

Conventional enterprise intelligence (BI) integration with enterprise knowledge warehouses has been the established sample for years. With generative AI, now you can modernize BI workloads with capabilities like interactive chat brokers, automated enterprise processes, and utilizing pure language to generate dashboards.
On this submit, we offer implementation steerage for constructing built-in analytics options that mix the generative BI options of Amazon Fast with Amazon Redshift and Amazon Athena SQL analytics capabilities. Use this submit as a reference for proof-of-concept implementations, manufacturing deployment planning, or as a studying useful resource for understanding Fast integration patterns with Amazon Redshift and Athena.
Widespread use instances
You need to use this built-in method throughout a number of eventualities. The next are a number of the most typical use instances.
- Conventional BI reporting advantages from bundled knowledge warehouse and BI instrument pricing, making generative BI the first use case with vital price benefits.
- Insurance coverage: Automates Solvency II and IFRS 17 regulatory reporting, changing guide spreadsheet consolidation.
- Banking: Accelerates FDIC name report era and capital adequacy dashboards, reducing month-end shut from days to hours.
- Interactive dashboards with contextual chat brokers give BI groups conversational interfaces alongside their visible metrics.
- Gaming: Reside ops groups question participant retention and monetization KPIs in plain English—no SQL wanted.
- Monetary Companies: Buying and selling analysts chat with real-time P&L dashboards to floor anomalies and drill into positions on demand.
- Area-specific analytics workspaces democratize enterprise knowledge exploration by means of Fast Areas and pure language queries.
- Insurance coverage: Actuarial and underwriting groups question claims and threat knowledge with out ready on knowledge engineering.
- Banking: Threat and compliance groups discover credit score, market, and operational knowledge by means of a single pure language interface.
- Workflow automation removes repetitive duties and accelerates self-service analytics.
- Monetary Companies: Automated AR reconciliation flows change guide ledger matching, shrinking shut cycle effort considerably.
- Gaming: Telemetry ingestion pipelines set off reporting refreshes robotically, releasing knowledge engineers from routine work.
Allow us to study an end-to-end resolution combining these applied sciences.
Resolution circulate
AWS affords two native SQL analytics engines for constructing analytics workloads. Amazon Redshift gives a completely managed knowledge warehouse with columnar storage and massively parallel processing. Amazon Athena delivers serverless interactive question capabilities immediately towards knowledge in Amazon S3.
You need to use both Amazon Redshift or Amazon Athena as a SQL engine whereas implementing the steps on this submit. The next are the steps concerned in constructing an end-to-end resolution.
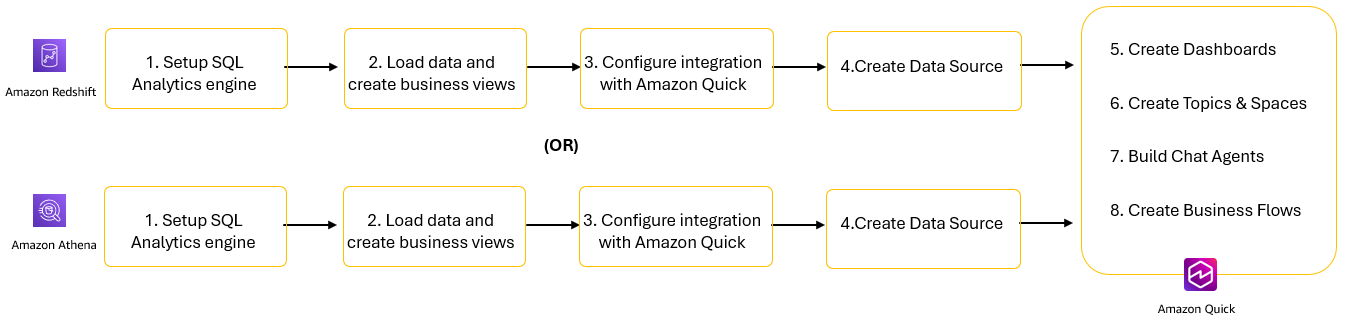
Figure1: Resolution steps to combine SQL Analytics engines with Amazon Fast
- Arrange your SQL analytics engines: Amazon Redshift or Amazon Athena.
- Load knowledge and create enterprise views designed for analytics workloads.
- Configure integration between SQL analytics engines and Amazon Fast.
- Create knowledge sources in Amazon Fast.
- Create datasets and dashboards for visible analytics.
- Use Matters and Areas to supply pure language interfaces to your knowledge.
- Deploy chat brokers to ship conversational AI experiences for enterprise customers.
- Implement enterprise flows to automate repetitive workflows and processes.
Let’s begin by strolling by means of steps 1–4 for Amazon Redshift. We then describe the identical 4 steps for Amazon Athena earlier than explaining the Amazon Fast steps 5–8.
Configure and create datasets in Amazon Redshift
Amazon Redshift affords two deployment choices to satisfy your knowledge warehousing wants. Provisioned clusters present conventional deployment the place you handle compute assets by deciding on node varieties and cluster dimension. Serverless robotically scales compute capability based mostly on workload calls for with pay-per-use pricing. Each choices are supported by Amazon Fast. For this walkthrough, we use Redshift Serverless.
