

{kind=link}
Organizations in the present day handle huge quantities of information, with a lot of it saved based mostly on preliminary use circumstances and enterprise wants. As necessities for this knowledge evolve—whether or not for real-time reporting, superior machine studying (ML), or cross-team knowledge sharing—the unique storage codecs and buildings typically develop into a bottleneck. When this occurs, knowledge groups ceaselessly discover that datasets that labored nicely for his or her authentic function now require advanced transformations; customized extract, rework, and cargo (ETL) pipelines; and in depth redesign to unblock new analytical workflows. This creates a major barrier between useful knowledge and actionable insights.
Amazon Athena gives an answer by means of its serverless, SQL-based method to knowledge transformation. With the CREATE TABLE AS SELECT (CTAS) performance in Athena, you possibly can rework present knowledge and create new tables within the course of, utilizing commonplace SQL statements to assist scale back the necessity for customized ETL pipeline growth.
This CTAS expertise now helps Amazon S3 Tables, which offer built-in optimization, Apache Iceberg assist, computerized desk upkeep, and ACID transaction capabilities. This mix may also help organizations modernize their knowledge infrastructure, obtain improved efficiency, and scale back operational overhead.
You need to use this method to remodel knowledge from generally used tabular codecs, together with CSV, TSV, JSON, Avro, Parquet, and ORC. The ensuing tables are instantly accessible for querying throughout Athena, Amazon Redshift, Amazon EMR, and supported third-party purposes, together with Apache Spark, Trino, DuckDB, and PyIceberg.
This put up demonstrates how Athena CTAS simplifies the info transformation course of by means of a sensible instance: migrating an present Parquet dataset into S3 Tables.
Resolution overview
Contemplate a world attire ecommerce retailer processing 1000’s of each day buyer evaluations throughout marketplaces. Their dataset, at the moment saved in Parquet format in Amazon Easy Storage Service (Amazon S3), requires updates every time prospects modify scores and evaluation content material. The enterprise wants an answer that helps ACID transactions—the power to atomically insert, replace, and delete information whereas sustaining knowledge consistency—as a result of evaluation knowledge modifications ceaselessly as prospects edit their suggestions.
Moreover, the info group faces operational challenges: guide desk upkeep duties like compaction and metadata administration, no built-in assist for time journey queries to investigate historic modifications, and the necessity for customized processes to deal with concurrent knowledge modifications safely.
These necessities level to a necessity for an analytics-friendly answer that may deal with transactional workloads whereas offering automated desk upkeep, lowering the operational overhead that at the moment burdens their analysts and engineers.
S3 Tables and Athena present a great answer for these necessities. S3 Tables present storage optimized for analytics workloads, providing Iceberg assist with computerized desk upkeep and steady optimization. Athena is a serverless, interactive question service you need to use to investigate knowledge utilizing commonplace SQL with out managing infrastructure. When mixed, S3 Tables deal with the storage optimization and upkeep mechanically, and Athena gives the SQL interface for knowledge transformation and querying. This may also help scale back the operational overhead of guide desk upkeep whereas offering environment friendly knowledge administration and optimum efficiency throughout supported knowledge processing and question engines.
Within the following sections, we present methods to use the CTAS performance in Athena to remodel the Parquet-formatted evaluation knowledge into S3 Tables with a single SQL assertion. We then reveal methods to handle dynamic knowledge utilizing INSERT, UPDATE, and DELETE operations, showcasing the ACID transaction capabilities and metadata question options in S3 Tables.
Conditions
On this walkthrough, we can be working with artificial buyer evaluation knowledge that we’ve made publicly accessible at s3://aws-bigdata-blog/generated_synthetic_reviews/knowledge/. To observe alongside, you have to have the next conditions:
- AWS account setup:
- An IAM consumer or position with the next permissions:
AmazonAthenaFullAccessmanaged coverage- S3 Tables permissions for creating and managing desk buckets
- S3 Tables permissions for creating and managing tables inside buckets
- Learn entry to the general public dataset location:
s3://aws-bigdata-blog/generated_synthetic_reviews/knowledge/
You’ll create an S3 desk bucket named athena-ctas-s3table-demo as a part of this walkthrough. Ensure this title is out there in your chosen AWS Area.
