Massive language fashions are difficult to adapt to new enterprise duties. Prompting is error-prone and achieves restricted high quality beneficial properties, whereas fine-tuning requires giant quantities of human-labeled knowledge that isn’t out there for many enterprise duties. Right this moment, we’re introducing a brand new mannequin tuning technique that requires solely unlabeled utilization knowledge, letting enterprises enhance high quality and value for AI utilizing simply the info they have already got. Our technique, Take a look at-time Adaptive Optimization (TAO), leverages test-time compute (as popularized by o1 and R1) and reinforcement studying (RL) to show a mannequin to do a activity higher primarily based on previous enter examples alone, that means that it scales with an adjustable tuning compute finances, not human labeling effort. Crucially, though TAO makes use of test-time compute, it makes use of it as a part of the method to prepare a mannequin; that mannequin then executes the duty instantly with low inference prices (i.e., not requiring further compute at inference time). Surprisingly, even with out labeled knowledge, TAO can obtain higher mannequin high quality than conventional fine-tuning, and it could possibly carry cheap open supply fashions like Llama to throughout the high quality of expensive proprietary fashions like GPT-4o and o3-mini.
TAO is a part of our analysis group’s program on Knowledge Intelligence — the issue of constructing AI excel at particular domains utilizing the info enterprises have already got. With TAO, we obtain three thrilling outcomes:
On specialised enterprise duties comparable to doc query answering and SQL era, TAO outperforms conventional fine-tuning on 1000’s of labeled examples. It brings environment friendly open supply fashions like Llama 8B and 70B to the same high quality as costly fashions like GPT-4o and o3-mini1 with out the necessity for labels.
We are able to additionally use multi-task TAO to enhance an LLM broadly throughout many duties. Utilizing no labels, TAO improves the efficiency of Llama 3.3 70B by 2.4% on a broad enterprise benchmark.
Growing TAO’s compute finances at tuning time yields higher mannequin high quality with the identical knowledge, whereas the inference prices of the tuned mannequin keep the identical.
Determine 1 exhibits how TAO improves Llama fashions on three enterprise duties: FinanceBench, DB Enterprise Area, and BIRD-SQL (utilizing the Databricks SQL dialect)². Regardless of solely gaining access to LLM inputs, TAO outperforms conventional fine-tuning (FT) with 1000’s of labeled examples and brings Llama throughout the similar vary as costly proprietary fashions.
Determine 1: TAO on Llama 3.1 8B and Llama 3.3 70B throughout three enterprise benchmarks. TAO results in substantial enhancements in high quality, outperforming fine-tuning and difficult costly proprietary LLMs.
TAO is now out there in preview to Databricks clients who wish to tune Llama, and it will likely be powering a number of upcoming merchandise. Fill out this manner to specific your curiosity in making an attempt it in your duties as a part of the personal preview. On this put up, we describe extra about how TAO works and our outcomes with it.
How Does TAO Work? Utilizing Take a look at-Time Compute and Reinforcement Studying to Tune Fashions
As a substitute of requiring human annotated output knowledge, the important thing concept in TAO is to make use of test-time compute to have a mannequin discover believable responses for a activity, then use reinforcement studying to replace an LLM primarily based on evaluating these responses. This pipeline could be scaled utilizing test-time compute, as a substitute of costly human effort, to extend high quality. Furthermore, it could possibly simply be custom-made utilizing task-specific insights (e.g., customized guidelines). Surprisingly, making use of this scaling with high-quality open supply fashions results in higher outcomes than human labels in lots of instances.
Determine 2: The TAO pipeline.
Particularly, TAO contains 4 levels:
Response Technology: This stage begins with amassing instance enter prompts or queries for a activity. On Databricks, these prompts could be robotically collected from any AI utility utilizing our AI Gateway. Every immediate is then used to generate a various set of candidate responses. A wealthy spectrum of era methods could be utilized right here, starting from easy chain-of-thought prompting to classy reasoning and structured prompting methods.
Response Scoring: On this stage, generated responses are systematically evaluated. Scoring methodologies embrace quite a lot of methods, comparable to reward modeling, preference-based scoring, or task-specific verification using LLM judges or customized guidelines. This stage ensures every generated response is quantitatively assessed for high quality and alignment with standards.