Arrange SQL analytics engine
To create a Redshift Serverless namespace and workgroup:
- Open the Amazon Redshift console.
- On the left navigation pane, choose Redshift Serverless.
- Comply with the steps described within the Making a workgroup with a namespace documentation web page to create a workgroup and a namespace. Notice the username and password offered. You’ll use these particulars for configuring connections in Amazon Redshift and Fast.
- You must see the standing as Obtainable for each the workgroup and namespace within the Serverless dashboard.
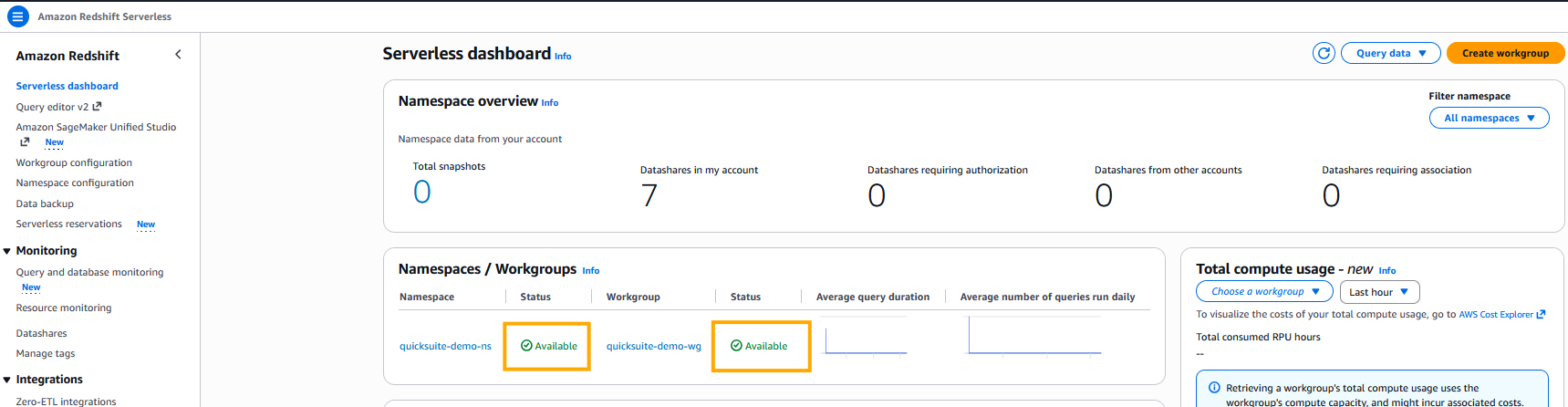
Determine 2: Amazon Redshift Serverless Workgroup and NamespacesThe deployment shall be accomplished in roughly 3–5 minutes.
Load knowledge and create enterprise views
Now you may load knowledge utilizing the industry-standard TPC-H benchmark dataset, which gives lifelike buyer, order, and product knowledge for analytics workloads.To load knowledge into Amazon Redshift:
- Open the Amazon Redshift Question Editor V2 from the console.
- Run the TPC H DDL statements to create TPC-H tables.
- Run the next COPY instructions to load knowledge from the general public S3 bucket:
s3://redshift-downloads/TPC-H/.
Be certain that the IAM position connected to the namespace is about because the default IAM position. When you didn’t arrange the default IAM position on the time of namespace creation, you may discuss with the Creating an IAM position as default for Amazon Redshift documentation web page to set it now.
Run the next question to validate load standing. The standing column ought to present as accomplished. You can too evaluation the data in different columns to see particulars concerning the masses comparable to document counts, length, and knowledge supply.

Determine 3: Output of SYS_LOAD_HISTORY displaying profitable completion of COPY Jobs
- Create a materialized view to enhance question efficiency:
Run the next SQL to create a materialized view that pre-compute outcomes set for buyer revenues and order volumes by market phase.
Run the next SQL to evaluation the info within the materialized view.
Configure integration with Amazon Fast
Amazon Fast auto discovers the Amazon Redshift provisioned clusters which can be related together with your AWS account. These assets should be in the identical AWS Area as your Amazon Fast account. For Amazon Redshift clusters in different accounts or Amazon Redshift Serverless, we advocate that you simply add a VPC connection following the steps in Enabling entry to an Amazon Redshift cluster in a VPC documentation. Normally, these steps are carried out by your group’s cloud safety administration staff.
For serverless, you’ll apply the identical steps within the workgroup as a substitute of the cluster. You’ll find the VPC and Safety Group settings within the Information Entry tab of a workgroup.
