

{kind=link}
On this put up, we present you learn how to implement real-time knowledge ingestion from a number of Kafka matters to Apache Hudi tables utilizing Amazon EMR. This resolution streamlines knowledge ingestion by processing a number of Amazon Managed Streaming for Apache Kafka (Amazon MSK) matters in parallel whereas offering knowledge high quality and scalability by way of change knowledge seize (CDC) and Apache Hudi.
Organizations processing real-time knowledge modifications throughout a number of sources usually wrestle with sustaining knowledge consistency and managing useful resource prices. Conventional batch processing requires reprocessing whole datasets, resulting in excessive useful resource utilization and delayed analytics. By implementing CDC with Apache Hudi’s MultiTable DeltaStreamer, you may obtain real-time updates; environment friendly incremental processing with atomicity, consistency, isolation, sturdiness (ACID) ensures; and seamless schema evolution whereas minimizing storage and compute prices.
Utilizing Amazon Easy Storage Service (Amazon S3), Amazon CloudWatch, Amazon EMR, Amazon MSK and AWS Glue Knowledge Catalog, you’ll construct a production-ready knowledge pipeline that processes modifications from a number of knowledge sources concurrently. By means of this tutorial, you’ll be taught to configure CDC pipelines, handle table-specific configurations, implement 15-minute sync intervals, and preserve your streaming pipeline. The end result is a sturdy system that maintains knowledge consistency whereas enabling real-time analytics and environment friendly useful resource utilization.
What’s CDC?
Think about a consistently evolving knowledge stream, a river of data the place updates move constantly. CDC acts like a complicated web, capturing solely the modifications—the inserts, updates, and deletes—taking place inside that knowledge stream. By means of this focused strategy, you may give attention to the brand new and altered knowledge, considerably enhancing the effectivity of your knowledge pipelines.There are quite a few benefits to embracing CDC:
- Diminished processing time – Why reprocess the whole dataset when you may focus solely on the updates? CDC minimizes processing overhead, saving worthwhile time and assets.
- Actual-time insights – With CDC, your knowledge pipelines change into extra responsive. You’ll be able to react to modifications nearly instantaneously, enabling real-time analytics and decision-making.
- Simplified knowledge pipelines – Conventional batch processing can result in complicated pipelines. CDC streamlines the method, making knowledge pipelines extra manageable and simpler to take care of.
Why Apache Hudi?
Hudi simplifies incremental knowledge processing and knowledge pipeline improvement. This framework effectively manages enterprise necessities akin to knowledge lifecycle and improves knowledge high quality. You should utilize Hudi to handle knowledge on the record-level in Amazon S3 knowledge lakes to simplify CDC and streaming knowledge ingestion and deal with knowledge privateness use instances requiring record-level updates and deletes. Datasets managed by Hudi are saved in Amazon S3 utilizing open storage codecs, whereas integrations with Presto, Apache Hive, Apache Spark, and Knowledge Catalog provide you with close to actual time entry to up to date knowledge. Apache Hudi facilitates incremental knowledge processing for Amazon S3 by:
- Managing record-level modifications – Preferrred for replace and delete use instances
- Open codecs – Integrates with Presto, Hive, Spark, and Knowledge Catalog
- Schema evolution – Helps dynamic schema modifications
- HoodieMultiTableDeltaStreamer – Simplifies ingestion into a number of tables utilizing centralized configurations
Hudi MultiTable Delta Streamer
The HoodieMultiTableStreamer affords a streamlined strategy to knowledge ingestion from a number of sources into Hudi tables. By processing a number of sources concurrently by way of a single DeltaStreamer job, it eliminates the necessity for separate pipelines whereas decreasing operational complexity. The framework gives versatile configuration choices, and you’ll tailor settings for numerous codecs and schemas throughout completely different knowledge sources.
One in all its key strengths lies in unified knowledge supply, organizing info in respective Hudi tables for seamless entry. The system’s clever upsert capabilities effectively deal with each inserts and updates, sustaining knowledge consistency throughout your pipeline. Moreover, its strong schema evolution assist permits your knowledge pipeline to adapt to altering enterprise necessities with out disruption, making it a super resolution for dynamic knowledge environments.
Resolution overview
On this part, we present learn how to stream knowledge to Apache Hudi Desk utilizing Amazon MSK. For this instance state of affairs, there are knowledge streams from three distinct sources residing in separate Kafka matters. We intention to implement a streaming pipeline that makes use of the Hudi DeltaStreamer with multitable assist to ingest and course of this knowledge at 15-minute intervals.
