

{kind=link}
Covestro Deutschland AG, headquartered in Leverkusen, Germany, is a world chief in high-performance polymer supplies and parts. Covestro has established itself as a key participant within the chemical trade, with 48 manufacturing websites worldwide, €14.2 billion 2024 gross sales, and 17,500 staff. Covestro’s core enterprise focuses on creating revolutionary, sustainable options for merchandise utilized in varied features of every day life. The corporate provides supplies for mobility, constructing and dwelling, electrical and electronics sectors, along with sports activities and leisure, well being, and the chemical trade. The corporate’s merchandise, resembling polycarbonates, polyurethanes, coatings, adhesives, and specialty elastomers, are necessary parts in automotive, development, electronics, and medical gadget industries.
To help this international operation and various product portfolio, Covestro adopted a sturdy information administration resolution. On this publish, we present you ways Covestro reworked its information structure by implementing Amazon DataZone and AWS Serverless Knowledge Lake Framework (SDLF), transitioning from a centralized information lake to an information mesh structure. By way of this strategic shift, groups can share and eat information whereas sustaining prime quality requirements by way of a consolidated information market and enterprise metadata glossary. The end result: streamlined information entry, higher information high quality, and stronger governance at scale that varied producer and shopper groups can use to run information and analytics workloads at scale, enabling over 1,000 information pipelines and attaining a 70% discount in time-to-market.
Enterprise and information challenges
Previous to their transformation, Covestro operated with a centralized information lake managed by a single information platform group that dealt with the information engineering duties. This centralized method created a number of challenges: bottlenecks in venture supply due to restricted engineering assets, sophisticated prioritization of use instances, and inefficient information sharing processes. The setup typically resulted in pointless information duplication, which in flip slowed down time-to-market for brand new analytics initiatives, elevated prices, and restricted the flexibility of enterprise items to behave rapidly on insights.The shortage of visibility into information property created vital operational challenges:
- Groups couldn’t discover current datasets, typically recreating information already saved elsewhere
- No clear understanding of information lineage or high quality metrics
- Issue in figuring out who owned particular information property or who to contact for entry
- Absence of metadata and documentation about obtainable datasets
- Departments shared little data about how they have been utilizing information
These visibility points, mixed with the dearth of unified entry controls, led to:
- Siloed information initiatives throughout departments
- Decreased belief in information high quality
- Inefficient use of assets
- Delayed venture timelines
- Missed alternatives for cross-functional collaboration and insights
A strategic resolution: Why Amazon DataZone and SDLF?
The challenges Covestro confronted mirror deeper structural limitations of centralized information architectures. As Covestro scaled, central information groups typically turned bottlenecks, and lack of area context led to fragmented high quality, inconsistent requirements, and poor collaboration. As an alternative of centralizing management, a information mesh offers possession to the groups who generate and perceive the information, whereas maintaining the governance and interoperability constant throughout the group. This makes it well-suited for Covestro’s atmosphere, which requires agility, scalability, and cross-team collaboration.
AWS Serverless Knowledge Lake Framework (SDLF) is an answer to those challenges, offering a sturdy basis for information mesh architectures. Conventional information lake implementations typically centralize information possession and governance, however with the versatile design of SDLF, organizations can construct decentralized information domains that align with fashionable information mesh rules. The framework supplies domain-oriented groups with the infrastructure, safety controls, and operational patterns wanted to personal and handle their information merchandise independently, whereas sustaining constant governance throughout the group. By way of its modular structure and infrastructure as code templates, SDLF accelerates the creation of domain-specific information merchandise, in order that Covestro’s groups can deploy standardized but customizable information pipelines. This method helps the important thing pillars of information mesh: domain-oriented decentralization, information as a product, self-serve infrastructure, and federated governance, offering Covestro with a sensible path to beat the constraints of conventional centralized architectures.
Amazon DataZone enhances the information mesh implementation by way of a unified expertise for locating and accessing information throughout decentralized domains. As an information administration service, Amazon DataZone helps organizations catalog, uncover, share, and govern information throughout organizational boundaries. It supplies a central governance layer the place organizations can set up information sharing agreements, handle entry controls, and allow self-service information entry whereas supporting safety and compliance. Whereas groups can use the SDLF framework to construct and function domain-specific information merchandise, Amazon DataZone enhances it with a searchable catalog enriched with metadata, enterprise context, and utilization insurance policies, making information merchandise simpler to search out, belief, and reuse.