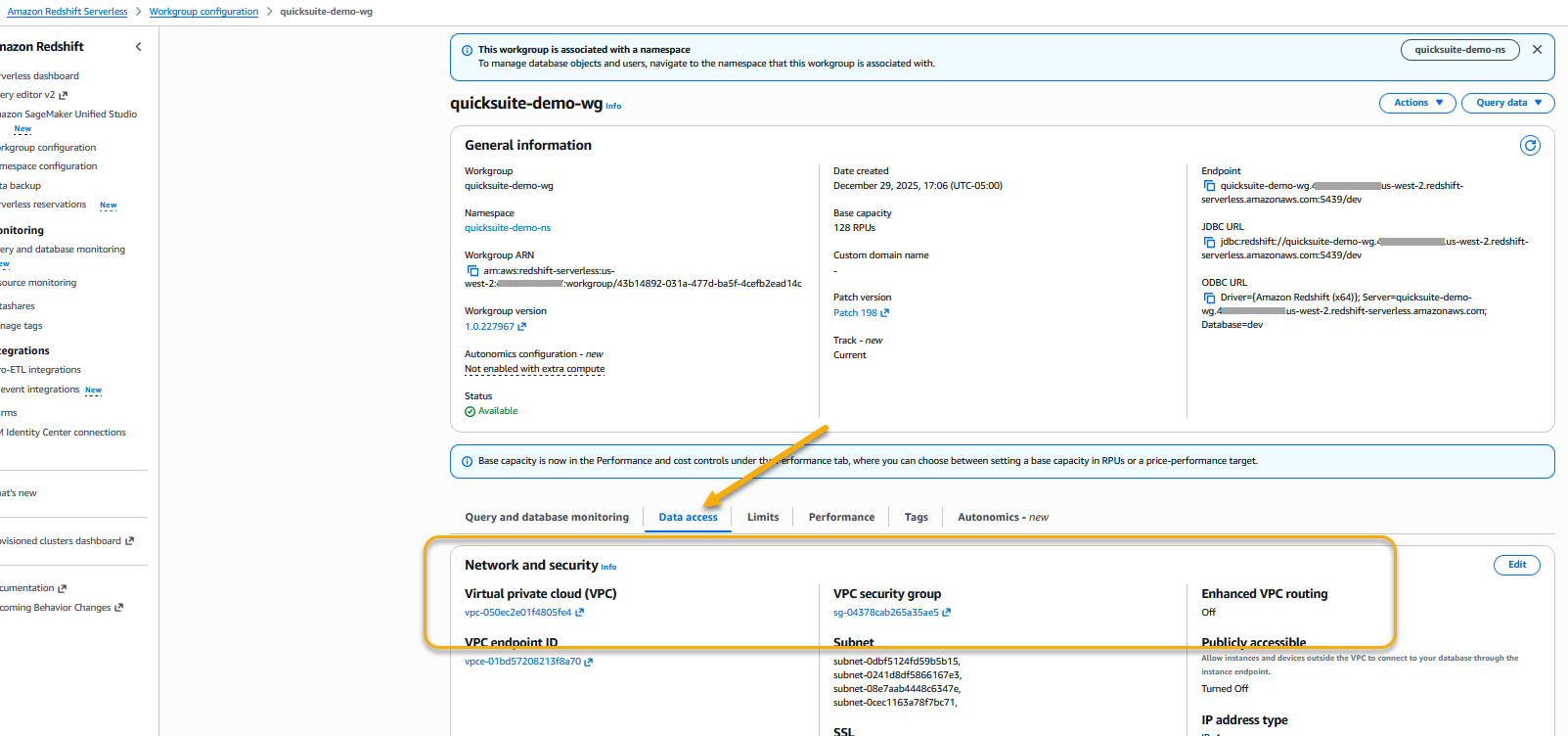
Determine 4: Amazon Redshift Serverless workgroup VPC and Safety teams
You can too discuss with How do I privately join Fast to an Amazon Redshift or RDS knowledge supply in a personal subnet? for an illustration.
Create knowledge supply
To create a dataset connecting to Amazon Redshift, full the next steps.
- Within the Fast left navigation pane, go to Datasets.
- Select the Information sources tab and choose Create knowledge supply.
- Choose Amazon Redshift and enter the next:
- Information Supply Identify: Present
customer-rev-datasourceas knowledge supply title. - Connection kind: Choose the VPC connection created within the earlier step.
- Database server: Enter the Amazon Redshift workgroup endpoint (for instance,
quick-demo-wg.123456789.us-west-2.redshift-serverless.amazonaws.com). - Port: 5439 (default).
- Database:
dev. - Username/Password: Amazon Redshift credentials with entry to the database.
- Information Supply Identify: Present
- Select Validate connection. The validation must be profitable.
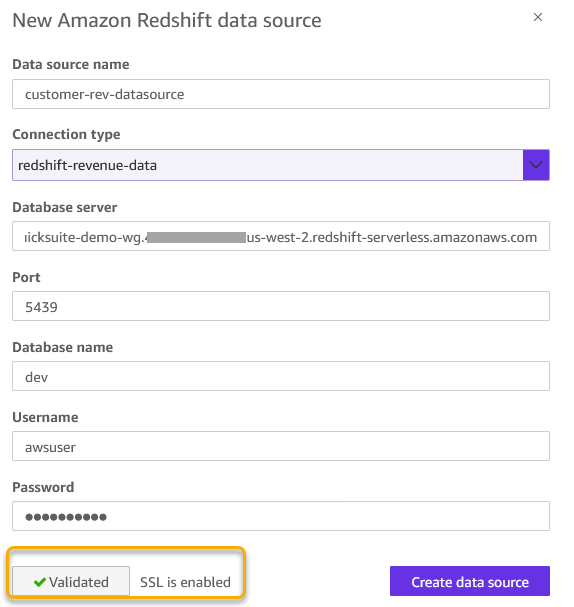
Determine 5: Amazon Redshift knowledge supply configuration
- Select Create Information Supply to create an information supply.