Arrange a database and tables in Athena
Let’s begin by making a database and supply desk to carry our Parquet knowledge. This desk will function the info supply for our CTAS operation.
Navigate to the Athena question editor to run the next queries:
As a result of the info is partitioned by product class, you have to add the partition info to the desk metadata utilizing MSCK REPAIR TABLE:
The preview question ought to return pattern evaluation knowledge, confirming the desk is prepared for transformation:
Create a desk bucket
Desk buckets are designed to retailer tabular knowledge and metadata as objects for analytics workloads. Observe these steps to create a desk bucket:
- Check in to the console in your most popular Area and open the Amazon S3 console.
- Within the navigation pane, select Desk buckets.
- Select Create desk bucket.
- For Desk bucket title, enter
athena-ctas-s3table-demo. - Choose Allow integration for Integration with AWS analytics companies if not already enabled.
- Depart the encryption choice to default.
- Select Create desk bucket.
Now you can see athena-ctas-s3table-demo listed underneath Desk buckets.
Create a namespace
Namespaces present logical group for tables inside your S3 desk bucket, facilitating scalable desk administration. On this step, we create a reviews_namespace to prepare our buyer evaluation tables. Observe these steps to create the desk namespace:
- Within the navigation pane underneath Desk buckets, select your newly created bucket
athena-ctas-s3table-demo. - On the bucket particulars web page, select Create desk with Athena.
- Select Create a namespace for Namespace configuration.
- Enter
reviews_namespacefor Namespace title. - Select Create namespace.
- Select Create desk with Athena to navigate to the Athena question editor.
You must now see your S3 Tables configuration mechanically chosen underneath Knowledge, as proven within the following screenshot.

Once you allow Integration with AWS analytics companies, when creating an S3 desk bucket, AWS Glue creates a brand new catalog known as s3tablescatalog in your account’s default Knowledge Catalog particular to your Area. The mixing maps the S3 desk bucket assets in your account and Area on this catalog.
This configuration makes positive subsequent queries will goal your S3 Tables namespace. You’re now able to create tables utilizing the CTAS performance.
Create a brand new S3 desk utilizing the customer_reviews desk
A desk represents a structured dataset consisting of underlying desk knowledge and associated metadata saved within the Iceberg desk format. Within the following steps, we rework the customer_reviews desk that we created earlier on the Parquet dataset into an S3 desk utilizing the Athena CTAS assertion. We partition by date utilizing the day() partition transforms from Iceberg.
Run the next CTAS question:
This question creates as S3 desk with the next optimizations:
- Parquet format – Environment friendly columnar storage for analytics
- Day-level partitioning – Makes use of Iceberg’s
day()rework onreview_datefor quick queries when filtering on dates - Filtered knowledge – Consists of solely evaluations from 2016 onwards to reveal selective transformation
You could have efficiently reworked your Parquet dataset to S3 Tables utilizing a single CTAS assertion.
After you create the desk, customer_reviews_s3table will seem underneath Tables within the Athena console. You can too view the desk on the Amazon S3 console by selecting the choices menu (three vertical dots) subsequent to the desk title and selecting View in S3.