By way of the sharing capabilities of Amazon DataZone, area groups can share their information merchandise with different domains whereas sustaining granular entry controls and governance insurance policies, enabling cross-domain collaboration and information reuse. This integration implies that area groups can publish their SDLF-managed datasets to an Amazon DataZone catalog, so licensed shoppers throughout the group can uncover and entry them. By way of the built-in governance capabilities constructed into Amazon DataZone, organizations can implement standardized information sharing workflows, test information high quality, and implement constant entry controls throughout their distributed information system, strengthening their information mesh structure with sturdy information governance and democratization capabilities.Collectively, SDLF and Amazon DataZone present Covestro with a complete resolution for implementing a contemporary information mesh structure, enabling autonomous information domains to function with constant governance, seamless information sharing, and enterprise-wide information discovery.
Resolution structure and implementation
The next structure illustrates the high-level design of the information mesh resolution. The implementation used a complete AWS resolution constructed on AWS companies to create a sturdy, scalable, and ruled information mesh that serves a number of enterprise domains throughout the Covestro group.
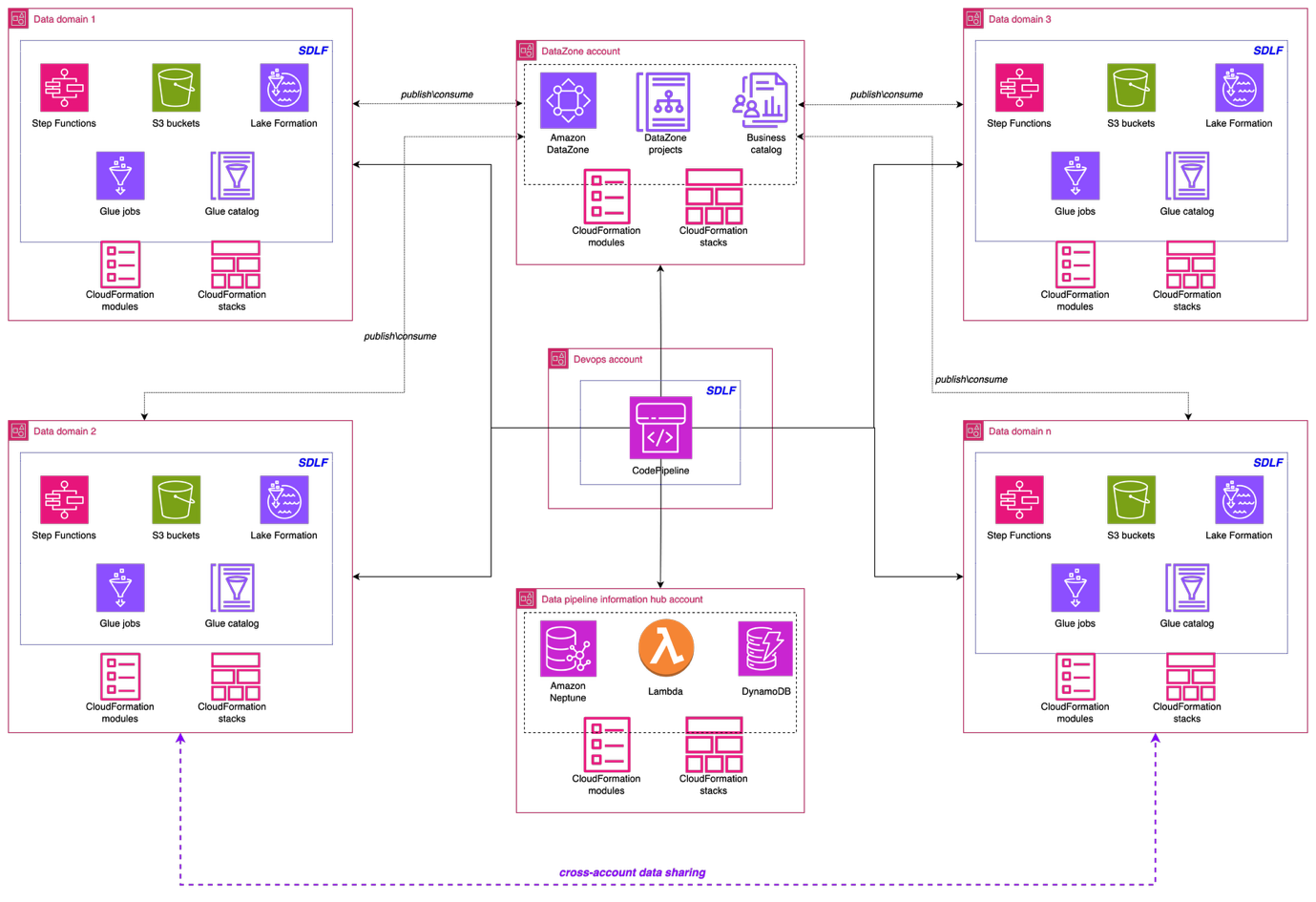
Knowledge area basis: Serverless Knowledge Lake Framework
A key pillar of the implementation is the Serverless Knowledge Lake Framework (SDLF), which supplies the foundational infrastructure and safety wanted to help information mesh methods. SDLF delivers the core constructing blocks for information domains resembling Amazon S3 storage layers, built-in encryption with AWS KMS, IAM-based entry management, and infrastructure as code (IaC) automation. By utilizing these parts, Covestro can deploy decentralized, domain-owned information merchandise quickly whereas sustaining constant governance throughout the enterprise.
The framework makes use of Amazon Easy Storage Service (Amazon S3) as the first information storage layer, delivering nearly limitless scalability and eleven nines of sturdiness for various information property. The proposed S3 bucket structure follows AWS Properly-Architected rules, implementing a multi-tiered construction with distinct uncooked, staging, and analytics information zones. This layered method helps completely different enterprise domains to take care of information sovereignty (every area owns and controls its information, whereas maintaining accessibility patterns organization-wide).
Safety is a elementary facet in Covestro’s information mesh implementation. SDLF routinely implements encryption at relaxation and in transit throughout information storage and processing parts. AWS Key Administration Service (AWS KMS) supplies centralized key administration, whereas rigorously crafted AWS Identification and Entry Administration (IAM) roles allow useful resource isolation.