Reinforcement Studying (RL) Coaching: Within the remaining stage, an RL-based method is utilized to replace the LLM, guiding the mannequin to supply outputs intently aligned with high-scoring responses recognized within the earlier step. By means of this adaptive studying course of, the mannequin refines its predictions to boost high quality.
Steady Enchancment: The one knowledge TAO wants is instance LLM inputs. Customers naturally create this knowledge by interacting with an LLM. As quickly as your LLM is deployed, you start producing coaching knowledge for the following spherical of TAO. On Databricks, your LLM can get higher the extra you employ it, because of TAO.
Crucially, though TAO makes use of test-time compute, it makes use of it to prepare a mannequin that then executes a activity instantly with low inference prices. Which means the fashions produced by TAO have the identical inference price and pace as the unique mannequin – considerably lower than test-time compute fashions like o1, o3 and R1. As our outcomes present, environment friendly open supply fashions skilled with TAO can problem main proprietary fashions in high quality.
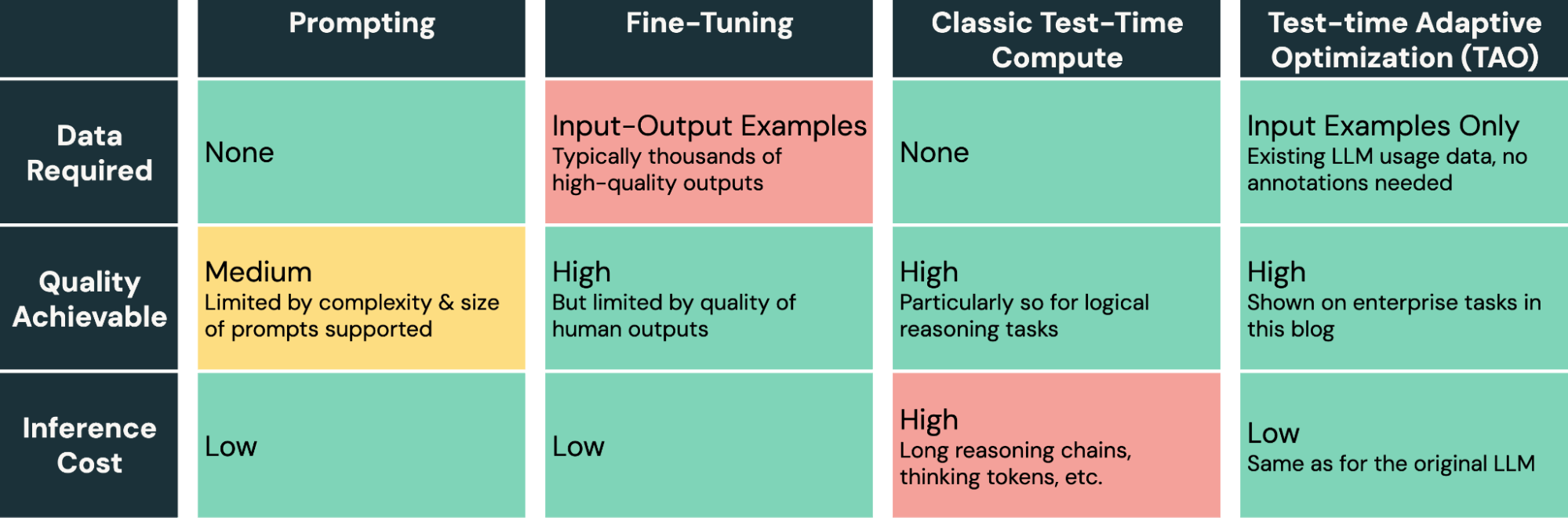
TAO supplies a strong new technique within the toolkit for tuning AI fashions. Not like immediate engineering, which is sluggish and error–inclined, and fine-tuning, which requires producing costly and high-quality human labels, TAO lets AI engineers obtain nice outcomes by merely offering consultant enter examples of their activity.
Desk 1: Comparability of LLM tuning strategies.
TAO is a extremely versatile technique that may be custom-made if wanted, however our default implementation in Databricks works effectively out-of-the-box on various enterprise duties. On the core of our implementation are new reinforcement studying and reward modeling methods our group developed that allow TAO to be taught by exploration after which tune the underlying mannequin utilizing RL. For instance, one of many substances powering TAO is a customized reward mannequin we skilled for enterprise duties, DBRM, that may produce correct scoring alerts throughout a variety of duties.