Now let’s discover the way to carry out all these 4 steps to configure Athena in Amazon Fast.
Configure and create datasets in Amazon Athena
Amazon Athena gives fast question capabilities towards petabytes of information with automated scaling to deal with concurrent customers. Let’s undergo the steps to configure connections between Amazon Fast and Amazon Athena.
Arrange SQL analytics engine
To create an Athena workgroup:
- Open the Amazon Athena console.
- Within the navigation pane, select Workgroups.
- Select Create workgroup.
- For Workgroup title, enter
quick-demo. - For Question outcome configuration, choose Athena managed.
- Select Create workgroup.
Your workgroup is prepared instantly for querying knowledge.
Load knowledge and create enterprise views
For Athena, you create tables utilizing the TPC-H benchmark dataset that AWS gives in a public S3 bucket. This method provides you 1.5 million buyer information already optimized in Parquet format with out requiring knowledge loading.
To create tables and views in Athena:
- Open the Athena Question Editor from the console.
- Create a database in your analytics (create S3 bucket if it exists already):
- Create an exterior desk pointing to the TPC-H public dataset:
- Create a business-friendly view for analytics:
Run the next SQL to create a view that aggregates buyer account balances grouped by market segments.
- Confirm your view from Athena with:
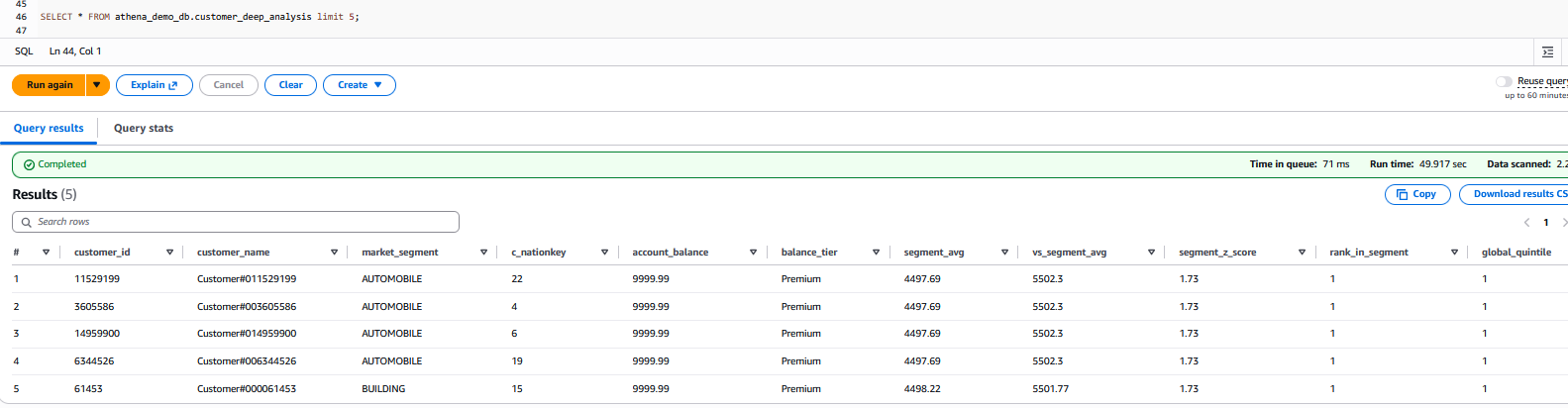
Determine 6: Output from the SELECT question
Configure integration with Amazon Fast
To connect with Amazon Athena in Amazon Fast, observe these steps, consolidated from official AWS documentation and authorizing connections to Amazon Athena.
Authorize Fast to Entry Athena, S3 Bucket for knowledge, and S3 bucket for Athena Outcomes.
Open the Amazon Fast Safety Settings
- Check in to the Amazon Fast console as an administrator.
- Within the top-right nook, select your profile icon, then choose Handle account.
- Below Permissions, select AWS assets.

Determine 7: AWS useful resource permissions
{kind=link}
Allow Athena Entry
- Below Fast entry to AWS companies, select Handle.
- Find Amazon Athena within the listing of AWS companies.
- If Athena is already chosen however entry points persist, clear the checkbox and re-select it to re-enable Athena.
- Below Amazon S3, choose S3 buckets.
- Test the bins subsequent to every S3 bucket that Amazon Fast must entry—together with buckets used for Athena question outcomes and any Redshift COPY supply buckets.
- Allow Write permission for Athena Workgroup to permit Amazon Fast to jot down Athena question outcomes to S3 and select End.
- Select Save to replace the configuration.
The ultimate step is to grant your Amazon Fast creator permissions to question your database, Athena tables, and views. Configuration will depend on whether or not AWS Lake Formation is enabled.