Knowledge processing with AWS Glue
AWS Glue serves because the cornerstone of the information processing and transformation capabilities, providing serverless extract, remodel, and cargo ETL companies that routinely scale primarily based on workload calls for.
Covestro’s pre-existent centralized information lake was fed by greater than 1,000 ingestion information pipelines interacting with quite a lot of supply methods. To help the migration of current ingestion and processing pipelines, Covestro developed reusable blueprints that included the event and safety requirements outlined for the information mesh.Covestro launched standardized patterns that groups can deploy throughout a number of domains whereas offering the flexibleness wanted for domain-specific necessities. These blueprints help various supply methods, from conventional databases like Oracle, SQL Server, and MySQL to fashionable software program as a service (SaaS) purposes resembling SAP C4C.
In addition they developed specialised blueprints for processing, standardizing, and cleansing ingested uncooked information. These blueprints retailer processed information in Apache Iceberg format, routinely saving metadata within the AWS Glue Knowledge Catalog and offering built-in capabilities to deal with schema evolution seamlessly.
Covestro depends on SDLF to rapidly configure and deploy the blueprints as AWS Glue jobs contained in the area. With SDLF, groups deploy an information pipeline by way of a YAML configuration file, and the orchestration and administration mechanisms of SDLF deal with the remainder. The answer contains complete monitoring capabilities constructed on Amazon DynamoDB, offering real-time visibility into information pipeline well being and efficiency metrics (when groups deploy a pipeline by way of SDLF, the system routinely integrates it with the monitoring setup).
Knowledge high quality with AWS Glue Knowledge High quality
To attain information reliability throughout domains, Covestro prolonged the capabilities of SDLF to include AWS Glue Knowledge High quality into information processing pipelines. This integration permits automated information high quality checks as a part of the usual information processing workflow. Due to the configuration-driven design of SDLF, information producers can implement qc both utilizing beneficial guidelines, that are routinely generated by way of information profiling, or making use of their very own domain-specific guidelines.
The combination supplies information groups with the flexibleness to outline high quality expectations whereas sustaining consistency in how high quality checks are carried out on the pipeline stage. The answer logs high quality analysis outcomes, offering visibility into the information high quality metrics for every information product. These components are illustrated within the following determine.