Bettering Activity Efficiency with TAO
On this part, we dive deeper into how we used TAO to tune LLMs on specialised enterprise duties. We chosen three consultant benchmarks, together with standard open supply benchmarks and inner ones we developed as a part of our Area Intelligence Benchmark Suite (DIBS).
Desk 2: Overview of benchmarks used on this weblog.
For every activity, we evaluated a number of approaches:
Utilizing an open supply Llama mannequin (Llama 3.1-8B or Llama 3.3-70B) out of the field.
Wonderful-tuning on Llama. To do that, we used or created giant, lifelike input-output datasets with 1000’s of examples, which is often what’s required to realize good efficiency with fine-tuning. These included:
7200 artificial questions on SEC paperwork for FinanceBench.
4800 human-written inputs for DB Enterprise Area.
8137 examples from the BIRD-SQL coaching set, modified to match the Databricks SQL dialect.
TAO on Llama, utilizing simply the instance inputs from our fine-tuning datasets, however not the outputs, and utilizing our DBRM enterprise-focused reward mannequin. DBRM itself shouldn’t be skilled on these benchmarks.
Excessive-quality proprietary LLMs – GPT 4o-mini, GPT 4o and o3-mini.
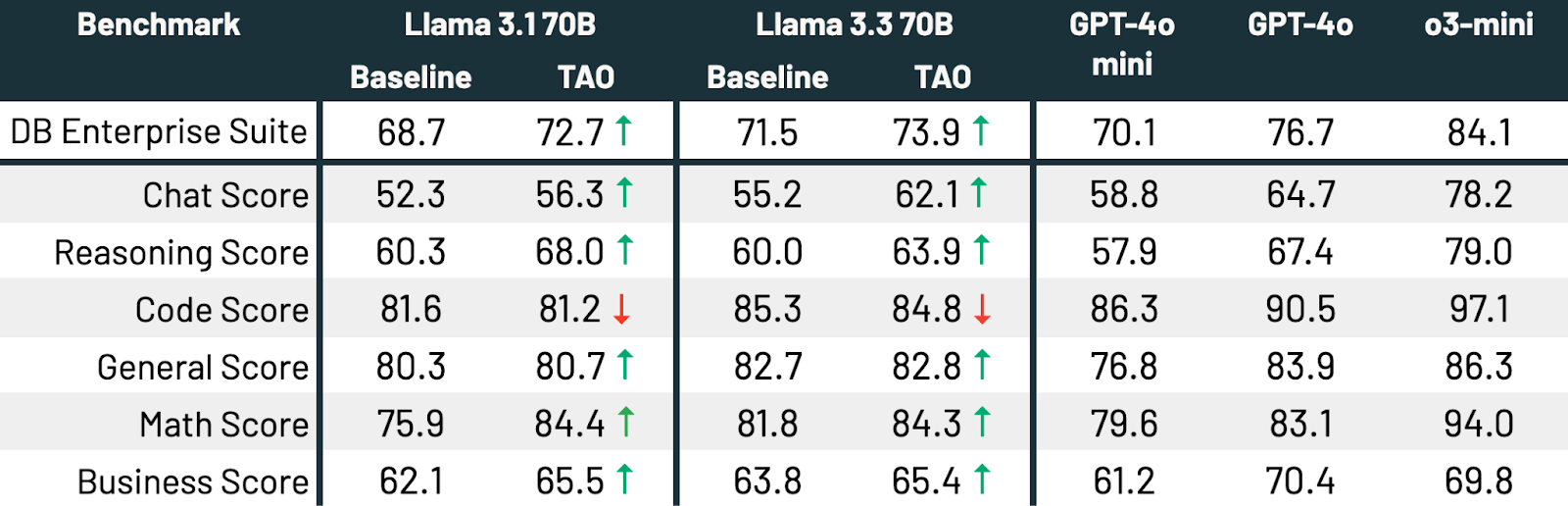
As proven in Desk 3, throughout all three benchmarks and each Llama fashions, TAO considerably improves the baseline Llama efficiency, even past that of fine-tuning.