Mechanism
Utilizing MSK Join, knowledge from a number of sources flows into MSK matters. These matters are then ingested into Hudi tables utilizing the Hudi MultiTable DeltaStreamer. On this pattern implementation, we create three Amazon MSK matters and configure the pipeline to course of knowledge in JSON format utilizing JsonKafkaSource, with the pliability to deal with Avro format when wanted by way of the suitable deserializer configuration
The next diagram illustrates how our resolution processes knowledge from a number of supply databases by way of Amazon MSK and Apache Hudi to allow analytics in Amazon Athena. Supply databases ship their knowledge modifications—together with inserts, updates, and deletes—to devoted matters in Amazon MSK, the place every knowledge supply maintains its personal Kafka subject for change occasions. An Amazon EMR cluster runs the Apache Hudi MultiTable DeltaStreamer, which processes these a number of Kafka matters in parallel, remodeling the information and writing it to Apache Hudi tables saved in Amazon S3. Knowledge Catalog maintains the metadata for these tables, enabling seamless integration with analytics instruments. Lastly, Amazon Athena gives SQL question capabilities on the Hudi tables, permitting analysts to run each snapshot and incremental queries on the most recent knowledge. This structure scales horizontally as new knowledge sources are added, with every supply getting its devoted Kafka subject and Hudi desk configuration, whereas sustaining knowledge consistency and ACID ensures throughout the whole pipeline.
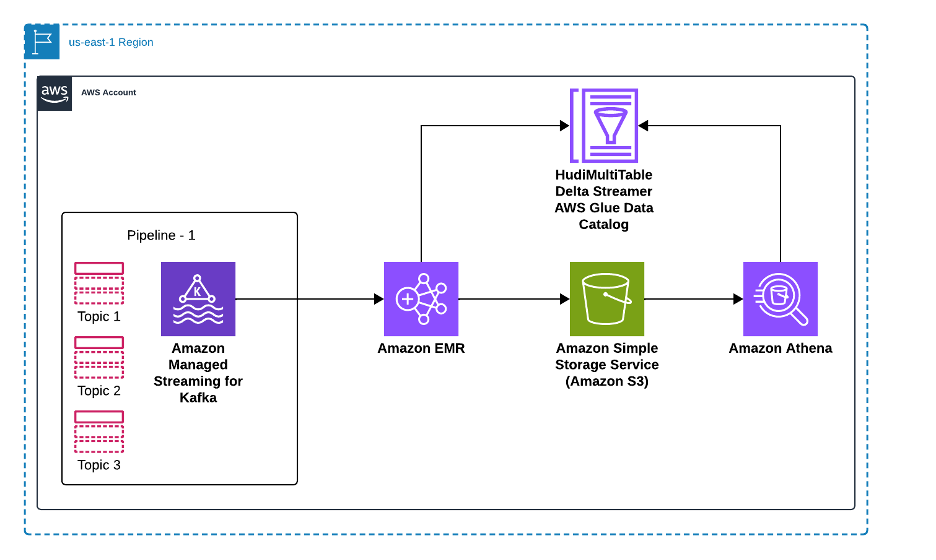
To arrange the answer, you’ll want to full the next high-level steps:
- Arrange Amazon MSK and create Kafka matters
- Create the Kafka matters
- Create table-specific configurations
- Launch Amazon EMR cluster
- Invoke the Hudi MultiTable DeltaStreamer
- Confirm and question knowledge
Stipulations
To carry out the answer, you’ll want to have the next stipulations. For AWS providers and permissions, you want:
- AWS account:
- IAM roles:
- Amazon EMR service function (EMR_DefaultRole) with permissions for Amazon S3, AWS Glue and CloudWatch.
- Amazon EC2 occasion profile (EMR_EC2_DefaultRole) with S3 learn/write entry.
- Amazon MSK entry function with applicable permissions.
- S3 buckets:
- Configuration bucket for storing properties recordsdata and schemas.
- Output bucket for Hudi tables.
- Logging bucket (non-obligatory however really useful).
- Community configuration:
- Improvement instruments:
Arrange Amazon MSK and create Kafka matters
On this step, you’ll create an MSK cluster and configure the required Kafka matters in your knowledge streams.
- To create an MSK cluster:
- Confirm the cluster standing:
aws kafka describe-cluster --cluster-arn $CLUSTER_ARN | jq '.ClusterInfo.State'
The command ought to return ACTIVE when the cluster is prepared.