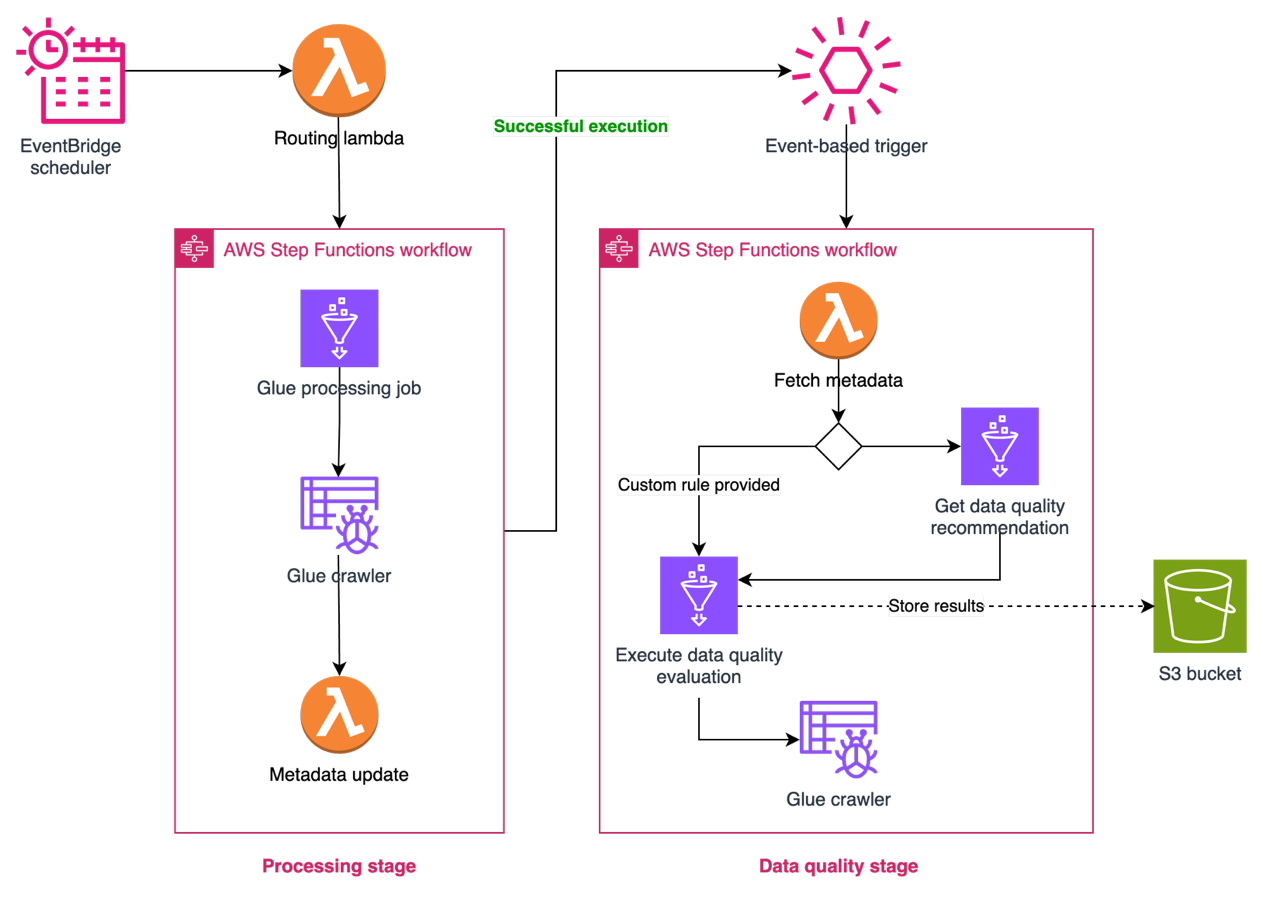
Enterprise-ready entry management with AWS Lake Formation
AWS Lake Formation integration with the Knowledge Catalog helps the safety and entry management layer that makes the information mesh implementation enterprise-ready. By way of Lake Formation, Covestro carried out fine-grained entry controls that respect area boundaries whereas enabling managed cross-domain information sharing.