If AWS Lake Formation shouldn’t be enabled
Permissions are managed on the Fast service position stage by means of commonplace IAM-based S3 entry management. Be certain that the Fast service position (for instance, aws-quick-service-role-v0) has the suitable IAM permissions for the related S3 buckets and Athena assets. No further Lake Formation configuration is required.
If AWS Lake Formation is enabled
Lake Formation acts because the central authorization layer, overriding commonplace IAM-based S3 permissions. Grant permissions on to the Amazon Fast creator or IAM position.
To grant knowledge permissions:
- Open the AWS Lake Formation console.
- Select Permissions, then Information permissions, then Grant.
- Choose the IAM person or position.
- Select the required databases, tables, and columns.
- Grant SELECT at minimal; add DESCRIBE for dataset creation.
- Repeat for every person or position that requires entry.
Create knowledge supply
Comply with these steps to create an Athena knowledge supply on Amazon Fast.
- Within the Amazon Fast console, navigate to Datasets and select Information sources tab.
- Select Create knowledge supply, then choose the Amazon Athena card.
- Enter a Information supply title (you may give any title of your alternative), choose your Athena workgroup (like quick-demo), and select Validate connection.
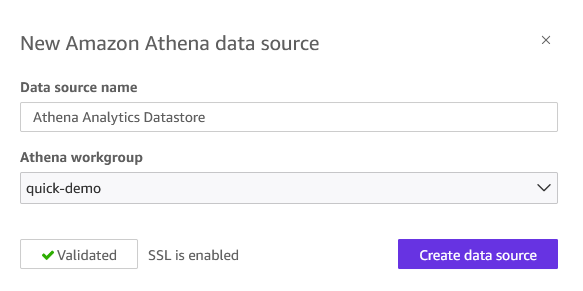
Determine 8: Athena knowledge supply creation
- Select Create knowledge supply.
Your Athena knowledge supply is now obtainable for constructing datasets, dashboards, and Matters.
Use Amazon Fast generative AI options
The subsequent steps, from 5–8, show Amazon Fast generative AI capabilities utilizing Amazon Redshift as an information supply. Whereas we use Amazon Redshift on this instance, you may substitute with Amazon Athena based mostly in your particular necessities.
Create dashboards
Let’s begin by creating datasets from the Amazon Redshift knowledge supply.
- Within the left navigation pane, select Datasets.
- On the Datasets web page, select Create Dataset.
- For the info supply, choose Amazon Redshift knowledge supply
customer-rev-datasource. - From the menu, select
mv_customer_revenue.
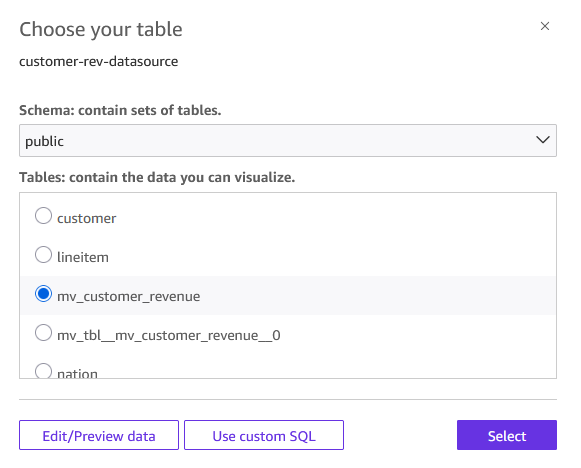
Determine 9: Choose desk to visualise
- You possibly can select one of many following question modes. For this submit, choose Immediately question your knowledge possibility and select Visualize.
- Import to SPICE for faster analytics – Fast masses a snapshot into its in-memory engine for sooner dashboard efficiency.
- Immediately question your knowledge– Fast runs queries on demand towards your question engine.
- Choose Construct icon to open a chat window. Enter “Present me orders by market segments” because the immediate. Notice that you simply want Creator Professional entry to make use of this characteristic.
