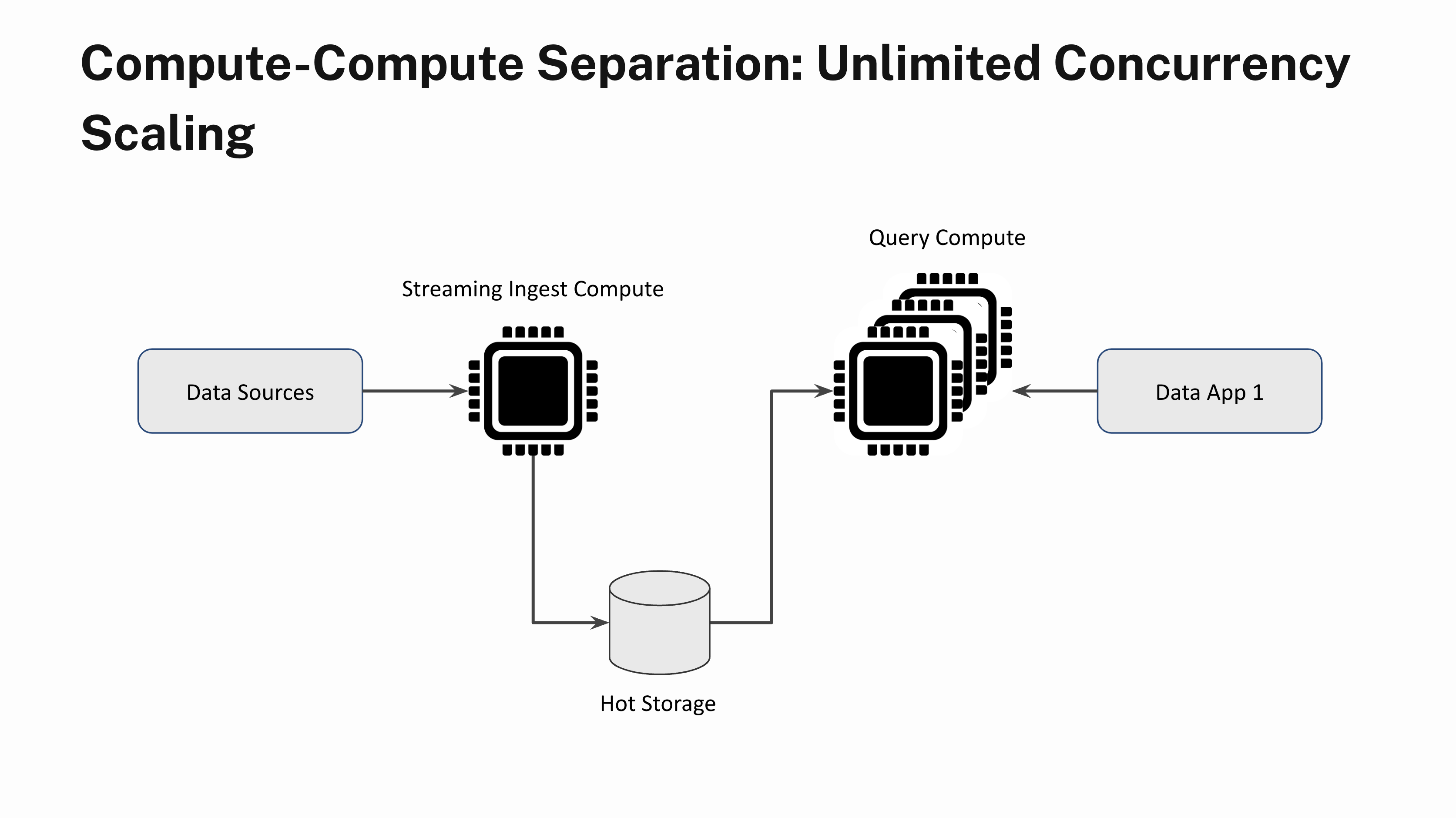
Say you might have a real-time software that sustains a gentle state of 100 queries per second. Often, when a number of customers login to the app on the similar time, you see question bursts. With out compute-compute separation, question bursts will end in a poor software efficiency for all customers during times of excessive demand. With compute-compute separation, you may immediately add extra Digital Situations and scale out linearly to deal with the elevated demand. You may as well scale the Digital Situations down when the question load subsides. And sure, you may scale out with out having to fret about knowledge lags or stale question outcomes.