The service’s integration with IAM implies that Covestro can implement role-based entry patterns that align with their organizational construction, so customers can entry the information they want whereas maintaining acceptable safety boundaries.
Knowledge democratization with Amazon DataZone
Amazon DataZone features as the guts of the information mesh implementation. Deployed in a devoted AWS account, it supplies the information governance, discovery, and sharing capabilities that have been lacking within the earlier centralized method. DataZone provides a unified, searchable catalog enriched with enterprise context, automated entry controls, and standardized sharing workflows that allow true information democratization throughout the group.
By way of Amazon DataZone, Covestro established a complete information catalog that helps enterprise customers throughout completely different domains to find, perceive, and request entry to information property with out requiring deep technical experience. The enterprise glossary performance helps constant information definitions throughout domains, eliminating the confusion that usually arises when completely different groups use completely different terminology for a similar ideas.
Knowledge product house owners can use the mixing of Amazon DataZone integration with AWS Lake Formation to grant or revoke cross-domain entry to information, streamlining the information sharing course of whereas supporting safety and compliance necessities.
Managing cross-domain information pipeline dependencies
When implementing Covestro’s information mesh structure on AWS, one of the vital challenges was orchestrating information pipelines throughout a number of domains. The core query to handle was “How can Knowledge Area A decide when a required dataset from Knowledge Area B has been refreshed and is prepared for consumption?”.
In an information mesh structure, domains preserve possession of their information merchandise whereas enabling consumption by different domains. This distributed mannequin creates advanced dependency chains the place downstream pipelines should look ahead to upstream information merchandise to finish processing earlier than execution can start.
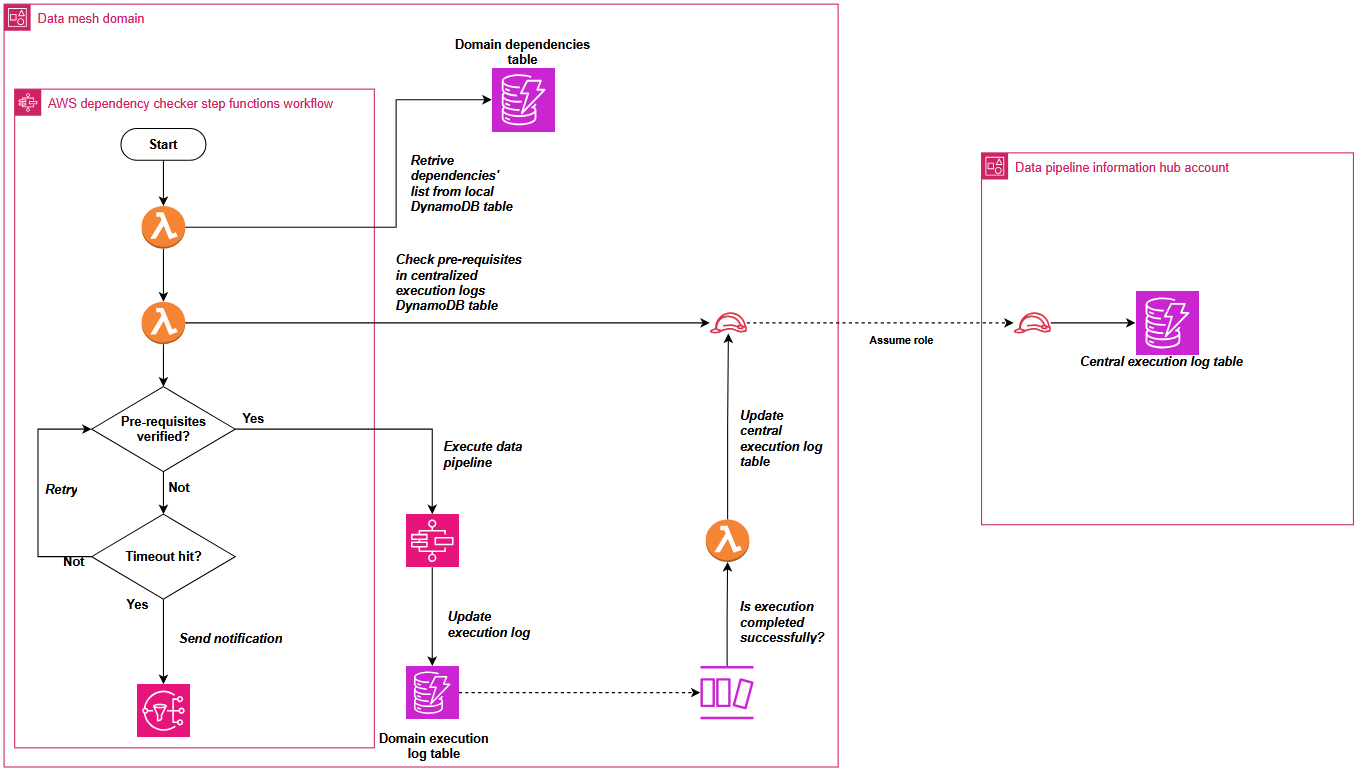
To deal with this cross-domain dependency coordination, Covestro prolonged the SDLF with a customized dependency checker part that operates by way of each shared and domain-specific components.