Run a preview question to verify the info transformation:
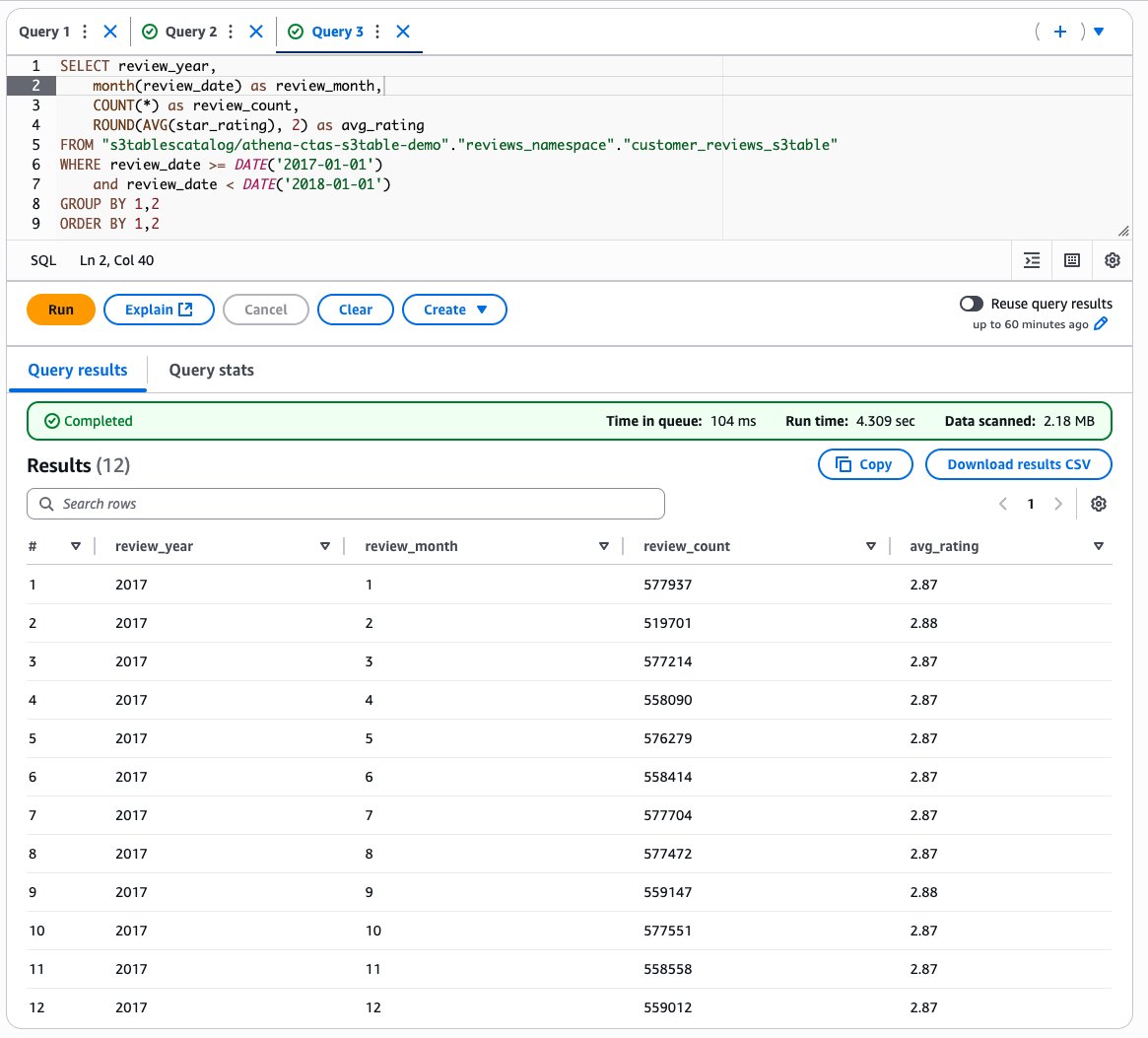
Subsequent, let’s analyze month-to-month evaluation tendencies:
The next screenshot reveals our output.
ACID operations on S3 Tables
Athena helps commonplace SQL DML operations (INSERT, UPDATE, DELETE and MERGE INTO) on S3 Tables with full ACID transaction ensures. Let’s reveal these capabilities by including historic knowledge and performing knowledge high quality checks.