Advert-hoc Analytics and Dev/Check/Prod Separation
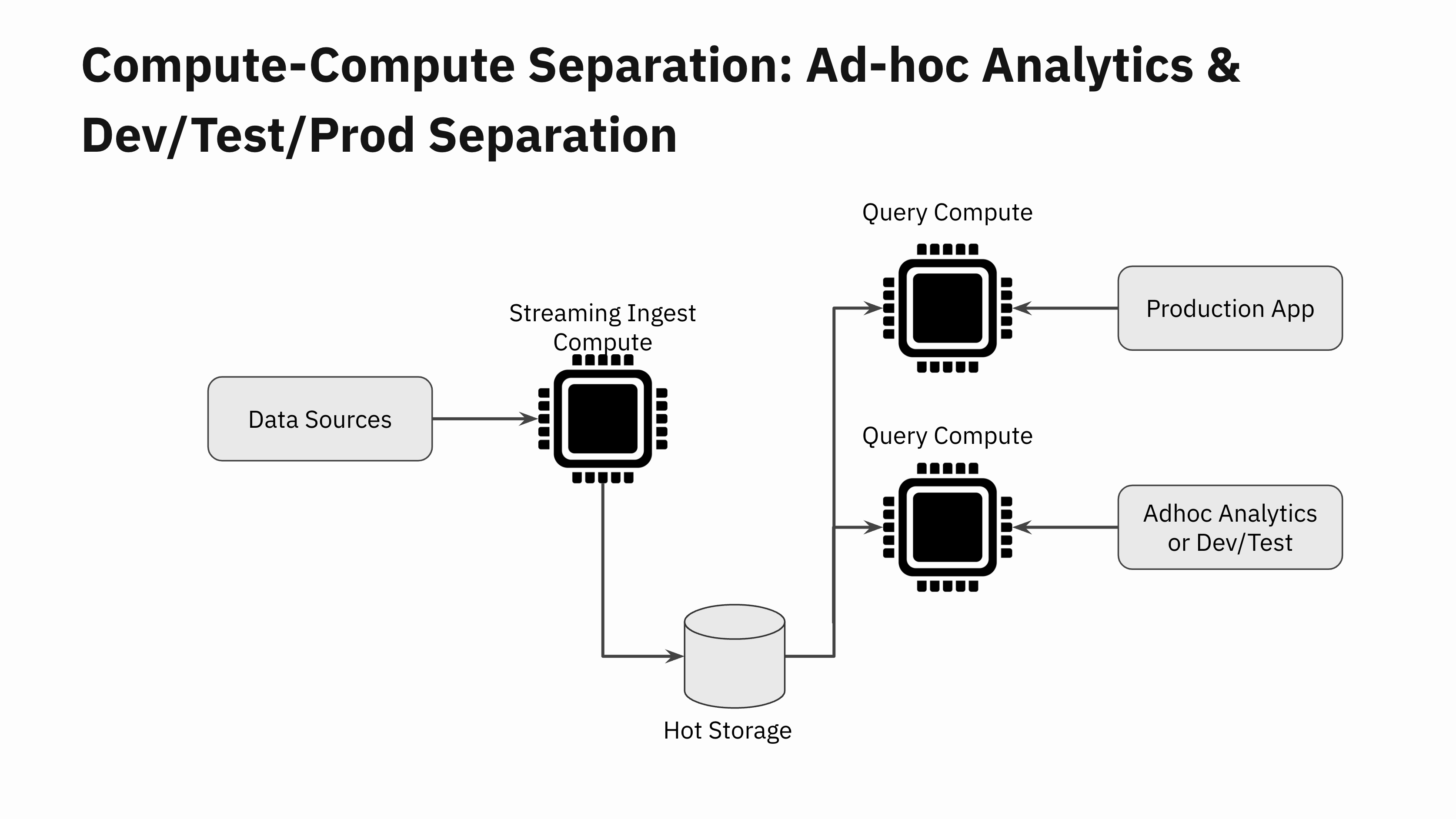
The following time you carry out ad-hoc analytics for reporting or troubleshooting functions in your manufacturing knowledge, you are able to do so with out worrying concerning the unfavorable affect of the queries in your manufacturing software.
Many dev/staging environments can not afford to make a full copy of the manufacturing datasets. In order that they find yourself doing testing on a smaller portion of their manufacturing knowledge. This may trigger surprising efficiency regressions when new software variations are deployed to manufacturing. With compute-compute separation, now you can spin up a brand new Digital Occasion and do a fast efficiency check of the brand new software model earlier than rolling it out to manufacturing.
The chances are limitless for compute-compute separation within the cloud.
Future Implications for Actual-Time Analytics
Ranging from the hackathon challenge a 12 months in the past, it took an excellent workforce of engineers led by Tudor Bosman, Igor Canadi, Karen Li and Wei Li to show the hackathon challenge right into a manufacturing grade system. I’m extraordinarily proud to unveil the potential of compute-compute separation at present to everybody.
That is an absolute sport changer. The implications for the way forward for real-time analytics are large. Anybody can now construct real-time purposes and leverage the cloud to get large effectivity and reliability wins. Constructing large scale real-time purposes don’t must incur exorbitant infrastructure prices resulting from useful resource overprovisioning. Purposes can dynamically and rapidly adapt to altering workloads within the cloud, with the underlying database being operationally trivial to handle.
On this launch weblog, I’ve simply scratched the floor on the brand new cloud structure for compute-compute separation. I’m excited to delve additional into the technical particulars in a discuss with Nathan Bronson, one of many brains behind the memtable replication hack and core contributor to Tao and F14 at Meta. Come be part of us for the tech discuss and look beneath the hood of the brand new structure and get your questions answered!