The shared parts include two centralized Amazon DynamoDB tables positioned in a hub AWS account: one amassing profitable pipeline execution logs from the domains, and one other aggregating pipeline dependencies throughout the complete information mesh.
These domains deploy native parts resembling a dependency-tracking Amazon DynamoDB desk and an AWS Step Features state machine. The state machine checks stipulations utilizing centralized execution logs and integrates seamlessly as step one in each SDLF-deployed pipeline, with out further configuration. The next diagram exhibits the method described.
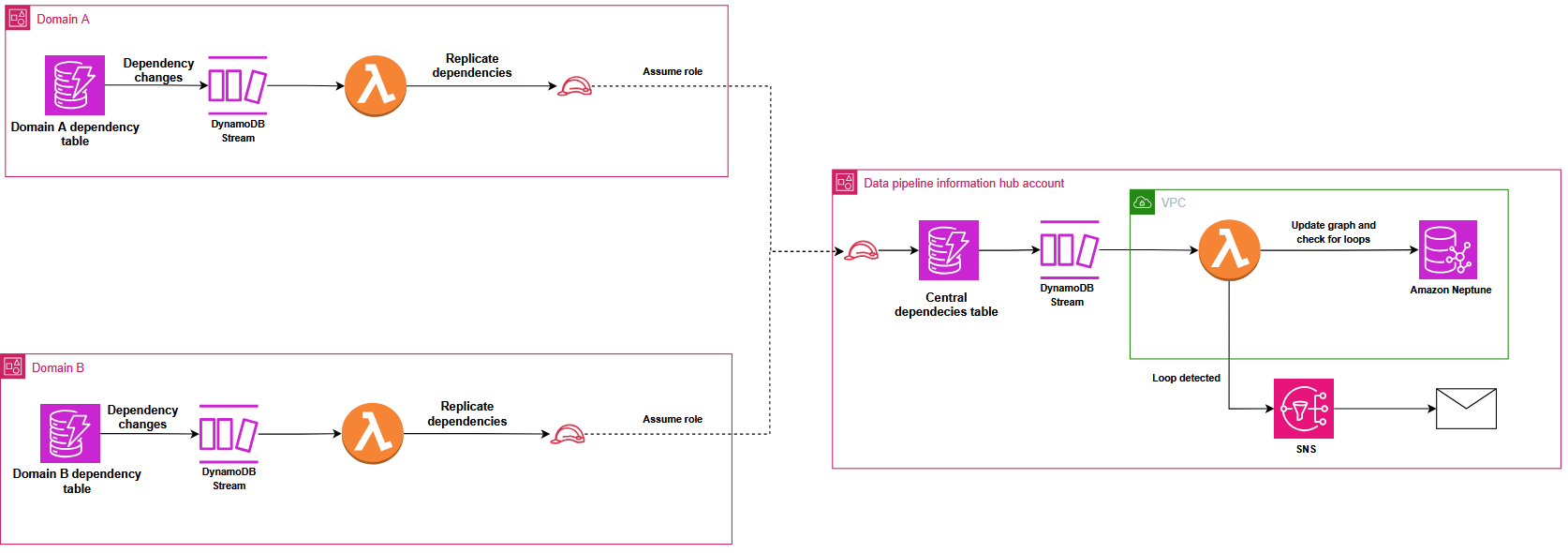
To stop round dependencies that might create locks within the distributed orchestration system, Covestro carried out a classy detection mechanism utilizing Amazon Neptune. DynamoDB Streams routinely replicate dependency adjustments from area tables to the central registry, triggering an AWS Lambda operate that makes use of the Gremlin graph traversal language (utilizing pygremlin) to assemble, replace, and analyze a directed acyclic graph (DAG) of the pipeline relationships, with native Gremlin features detecting round dependencies and sending automated notifications, as illustrated within the following diagram. This course of constantly updates the graph to mirror any new pipeline dependencies or adjustments throughout the information mesh.
