

{kind=link}
Migrating Apache Kafka workloads to the cloud usually entails managing complicated replication infrastructure, coordinating software cutovers with prolonged downtime home windows, and sustaining deep experience in open-source instruments like Apache Kafka’s MirrorMaker 2 (MM2). These challenges decelerate migrations and improve operational threat. Amazon MSK Replicator addresses these challenges, enabling you emigrate your Kafka deployments (known as “exterior” Kafka clusters) to Amazon MSK Specific brokers with minimal operational overhead and decreased downtime. MSK Replicator helps information migration from Kafka deployments (model 2.8.1 or later) which have SASL/SCRAM authentication enabled – together with Kafka clusters working on-premises, on AWS, or different cloud suppliers, in addition to Kafka-protocol-compatible providers like Confluent Platform, Avien, RedPanda, WarpStream, or AutoMQ when configured with SASL/SCRAM authentication.
On this publish, we stroll you thru the way to replicate Apache Kafka information out of your exterior Apache Kafka deployments to Amazon MSK Specific brokers utilizing MSK Replicator. You’ll discover ways to configure authentication in your exterior cluster, set up community connectivity, arrange bidirectional replication, and monitor replication well being to realize a low-downtime migration.
The way it works
MSK Replicator is a totally managed serverless service that replicates subjects, configurations, and offsets from cluster to cluster. It alleviates the necessity to handle complicated infrastructure or configure open-source instruments.
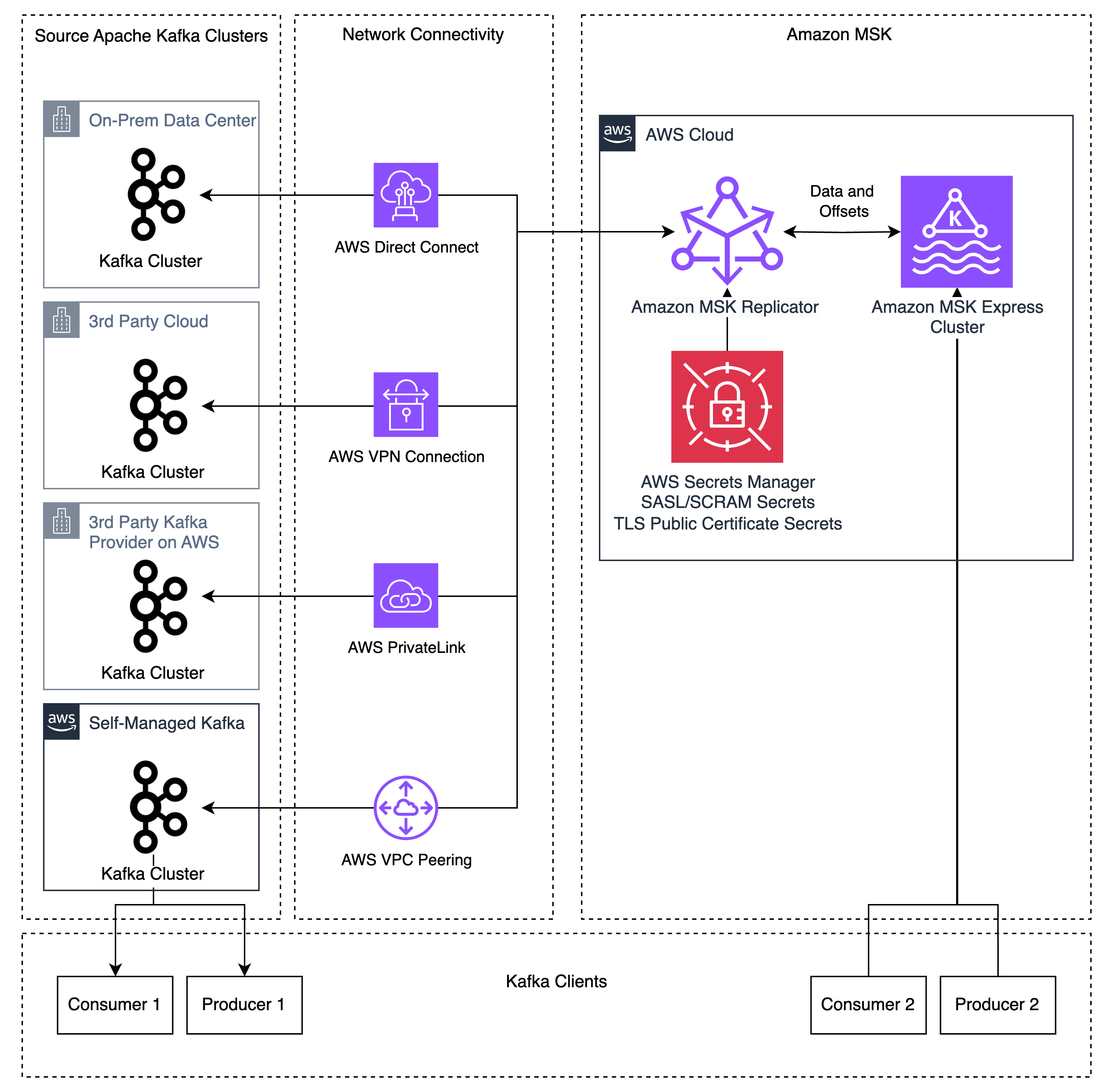
Earlier than MSK Replicator, prospects used instruments like MM2 for migrations. These instruments lack bi-directional matter replication when utilizing the identical matter names, creating complicated software architectures to eat totally different subjects on totally different clusters. Customized replication insurance policies in MM2 can permit similar matter names, however MM2 nonetheless lacks bidirectional offset replication as a result of the MM2 structure requires producers and customers to run on the identical cluster to duplicate offsets. This created complicated migrations that required both migrating customers earlier than producers or big-bang migrations migrating all functions without delay. When prospects run into points through the migration, the rollback course of is error-prone and introduces giant quantities of duplicate message processing because of the lack of shopper group offset synchronization. These approaches create threat and complexity for patrons that make migrations troublesome to handle.