Insert extra knowledge into the desk utilizing INSERT
Use the next question to insert evaluation knowledge from 2014 and 2015 that wasn’t included within the preliminary CTAS operation:
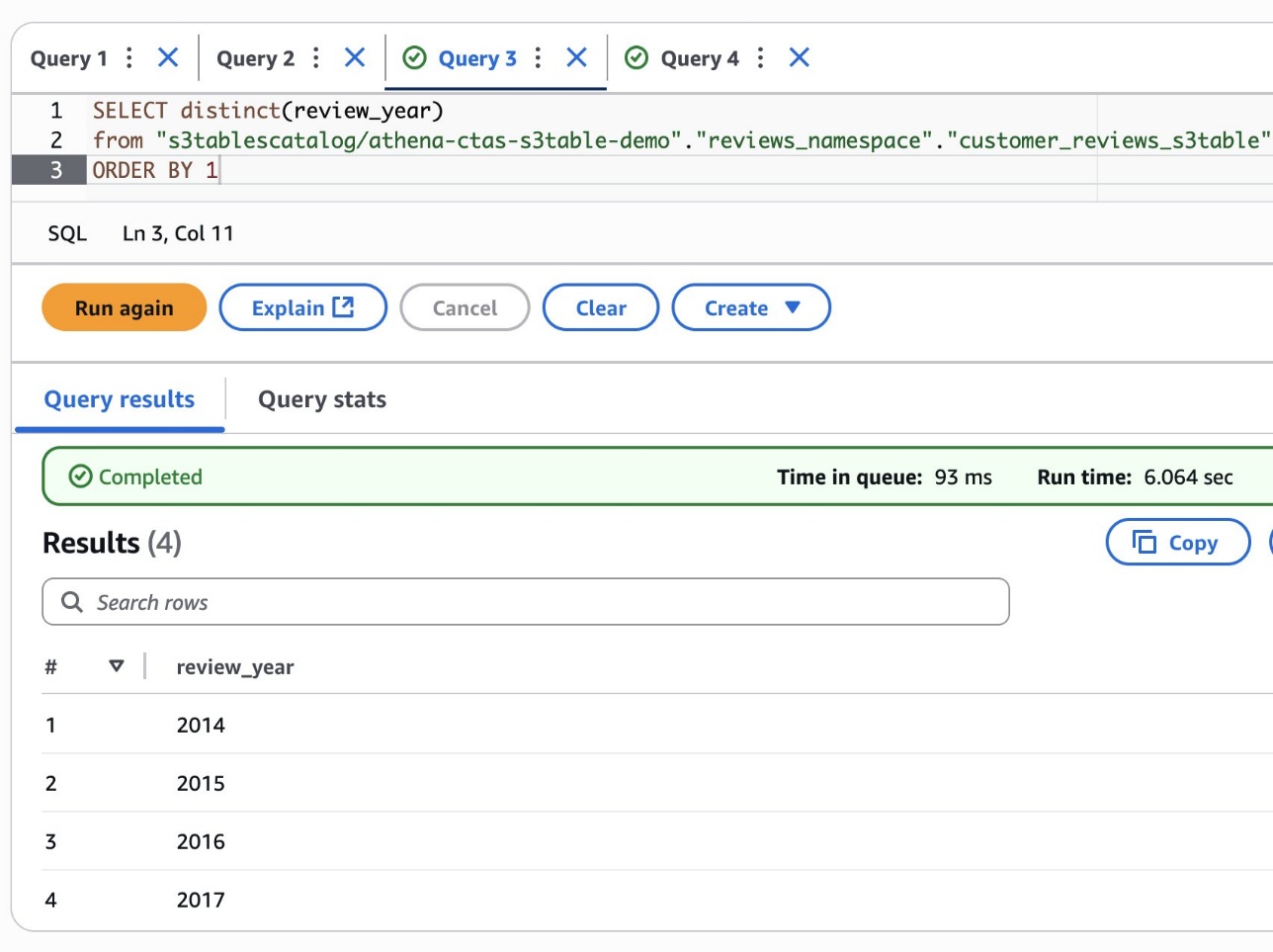
Examine which years at the moment are current within the desk:
The next screenshot reveals our output.