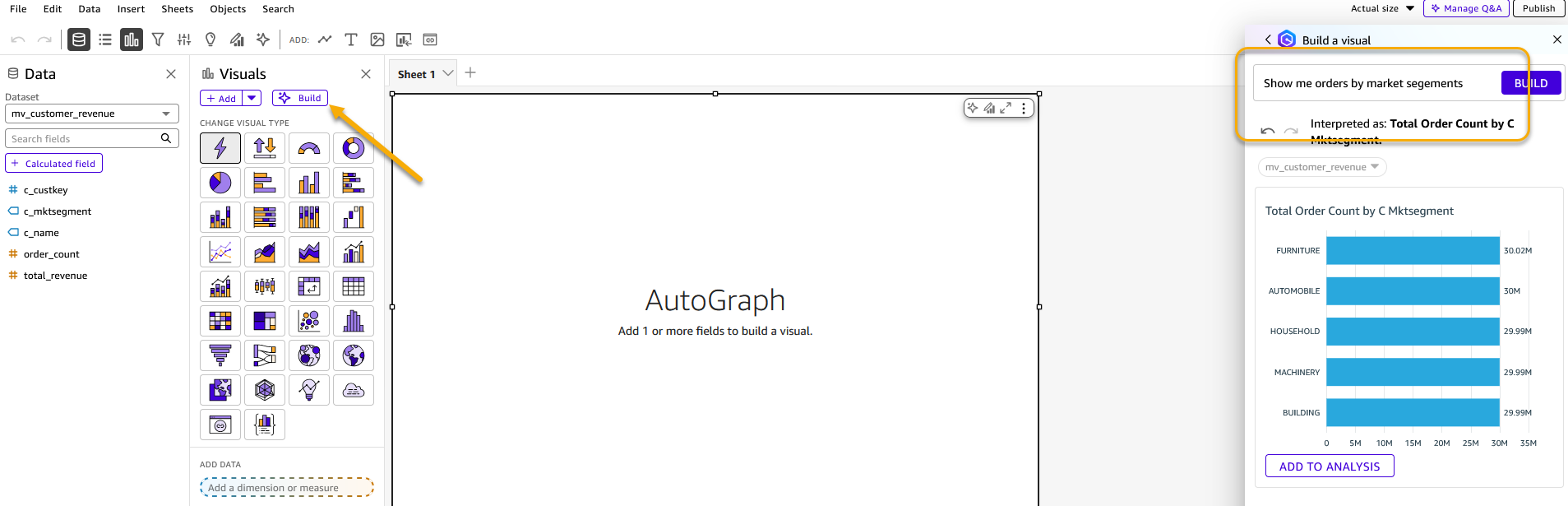
Determine 10: Construct visualization utilizing generative BI characteristic
- You possibly can change the visible kind to a pie chart and add it to the evaluation.
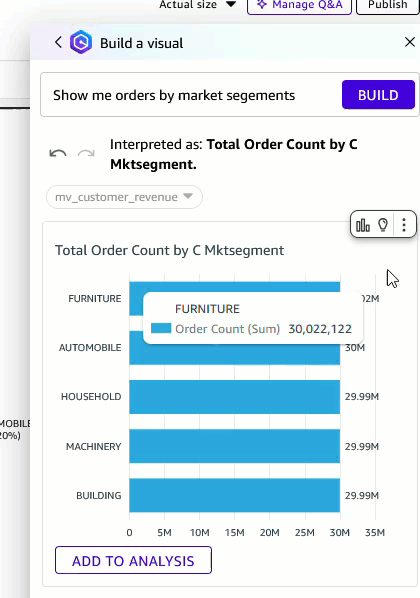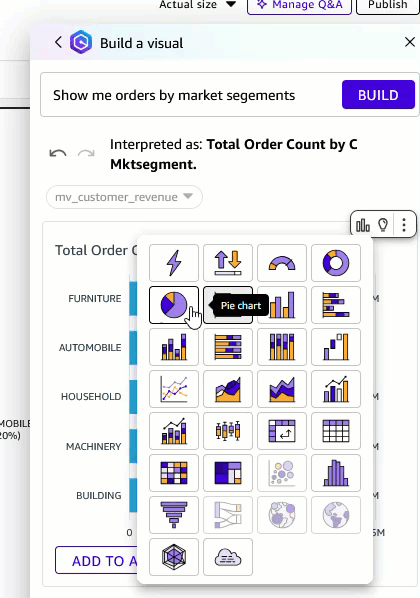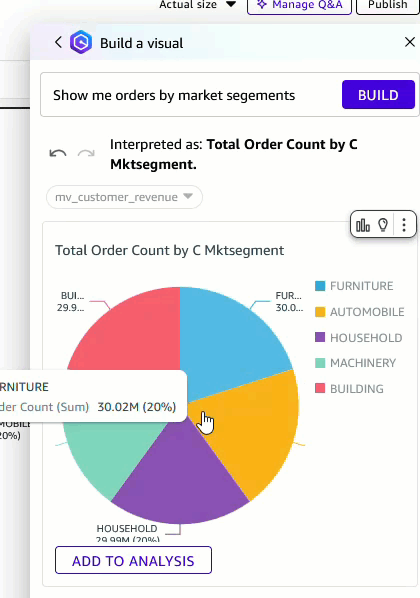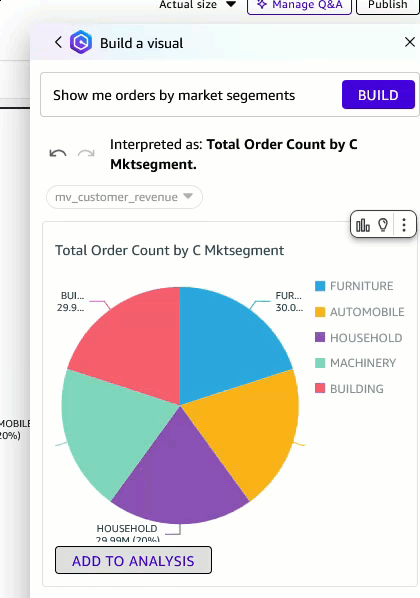
Determine 10: Change visible kind
To publish your evaluation as a dashboard
- After you add the visuals, select Publish.
