

{kind=link}

(Anders78/Shutterstock)
The arrival of generative AI has supercharged the world’s urge for food for information, particularly high-quality information of identified provenance. Nonetheless, as massive language fashions (LLMs) get larger, consultants are warning that we could also be working out of information to coach them.
One of many large shifts that occurred with transformer fashions, which have been invented by Google in 2017, is the usage of unsupervised studying. As an alternative of coaching an AI mannequin in a supervised vogue atop smaller quantities of upper high quality, human-curated information, the usage of unsupervised coaching with transformer fashions opened AI as much as the huge quantities of information of variable high quality on the Internet.
As pre-trained LLMs have gotten larger and extra succesful through the years, they’ve required larger and extra elaborate coaching units. As an illustration, when OpenAI launched its unique GPT-1 mannequin in 2018, the mannequin had about 115 million parameters and was educated on BookCorpus, which is a group of about 7,000 unpublished books comprising about 4.5 GB of textual content.
GPT-2, which OpenAI launched in 2019, represented a direct 10x scale-up of GPT-1. The parameter rely expanded to 1.5 billion and the coaching information expanded to about 40GB through the corporate’s use of WebText, a novel coaching set it created based mostly on scraped hyperlinks from Reddit customers. WebText contained about 600 billion phrases and weighed in round 40GB.
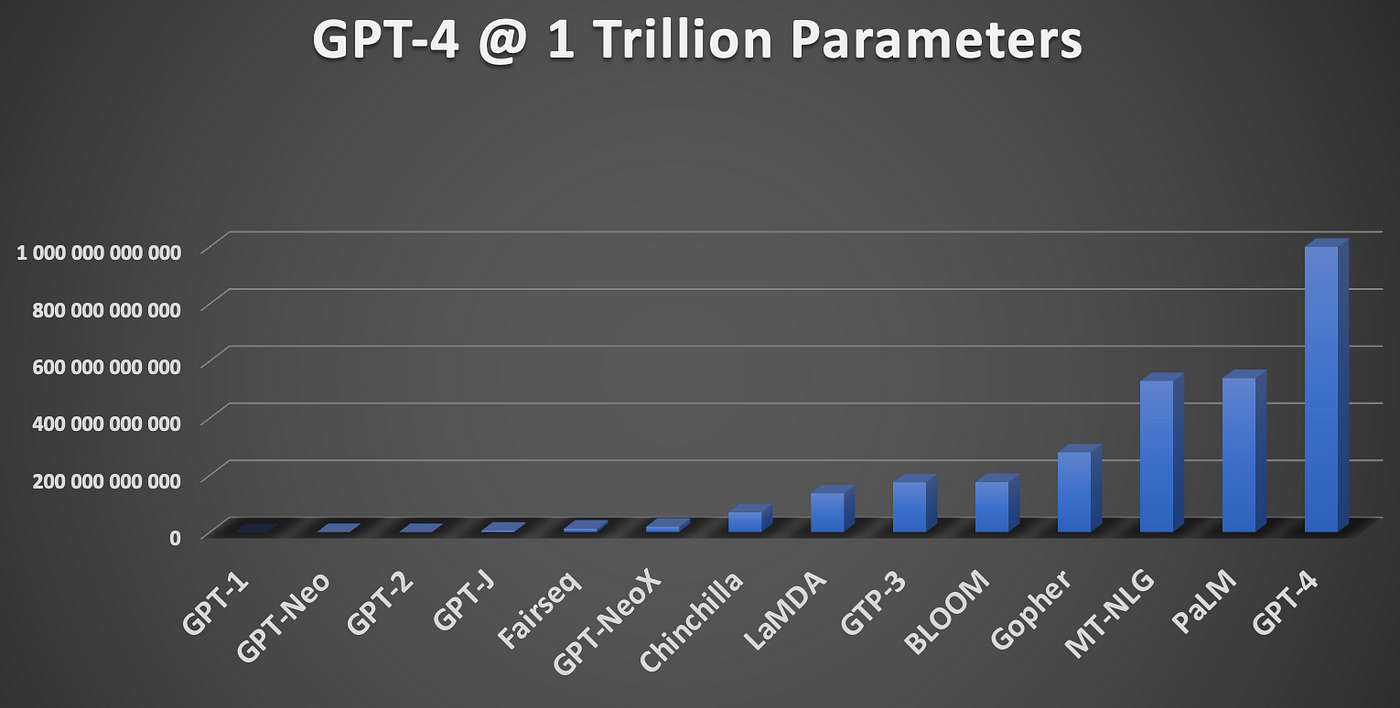
LLM development by variety of parameters (Picture courtesy Corus Greyling, HumanFirst)
With GPT-3, OpenAI expanded its parameter rely to 175 billion. The mannequin, which debuted in 2020, was pre-trained on 570 GB of textual content culled from open sources, together with BookCorpus (Book1 and Book2), Widespread Crawl, Wikipedia, and WebText2. All informed, it amounted to about 499 billion tokens.
Whereas official measurement and coaching set particulars are scant for GPT-4, which OpenAI debuted in 2023, estimates peg the dimensions of the LLM at someplace between 1 trillion and 1.8 trillion, which might make it 5 to 10 occasions larger than GPT-3. The coaching set, in the meantime, has been reported to be 13 trillion tokens (roughly 10 trillion phrases).
Because the AI fashions get larger, the AI mannequin makers have scoured the Internet for brand new sources of information to coach them. Nonetheless, that’s getting tougher, because the creators and collectors of Internet information have more and more imposed restrictions on the usage of information for coaching AI.
Dario Amodei, the CEO of Anthropic, lately estimated there’s a ten% likelihood that we might run out of sufficient information to proceed scaling fashions.
“…[W]e might run out of information,” Amodei informed Dwarkesh Patel in a latest interview. “For numerous causes, I feel that’s not going to occur however in the event you take a look at it very naively we’re not that removed from working out of information.”