Operational excellence by way of infrastructure as code
Infrastructure as code (IaC) practices utilizing AWS CloudFormation and the AWS Cloud Growth Package (AWS CDK) considerably enhance the operational effectivity of the information mesh implementation. The infrastructure code is version-controlled in GitHub repositories, offering full traceability and collaboration capabilities for information engineering groups. This method makes use of a devoted deployment account that makes use of AWS CodePipeline to orchestrate constant deployments throughout a number of information mesh domains.
The centralized deployment mannequin helps that infrastructure adjustments comply with a standardized steady integration and deployment (CI/CD) course of, the place code commits set off automated pipelines that validate, check, and deploy infrastructure parts to the suitable area accounts. Every information area resides in its personal separate set of AWS accounts (dev, qa, prod), and the centralized deployment pipeline respects these boundaries whereas enabling managed infrastructure provisioning.
IaC permits the information mesh to scale horizontally when onboarding new domains, supporting the upkeep of constant safety, governance, and operational requirements throughout the complete atmosphere. Covestro provisions new domains rapidly utilizing confirmed templates, accelerating time-to-value for enterprise groups.
Enterprise affect and technical outcomes
The implementation of the information mesh structure utilizing Amazon DataZone and SDLF has delivered vital measurable advantages throughout Covestro’s group:
Accelerated information pipeline improvement
- 70% discount in time-to-market for brand new information merchandise by way of standardized blueprints
- Profitable migration of greater than 1,000 information pipelines to the brand new structure
- Automated pipeline creation with out guide coding necessities
- Standardized method and sharing throughout domains
Enhanced information governance and high quality
- Complete enterprise glossary implementation that helps constant terminology
- Automated information high quality checks built-in into pipelines
- Finish-to-end information lineage visibility throughout domains
- Standardized metadata administration by way of Apache Iceberg integration
Improved information discovery and entry
- Self-service information discovery portal by way of Amazon DataZone
- Streamlined cross-domain information sharing with acceptable safety controls
- Decreased information duplication by way of improved visibility of current property
- Environment friendly administration of cross-domain pipeline dependencies
Operational effectivity
- Decreased central information group bottlenecks by way of domain-oriented possession
- Decreased operational overhead by way of automated deployment processes
- Improved useful resource utilization by way of elimination of redundant information processing
- Enhanced monitoring and troubleshooting capabilities
The brand new infrastructure has essentially reworked how Covestro’s groups work together with information, enabling enterprise domains to function autonomously whereas upholding enterprise-wide requirements for high quality and governance. This has created a extra agile, environment friendly, and collaborative information ecosystem that helps each present wants and future development.
What’s subsequent
As Covestro’s information platform continues to evolve, the main focus is now to help area groups to successfully constructed information merchandise for cross area analytics. In parallel, Covestro is actively working to enhance information transparency with information lineage in Amazon DataZone by way of OpenLineage to help extra complete information traceability throughout a various set of processing instruments and codecs.
Conclusion
On this publish, we confirmed you ways Covestro reworked its information structure transitioning from a centralized information lake to an information mesh structure, and the way this basis will show invaluable in supporting their journey towards changing into a extra data-driven group. Their expertise demonstrates how fashionable information architectures, when correctly carried out with the correct instruments and frameworks, can remodel enterprise operations and unlock new alternatives for innovation.
This implementation serves as a blueprint for different enterprises trying to modernize their information infrastructure whereas sustaining safety, governance, and scalability. It exhibits that with cautious planning and the correct expertise selections, organizations can efficiently transition from centralized to distributed information architectures with out compromising on management or high quality.
For extra on Amazon DataZone, see the Getting Began information. To be taught concerning the SDLF, see Deploy and handle a serverless information lake on the AWS Cloud through the use of infrastructure as code.