Desk 3: TAO on Llama 3.1 8B and Llama 3.3 70B throughout three enterprise benchmarks.
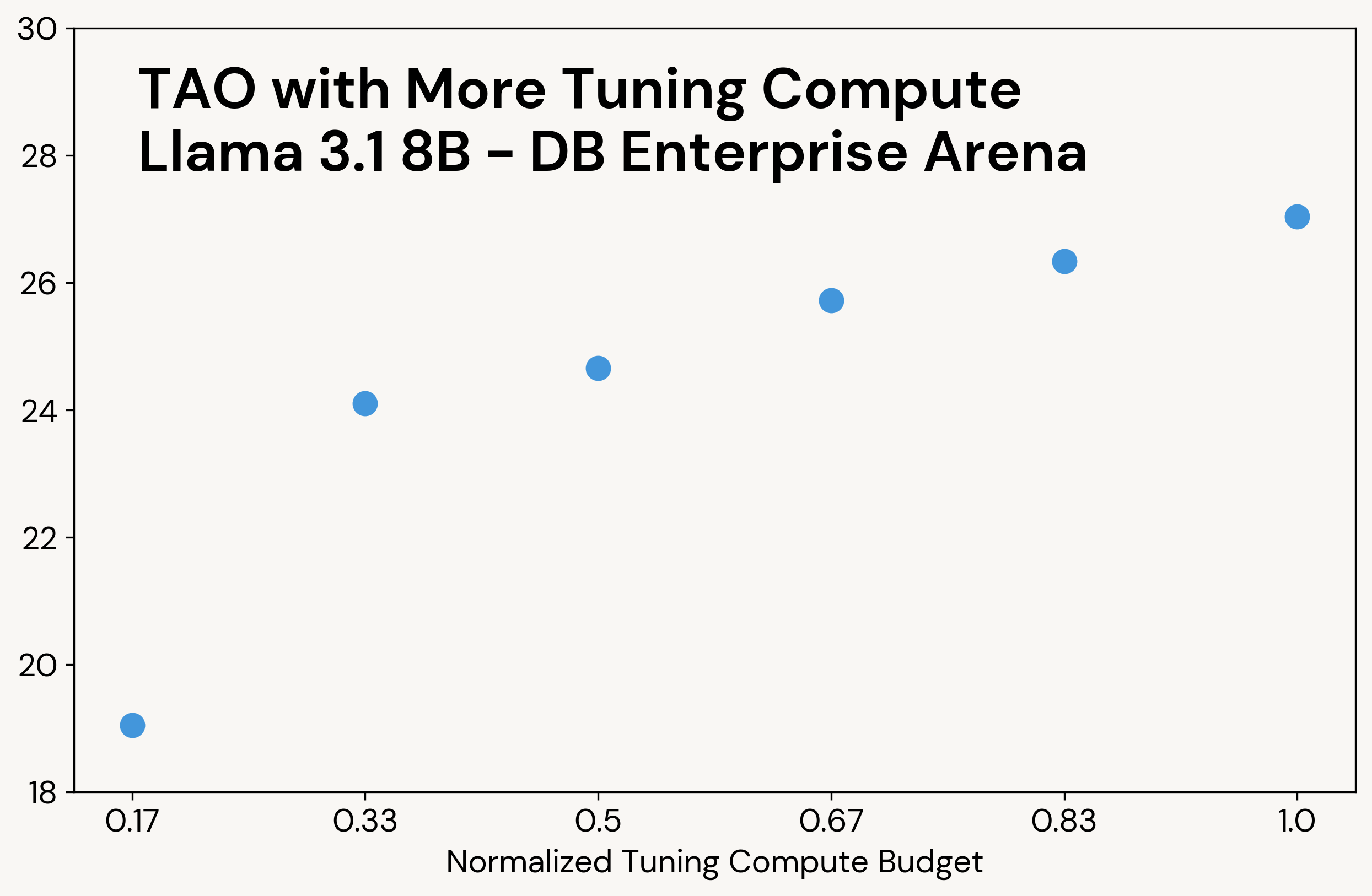
Like basic test-time compute, TAO produces higher-quality outcomes when it’s given entry to extra compute (see Determine 3 for an instance). Not like test-time compute, nonetheless, this extra compute is just used throughout the tuning part; the ultimate LLM has the identical inference price as the unique LLM.