MSK Replicator addresses these issues by supporting bidirectional replication of information and enhanced shopper group offset synchronization. MSK Replicator copies subjects and offsets from an exterior Kafka cluster to MSK, permitting you to protect the identical matter and shopper group names on each clusters. MSK Replicator additionally helps making a second Replicator occasion for bidirectional replication of each information and enhanced offset synchronization, permitting producers and customers to run independently on totally different Kafka clusters. Knowledge printed or consumed on the Amazon MSK cluster will likely be replicated again to the exterior cluster by the second Replicator. This characteristic works when producers and customers are migrated no matter order with out worrying about dependencies between functions.
As a result of MSK Replicator supplies bidirectional information replication and enhanced shopper group offset synchronization, you possibly can transfer producers and customers at your personal tempo with out information loss. This reduces migration complexity, permitting you emigrate functions between your exterior Kafka cluster and Amazon MSK no matter order. If you happen to run into issues through the migration, enhanced offset synchronization lets you roll again adjustments by transferring functions again to the exterior Kafka cluster, the place they restart from the newest checkpoint from the Amazon MSK cluster.
For instance, contemplate three functions:
- The “Orders” software, which accepts incoming orders and writes them to the orders Kafka matter
- The “Order standing” software, which reads from the “orders” Kafka matter and writes standing updates to the
order_statusmatter - The “Buyer notification” software, which reads from the
order_statusmatter and notifies prospects when standing adjustments
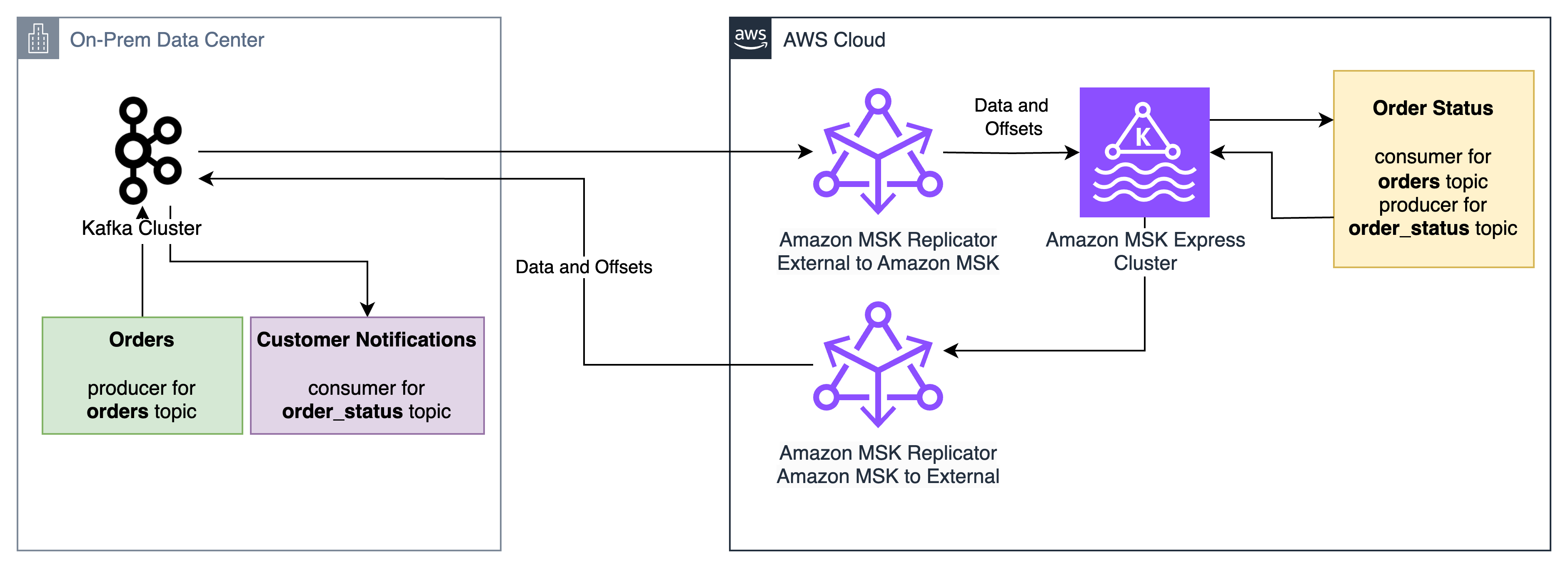
MSK Replicator allows these functions to be migrated between an on-premises Apache Kafka cluster and an Amazon MSK Specific cluster with low downtime and no information loss, no matter order. The “Order standing” software can migrate first, obtain orders from the on-premises “Orders” software, and ship standing updates to the on-premises “Buyer notification” software. If points come up through the migration, the “Order standing” software can roll again to the on-premises cluster and its shopper group offsets for the orders matter will likely be prepared for it to select up from the place it left off on the Amazon MSK cluster.