Schema setup
To arrange the schema, full the next steps:
- Create your schema recordsdata.
input_schema.avsc:output_schema.avsc:
- Create and add schemas to your S3 bucket:
Create the Kafka matters
To create the Kafka matters, full the next steps:
- Get the bootstrap dealer string:
- Create the required matters:
Configure Apache Hudi
The Hudi MultiTable DeltaStreamer configuration is split into two main elements to streamline and standardize knowledge ingestion:
- Widespread configurations – These settings apply throughout all tables and outline the shared properties for ingestion. They embrace particulars akin to shuffle parallelism, Kafka brokers, and customary ingestion configurations for all matters.
- Desk-specific configurations – Every desk has distinctive necessities, such because the report key, schema file paths, and subject names. These configurations tailor every desk’s ingestion course of to its schema and knowledge construction.
Create frequent configuration file
Widespread Config: kafka-hudi config file the place we specify kafka dealer and customary configuration for all matters as under
Create the kafka-hudi-deltastreamer.properties file with the next properties:
Create table-specific configurations
For every subject, create its personal configuration with a subject title and first key particulars. Full the next steps:
cust_sales_details.properties:cust_sales_appointment.properties:cust_info.properties:
These configurations type the spine of Hudi’s ingestion pipeline, enabling environment friendly knowledge dealing with and sustaining real-time consistency. Schema configurations outline the construction of each supply and goal knowledge, sustaining seamless knowledge transformation and ingestion. Operational settings management how knowledge is uniquely recognized, up to date, and processed incrementally.
The next are important particulars for establishing Hudi ingestion pipelines:
hoodie.deltastreamer.schemaprovider.supply.schema.file– The schema of the supply reporthoodie.deltastreamer.schemaprovider.goal.schema.file– The schema for the goal reporthoodie.deltastreamer.supply.kafka.subject– The supply MSK subject titlebootstap.servers– The Amazon MSK bootstrap server’s personal endpointauto.offset.reset– The patron’s conduct when there isn’t a dedicated place or when an offset is out of vary
Key operational fields to realize in-place updates for the generated schema embrace:
hoodie.datasource.write.recordkey.subject– The report key subject. That is the distinctive identifier of a report in Hudi.hoodie.datasource.write.precombine.subject– When two information have the identical report key worth, Apache Hudi picks the one with the most important worth for the pre-combined subject.hoodie.datasource.write.operation– The operation on the Hudi dataset. Attainable values embraceUPSERT,INSERT, andBULK_INSERT.
Launch Amazon EMR cluster
This step creates an EMR cluster with Apache Hudi put in. The cluster will run the MultiTable DeltaStreamer to course of knowledge out of your Kafka matters. To create the EMR cluster, enter the next:
Invoke the Hudi MultiTable DeltaStreamer
This step configures and begins the DeltaStreamer job that can constantly course of knowledge out of your Kafka matters into Hudi tables. Full the next steps:
- Hook up with the Amazon EMR grasp node:
- Execute the DeltaStreamer job:
For steady mode, you’ll want to add the next property:
With the job configured and operating on Amazon EMR, the Hudi MultiTable DeltaStreamer effectively manages real-time knowledge ingestion into your Amazon S3 knowledge lake.
Confirm and question knowledge
To confirm and question the information, full the next steps:
- Register tables in Knowledge Catalog:
- Question with Athena:
You should utilize Amazon CloudWatch alarms to provide you with a warning of points with the EMR job or knowledge processing. To create a CloudWatch alarm to observe EMR job failures, enter the next:
Actual-world affect of Hudi CDC pipelines
With the pipeline configured and operating, you may obtain real-time updates to your knowledge lake, enabling quicker analytics and decision-making. For example:
- Analytics – Up-to-date stock knowledge maintains correct dashboards for ecommerce platforms.
- Monitoring – CloudWatch metrics affirm the pipeline’s well being and effectivity.
- Flexibility – The seamless dealing with of schema evolution minimizes downtime and knowledge inconsistencies.
Cleanup
To keep away from incurring future prices, comply with these steps to scrub up assets:
Conclusion
On this put up, we confirmed how one can construct a scalable knowledge ingestion pipeline utilizing Apache Hudi’s MultiTable DeltaStreamer on Amazon EMR to course of knowledge from a number of Amazon MSK matters. You realized learn how to configure CDC with Apache Hudi, arrange real-time knowledge processing with 15-minute sync intervals, and preserve knowledge consistency throughout a number of sources in your Amazon S3 knowledge lake.
To be taught extra, discover these assets:
By combining CDC with Apache Hudi, you may construct environment friendly, real-time knowledge pipelines. The streamlined ingestion processes simplify administration, improve scalability, and preserve knowledge high quality, making this strategy a cornerstone of recent knowledge architectures.