Determine 3: TAO scales with the quantity of test-time compute used throughout the tuning course of. Inference price to make use of the ensuing LLM is similar as the unique LLM.
Bettering Multitask Intelligence with TAO
Up to now, we’ve used TAO to enhance LLMs on particular person slender duties, comparable to SQL era. Nevertheless, as brokers change into extra complicated, enterprises more and more want LLMs that may carry out multiple activity. On this part, we present how TAO can broadly enhance mannequin efficiency throughout a variety of enterprise duties.
On this experiment, we gathered 175,000 prompts that mirror a various set of enterprise duties, together with coding, math, question-answering, doc understanding, and chat. We then ran TAO on Llama 3.1 70B and Llama 3.3 70B. Lastly, we examined a set of enterprise-relevant duties, which incorporates standard LLM benchmarks (e.g. Area Laborious, LiveBench, GPQA Diamond, MMLU Professional, HumanEval, MATH) and inner benchmarks in a number of areas related to enterprises.
TAO meaningfully improves the efficiency of each fashions[t][u]. Llama 3.3 70B and Llama 3.1 70B enhance by 2.4 and 4.0 proportion factors, respectively. TAO brings Llama 3.3 70B considerably nearer to GPT-4o on enterprise duties[v][w]. All of that is achieved with no human labeling price, simply consultant LLM utilization knowledge and our manufacturing implementation of TAO. High quality improves throughout each subscore besides coding, the place efficiency is static.
Desk 4: Bettering multitask enterprise intelligence utilizing TAO
Utilizing TAO in Observe
TAO is a strong tuning technique that works surprisingly effectively on many duties by leveraging test-time compute. To make use of it efficiently by yourself duties, you will want:
Ample instance inputs in your activity (a number of thousand), both collected from a deployed AI utility (e.g., questions despatched to an agent) or generated synthetically.
A sufficiently correct scoring technique: for Databricks clients, one highly effective device right here is our customized reward mannequin, DBRM, that powers our implementation of TAO, however you may increase DBRM with customized scoring guidelines or verifiers if they’re relevant in your activity.
One finest observe that can allow TAO and different mannequin enchancment strategies is to create an information flywheel in your AI functions. As quickly as you deploy an AI utility, you may accumulate inputs, mannequin outputs, and different occasions by providers like Databricks Inference Tables. You possibly can then use simply the inputs to run TAO. The extra individuals use your utility, the extra knowledge you’ll have to tune it on, and – because of TAO – the higher your LLM will get.
Conclusion and Getting Began on Databricks
On this weblog, we introduced Take a look at-time Adaptive Optimization (TAO), a brand new mannequin tuning approach that achieves high-quality outcomes with no need labeled knowledge. We developed TAO to deal with a key problem we noticed enterprise clients going through: they lacked labeled knowledge wanted by normal fine-tuning. TAO makes use of test-time compute and reinforcement studying to enhance fashions utilizing knowledge that enterprises have already got, comparable to enter examples, making it simple to enhance any deployed AI utility in high quality and cut back price through the use of smaller fashions. TAO is a extremely versatile technique that exhibits the facility of test-time compute for specialised AI improvement, and we consider it is going to give builders a strong and easy new device to make use of alongside prompting and fine-tuning.
Databricks clients are already utilizing TAO on Llama in personal preview. Fill out this manner to specific your curiosity in making an attempt it in your duties as a part of the personal preview. TAO can also be being integrated into a lot of our upcoming AI product updates and launches – keep tuned!
¹ Authors: Raj Ammanabrolu, Ashutosh Baheti, Jonathan Chang, Xing Chen, Ta-Chung Chi, Brian Chu, Brandon Cui, Erich Elsen, Jonathan Frankle, Ali Ghodsi, Pallavi Koppol, Sean Kulinski, Jonathan Li, Dipendra Misra, Jose Javier Gonzalez Ortiz, Sean Owen, Mihir Patel, Mansheej Paul, Cory Stephenson, Alex Trott, Ziyi Yang, Matei Zaharia, Andy Zhang, Ivan Zhou
² We use o3-mini-medium all through this weblog. 3 That is the BIRD-SQL benchmark modified for Databricks’ SQL dialect and merchandise.


{kind=link}