- Enter a reputation for the dashboard. For this submit, use the Market Section Dashboard.
- Select Publish dashboard. Your dashboard is now obtainable for viewing and sharing.
Create subjects and areas
To completely maximize enterprise knowledge with AI, we should present the proper construction and context. That’s the place Matters and Areas are available. Matters act as pure language interfaces to your structured datasets, robotically analyzing your knowledge, mapping fields, and including synonyms. Enterprise customers can ask “What are whole revenues by market phase?” and obtain on the spot, visualized solutions with out writing a single line of SQL. Areas deliver collectively your whole associated property right into a single collaborative workspace that democratizes knowledge entry, reduces context-switching, accelerates staff onboarding, so everyone seems to be working from the identical trusted, AI-ready knowledge sources.
To create a Fast subject
- From the Amazon Fast homepage, select Matters, then select Create subject.
- Enter a reputation in your subject. For this submit, use Buyer Income Analytics.
- Enter an outline. For instance:
The Buyer Income Analytics subject is designed for enterprise customers (together with analysts, gross sales operations groups, finance, and market phase homeowners who have to discover buyer and income knowledge with out SQL experience. It serves as a pure language interface over the mv_customer_revenue Amazon Redshift dataset, permitting customers to ask plain-English questions like “What are whole revenues by market phase?” and obtain on the spot, visualized solutions. By robotically mapping enterprise language to the underlying schema, it democratizes entry to income insights throughout the group.
- Below Dataset, choose
mv_customer_revenue. - Select Create. The subject can take 15–half-hour to allow relying on the info. Throughout this time, Amazon Fast robotically analyzes your knowledge, selects related fields, and provides synonyms.
- After the subject is enabled, take a couple of minutes to evaluation and enrich it. The next are some instance enrichments.
- Add column descriptions to make clear area that means for enterprise customers.
- Outline most popular aggregations (for instance, sum in comparison with common for income fields).
- Verify which fields are Dimensions and that are Measures.
- (Optionally available) To additional refine how your subject interprets and responds to queries, add a number of datasets (for instance, a buyer CSV mixed with a database view), customized directions, filters, and calculated fields.
After your subject is created, its columns can be found so as to add to a House or to an Agent by deciding on it as an information supply.
Determine 11: Create a Fast Matter
Create a House in your staff
Areas deliver collectively dashboards, subjects, datasets, paperwork, and different assets into organized, collaborative workspaces. By centralizing associated property in a single workspace, Areas cut back context-switching, speed up onboarding, so everyone seems to be working from the identical trusted knowledge sources.
What to incorporate in your Fast House
- Dashboard – Add the dashboard Market Section Dashboard revealed out of your
mv_customer_revenueevaluation. This offers staff members on the spot entry to visualizations comparable to income by market phase, high clients by order quantity, and income distribution. - Matter – Join the Buyer Income Analytics (constructed on the
mv_customer_revenuematerialized view) to allow pure language queries immediately towards your Amazon Redshift knowledge. - Optionally, you may add supporting context to floor your staff’s evaluation:
- Information dictionary or area definitions for
mv_customer_revenue - Market phase definitions (AUTOMOBILE, BUILDING, FURNITURE, MACHINERY, HOUSEHOLD)
- Enterprise guidelines for income calculation (for instance, how reductions are utilized within the TPC-H mannequin)
- This implementation information, so new staff members can onboard shortly
- Information dictionary or area definitions for
To create the Fast House
- From the left navigation menu, select Areas, then select Create area.
- Enter a reputation, for instance, Buyer Income & Segmentation.
- Enter an outline. For instance:
Centralized workspace for buyer income evaluation powered by Amazon Redshift consists of interactive dashboards, pure language question entry to buyer and phase knowledge, and helps documentation for the TPC-H income mannequin.
- Add information by connecting the Market Section Dashboard and subject Buyer Income Analytics.
- You possibly can invite staff members, comparable to finance, gross sales operations, and phase homeowners, and set applicable permissions.
Your House is now prepared for collaborative knowledge exploration.
Determine 12: Create a Fast House
Construct chat brokers
A customized chat agent delivers conversational AI experiences that perceive enterprise context and supply clever, grounded responses to person queries. These brokers transcend question-and-answer interactions. They synthesize information out of your dashboards, subjects, datasets, and paperwork to clarify traits, floor anomalies, information customers by means of complicated analytics workflows, and advocate subsequent steps.
Reasonably than requiring customers to navigate a number of instruments or write SQL queries, brokers function a single conversational interface to your total analytics surroundings. Brokers may connect with Actions, pre-built integrations with enterprise instruments comparable to Slack, Microsoft Groups, Outlook, and SharePoint, enabling them to reply questions and set off real-world workflows, ship notifications, create duties, and work together with exterior programs immediately from the dialog. Customized brokers will be tailor-made to particular enterprise domains, groups, or use instances in order that responses align with organizational terminology, knowledge definitions, and enterprise processes. After created, brokers will be shared throughout groups, enabling constant, actionable, AI-powered knowledge entry at scale. For groups working with the mv_customer_revenue dataset, we advocate making a devoted Buyer Income Evaluation Agent. It is a purpose-built conversational assistant grounded in your Amazon Redshift knowledge, dashboards, and the Buyer Income & Segmentation House.