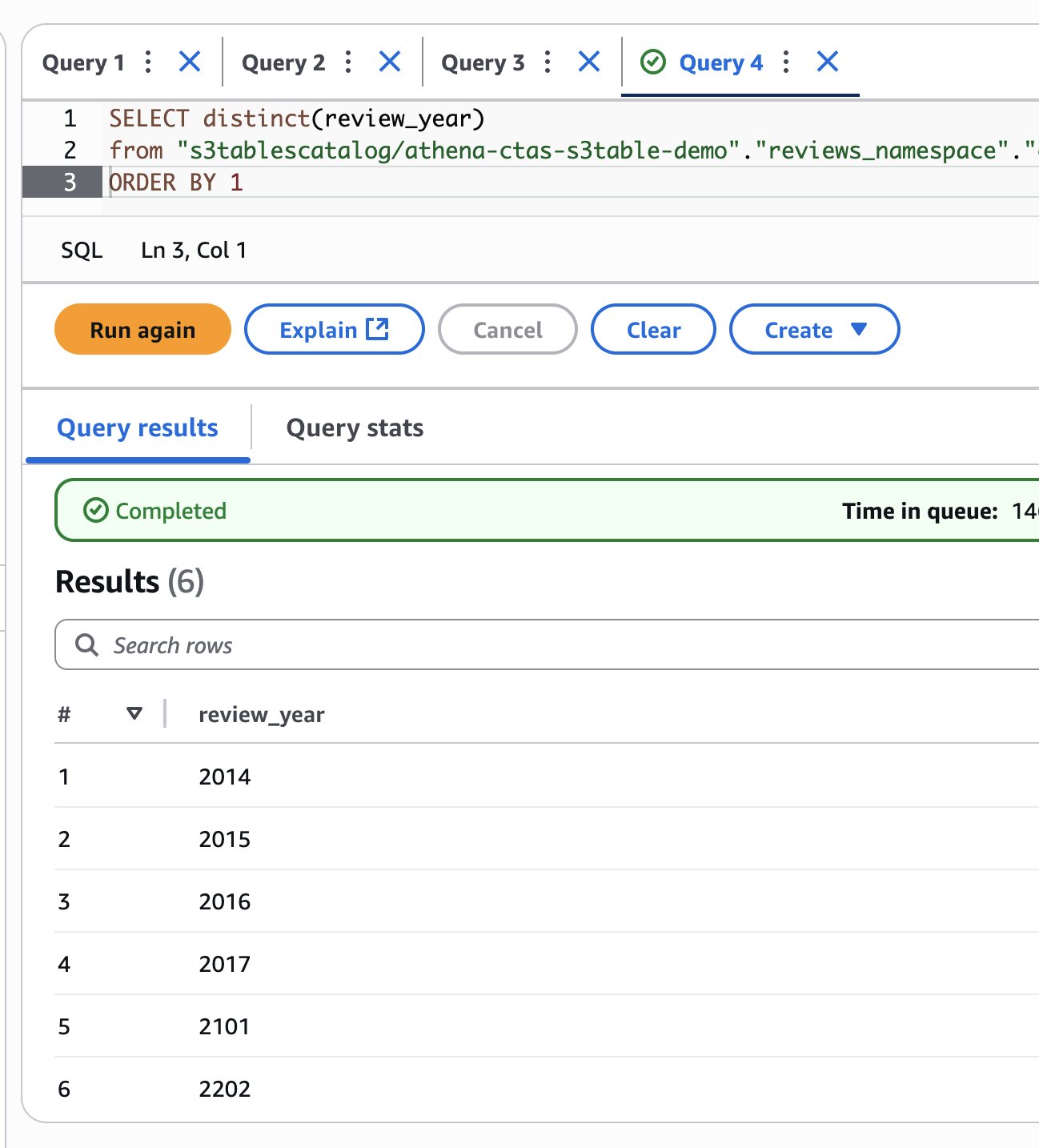
The outcomes present that you’ve efficiently added 2014 and 2015 knowledge. Nonetheless, you may also discover some invalid years like 2101 and 2202, which look like knowledge high quality points within the supply dataset.
Clear invalid knowledge utilizing DELETE
Take away the information with incorrect years utilizing the S3 Tables DELETE functionality:
Affirm the invalid information have been eliminated.
Replace product classes utilizing UPDATE
Let’s reveal the UPDATE operation with a enterprise state of affairs. Think about the corporate decides to rebrand the Movies_TV product class to Entertainment_Media to higher mirror buyer preferences.
First, study the present product classes and their file counts:
You must see a file with product_category as Movies_TV with roughly 5,690,101 evaluations. Use the next question to replace all Movies_TV information to the brand new class title:
Confirm the class title change whereas confirming the file rely stays the identical:
The outcomes now present Entertainment_Media with the identical file rely (5,690,101), confirming that the UPDATE operation efficiently modified the class title whereas preserving knowledge integrity.