We are going to quickly expend all novel human textual content information for LLM coaching, researchers say (Will we run out of information? Limits of LLM scaling based mostly on human-generated information”)
This subject was additionally taken up in a latest paper titled “Will we run out of information? Limits of LLM scaling based mostly on human-generated information,” the place researchers recommend that the present tempo of LLM growth on human-based information will not be sustainable.
At present charges of scaling, an LLM that’s educated on all obtainable human textual content information can be created between 2026 and 2032, they wrote. In different phrases, we might run out of contemporary information that no LLM has seen in lower than two years.
“Nonetheless, after accounting for regular enhancements in information effectivity and the promise of methods like switch studying and artificial information technology, it’s doubtless that we are going to be
in a position to overcome this bottleneck within the availability of public
human textual content information,” the researchers write.
In a brand new paper from the Knowledge Provenance Initiative titled “Consent in Disaster: The Speedy Decline of the AI Knowledge Commons” (pdf), researchers affiliated with the Massachusetts Institute of Expertise analyzed 14,000 web sites to find out to what extent web site operators are making their information “crawlable” by automated information harvesters, akin to these utilized by Widespread Crawl, the most important publicly obtainable crawl of the Web.
Their conclusion: A lot of the info more and more is off-limits to Internet crawlers, both by coverage or technological incompatibility. What’s extra, the phrases of use dictating how web site operators’ enable their information for use more and more don’t mesh with what web sites truly enable by way of their robotic.txt recordsdata, which comprise guidelines that block entry to content material.

Web site operators are placing restrictions on information harvesting (Courtesy “Consent in Disaster: The Speedy Decline of the AI Knowledge Commons”)
“We observe a proliferation of AI-specific clauses to restrict use, acute variations in restrictions on AI builders, in addition to normal inconsistencies between web sites’ expressed intentions of their Phrases of Service and their robots.txt,” the Knowledge Provenance Initiative researchers wrote. “We diagnose these as signs of ineffective net protocols, not designed to deal with the widespread re-purposing of the web for AI.”
Widespread Crawl has been recording the Web since 2007, and as we speak consists of greater than 250 billion Internet pages. The repository is free and open for anybody to make use of, and grows by 3 billion to five billion new pages monthly. Teams like C4, RefinedWeb, and Dolma, which have been analyzed by the MIT researchers, supply cleaned up variations of the info in Widespread Crawl.
The Knowledge Provenance Initiative researchers discovered that, since OpenAI’s ChatGPT exploded onto the scene in late 2022, many web sites have imposed restrictions on crawling for the aim of harvesting information. At present charges, practically 50% of internet sites are projected to have full or partial restrictions by 2025, the researchers conclude. Equally, restrictions have additionally been imposed on web site phrases of service (ToS), with the proportion of internet sites with no restrictions dropping from about 50% in 2023 to about 40% by 2025.
The Knowledge Provenance Initiative researchers discover that crawlers from OpenAI are restricted essentially the most usually, about 26% of the time, adopted by crawlers from Anthropic and Widespread Crawl (about 13%), Google’s AI crawler (about 10%), Cohere (about 5%), and Meta (about 4%).

Patrick Collison interviews OpenAI CEO Sam Altman
The Web was not created to offer information for coaching AI fashions, the researchers write. Whereas bigger web sites are in a position to implement refined consent controls that enable them to show some information units with full provenance whereas retricting others, many smaller web sites operators don’t have the sources to implement such programs, which suggests they’re hiding all of their content material behind paywalls, the researchers write. That stops AI firms from attending to it, nevertheless it additionally prevents that information from getting used for extra legit makes use of, akin to educational analysis, taking us farther from the Web’s open beginnings.
“If we don’t develop higher mechanisms to offer web site house owners management over how their information is used, we should always count on to see additional decreases within the open net,” the Knowledge Provenance Initiative researchers write.
AI giants have lately began to look to different sources for information to coach their fashions, together with enormous collections of movies posted to the Web. As an illustration, a dataset known as YouTube Subtitles, which is a part of bigger, open-source information set created by EleutherAI known as the Pile, is being utilized by firms like Apple, Nvidia, and Anthropic to coach AI fashions.
The transfer has angered some smaller content material creators, who say they by no means agreed to have their copyrighted work used to coach AI fashions and haven’t been compensated as such. What’s extra, they’ve expressed concern that their content material could also be used to coach generative fashions that create content material that competes with their very own content material.
The AI firms are conscious of the looming information dam, however they’ve potentials workarounds already within the works. OpenAI CEO Sam Altman acknowledged the state of affairs in a latest interview with Irish entrepreneur Patrick Collison.
“So long as you may get over the artificial information occasion horizon the place the mannequin is wise sufficient to create artificial information, I feel will probably be alright,” Altman stated. “We do want new methods for positive. I don’t wish to faux in any other case in any means. However the naïve plan of scaling up a transformer with pre-trained tokens from the Web–that may run out. However that’s not the plan.”
Associated Objects:
Are Tech Giants ‘Piling’ On Small Content material Creators to Practice Their AI?