Create a Fast chat agent
There are two ways in which you should use Amazon Fast to create a Fast agent. You need to use the navigation menu or immediately from House. The next steps stroll you thru creating one from the navigation menu.
To create a Fast chat agent
- From the left navigation menu, select Brokers, then select Create agent.
- Enter a reputation in your agent, for instance, Buyer Income Analyst.
- Enter an outline. For instance:
An AI assistant for analyzing buyer income, market phase efficiency, and order traits utilizing our Amazon Redshift or knowledge warehouse.
- Below Data Sources, add the Buyer Income & Segmentation House as an information supply. This offers your agent entry to the dashboards, subjects, and reference paperwork you’ve already constructed.
- (Optionally available) Outline customized persona directions to align the agent’s responses with your corporation context. For instance, specifying most popular terminology, response model, or the sorts of questions it ought to prioritize.
- Select Launch chat agent.
- Begin having a dialog together with your knowledge. You’re welcome to ask any questions. The next are some examples.
- Which market phase generated most income?
- Present me order traits
Determine 13: Create a Fast Chat agent
To share your Fast chat agent
After your agent is revealed, select Share and invite staff members or share it throughout your group. Customized brokers will be tailor-made to particular enterprise contexts in order that completely different groups can get AI help that speaks their language, with no need to configure something themselves.
Create Fast Flows
Fast Flows automate repetitive duties and orchestrate multi-step workflows throughout your total analytics surroundings. This removes guide effort, decreasing human error, and making certain constant execution of important enterprise processes. Flows will be triggered on a schedule or launched on demand, providing you with versatile management over when and the way automation runs.
You possibly can construct flows that span the total analytics lifecycle: monitoring knowledge high quality and flagging anomalies, producing and distributing scheduled experiences to stakeholders, and triggering downstream actions in built-in programs comparable to Slack, Outlook. Amazon Fast provides you 3 ways to create a circulate, so whether or not you favor a no-code dialog or a visible step-by-step builder, there’s an possibility that matches how you’re employed.
To create a circulate from chat
- Whereas conversing with My Assistant or a customized agent, describe the workflow that you simply need to automate in plain English.
- Amazon Fast generates the circulate and affords to create it immediately out of your dialog — no configuration screens required.
To create a circulate from a pure language description
- From the left navigation menu, select Flows, then select Create circulate.
- Enter a plain-English description of your workflow. For instance:
” Question income knowledge by market segments. Filter by order depend and all dates. Search net for comparable related market traits. Generate formatted abstract experiences offering market abstract and look forward per phase. ”
- Amazon Fast robotically generates the whole workflow with all the mandatory steps.
- Optionally, you may add further steps.
- Select Run Mode to check the Circulation.
- After your circulate is created, share it with staff members or publish it to your group’s circulate library, so everybody advantages from the identical automation with out having to rebuild it independently.
Determine 14: Create a Fast Circulation to generate summaries and publish dashboards
For extra complicated circulate, evaluation weekly buyer income abstract circulate for example.
- Queries the
mv_customer_revenuematerialized view in Amazon Redshift for the most recent weekly income figures by market phase. - Compares outcomes towards the prior week to calculate segment-level variance.
- Generates a formatted abstract report and publishes it to the Buyer Income & Segmentation House.
- Sends a notification by means of e-mail or Slack to finance, gross sales operations, and phase homeowners with a direct hyperlink to the up to date dashboard.
- Flags any phase the place income has declined greater than an outlined threshold, routing an alert to the suitable proprietor for follow-up.
This circulate transforms what would possibly in any other case be a guide, multi-step reporting course of into a completely automated pipeline, so stakeholders obtain constant, well timed income insights with out analyst intervention and saving analysts an estimated 3–5 hours per week. For detailed steerage on creating and managing flows, see Utilizing Amazon Fast Flows. Additionally evaluation Create workflows for routine duties demo.
Cleanup
Take into account deleting the next assets created whereas following this submit to keep away from incurring prices. We encourage you to make use of the trials for gratis as a lot as potential to familiarize your self with the options described.
- Delete the Amazon Redshift Serverless workgroup and namespace.
- Delete Athena workgroup and S3 Buckets.
- Delete the Amazon Fast account used whereas following this submit. When you used an present account, delete the info units, dashboards, subjects, areas, brokers and flows created.
Conclusion
This built-in method to enterprise intelligence combines the ability of AWS SQL analytics engines with Amazon Fast generative AI capabilities to ship complete analytics options. By following these implementation steps, you identify a basis for conventional BI reporting, interactive dashboards, pure language knowledge exploration, and clever workflow automation. The structure scales from proof-of-concept implementations to manufacturing deployments, reworking how organizations entry and act on knowledge insights. For extra details about Amazon Fast options and capabilities, see the Amazon Fast documentation. To be taught extra about Amazon Redshift, go to the Amazon Redshift product web page. For Amazon Athena particulars, see the Amazon Athena product web page.