These examples reveal transactional assist in S3 Tables by means of Athena. Mixed with automated desk upkeep, this helps you construct scalable, transactional knowledge lakes extra effectively with minimal operational overhead.
Further transformation eventualities utilizing CTAS
The Athena CTAS performance helps a number of transformation paths to S3 Tables. The next eventualities reveal how organizations can use this functionality for numerous knowledge modernization wants:
- Convert from numerous knowledge codecs – Athena can question knowledge in a variety of codecs in addition to federated knowledge sources, and you’ll convert these queryable sources to an S3 desk utilizing CTAS. For instance, to create an S3 desk from a federated knowledge supply, use the next question:
- Rework between S3 tables for optimized analytics – Organizations typically have to create derived tables from present S3 tables optimized for particular question patterns. For instance, contemplate a desk containing detailed buyer evaluations that’s partitioned by product class. In case your analytics group ceaselessly queries by date ranges, you need to use CTAS to create a brand new S3 desk partitioned by date for considerably higher efficiency on time-based queries. For instance, the next question creates an aggregated analytics S3 desk:
- Rework from self-managed open desk codecs – Organizations sustaining their very own Iceberg tables can rework them into S3 tables to benefit from computerized optimization and scale back operational overhead:
- Mix a number of supply tables – Organizations typically have to consolidate knowledge from a number of tables right into a single desk for simplified analytics. This method may also help scale back question complexity and enhance efficiency by pre-joining associated datasets. The next question joins a number of tables utilizing CTAS to create an S3 desk:
These eventualities reveal the flexibleness of Athena CTAS for numerous knowledge modernization wants, from easy format conversions to advanced knowledge consolidation tasks.
Clear up
To keep away from ongoing prices, clear up the assets created throughout this walkthrough. Full these steps within the specified order to facilitate correct useful resource deletion. You would possibly want so as to add respective delete permissions for databases, desk buckets, and tables in case your IAM consumer or position doesn’t have already got them.
- Delete the S3 desk created by means of CTAS:
- Take away the namespace from the desk bucket:
- Delete the desk bucket.
- Take away the database and desk created for the artificial dataset:
- Delete any created IAM roles or insurance policies.
- Delete the Athena question end result location in Amazon S3 when you saved ends in an S3 location.
Conclusion
This put up demonstrated how the CTAS performance in Athena simplifies knowledge transformation to S3 Tables utilizing commonplace SQL statements. We coated the whole transformation course of, together with format conversions, ACID operations, and numerous knowledge transformation eventualities. The answer delivers simplified knowledge transformation by means of single SQL statements, computerized upkeep, and seamless integration of S3 Tables with AWS analytics companies and third-party instruments. Organizations can modernize their knowledge infrastructure whereas attaining enterprise-grade efficiency.
To get began, start by figuring out datasets that might profit from optimization or transformation, then check with Working with Amazon S3 Tables and desk buckets and Register S3 desk bucket catalogs and question Tables from Athena to implement the transformation patterns demonstrated on this walkthrough. The mix of the serverless capabilities of Athena with the automated optimizations in S3 Tables can present a strong basis for contemporary knowledge analytics.
Concerning the authors
 Pathik Shah is a Sr. Analytics Architect on Amazon Athena. He joined AWS in 2015 and has been focusing within the huge knowledge analytics area since then, serving to prospects construct scalable and sturdy options utilizing AWS Analytics companies.
Pathik Shah is a Sr. Analytics Architect on Amazon Athena. He joined AWS in 2015 and has been focusing within the huge knowledge analytics area since then, serving to prospects construct scalable and sturdy options utilizing AWS Analytics companies.
 Aritra Gupta is a Senior Technical Product Supervisor on the Amazon S3 group at Amazon Internet Companies. He helps prospects construct and scale knowledge lakes. Based mostly in Seattle, he likes to play chess and badminton in his spare time.
Aritra Gupta is a Senior Technical Product Supervisor on the Amazon S3 group at Amazon Internet Companies. He helps prospects construct and scale knowledge lakes. Based mostly in Seattle, he likes to play chess and badminton in his spare time.