MSK Replicator helps information distribution throughout hybrid and multi-cloud environments for analytics, compliance, and enterprise continuity. Additionally it is configured for catastrophe restoration eventualities the place Amazon MSK Specific serves as a resilient goal to your exterior Kafka clusters.
In case you are at the moment utilizing MM2 for replication, see Amazon MSK Replicator and MirrorMaker2: Selecting the best replication technique for Apache Kafka catastrophe restoration and migrations to grasp which answer most closely fits your use case.
Answer overview
MSK Replicator helps Kafka deployments working model 2.8.1 or later as a supply, together with third social gathering managed Kafka providers, self-managed Kafka, and on-premises or third-party cloud-hosted Kafka. MSK Replicator robotically handles information switch, makes use of SASL/SCRAM authentication with SSL encryption, and maintains shopper group positions throughout each clusters. If you don’t use SASL/SCRAM at this time, this may be configured as a brand new listener used for MSK Replicator permitting present purchasers to make use of their present authentication mechanisms alongside MSK Replicator.
Conditions
To observe together with this walkthrough, you want the next sources in place:
Organising replication
Step 1: Configure community connectivity
You’ll be able to arrange community connectivity between your exterior Kafka cluster and your AWS VPC utilizing strategies akin to AWS Direct Join for devoted community connections, AWS Web site-to-Web site VPN for encrypted connections over the web, and AWS VPC peering or AWS Transit Gateway for connections between AWS VPCs. Confirm that IP routing and DNS decision are correctly configured between your exterior cluster and AWS.
To confirm IP routing and DNS decision, hook up with your exterior Kafka cluster from inside your VPC through the use of the Kafka CLI to record subjects on the exterior cluster. If you happen to can record subjects out of your VPC utilizing the Kafka CLI, this implies DNS decision and IP routing are working efficiently. If it fails, work along with your community admins to troubleshoot community connectivity points.
Step 2: Configure exterior cluster
On this step, you’ll arrange authentication in your exterior Kafka cluster and retailer the credentials in AWS Secrets and techniques Supervisor in order that MSK Replicator can join securely.
Configure authentication
Utilizing the exterior cluster admin consumer, configure SASL/SCRAM authentication for MSK Replicator utilizing SHA-256 or 512 in your exterior Kafka cluster. Create a SASL/SCRAM consumer for MSK Replicator and provides the consumer the next ACL permissions:
- Matter operations – Alter, AlterConfigs, Create, Describe, DescribeConfigs, Learn, Write
- Group operations – Learn, Describe
- Cluster operations – Create, ClusterAction, Describe, DescribeConfigs
Configure SecretsManager
AWS Secrets and techniques Supervisor shops your SASL/SCRAM credentials securely in order that MSK Replicator can retrieve them at runtime. The key should use JSON format and have the next keys:
username– The SCRAM username that you just configured within the authentication step abovepassword– The SCRAM password that you just configured within the authentication step abovecertificates– The general public root CA certificates (the top-level certificates authority that issued your cluster’s TLS certificates) and the intermediate CA chain (intermediate certificates between the basis and your cluster’s certificates), used for SSL handshakes with the exterior cluster
Optionally, you could create separate secrets and techniques for SCRAM credentials and the SSL certificates. This method is beneficial when secrets and techniques for SCRAM credentials and certificates are provisioned in numerous phases, akin to in Infrastructure as Code (IaC) pipelines.
Retrieve the cluster ID
Because the admin consumer, use the Kafka CLI instruments to retrieve the cluster ID of your exterior cluster. Run the next command, changing your-broker-host:9096 with the tackle of considered one of your exterior cluster’s bootstrap servers:
bin/kafka-cluster.sh cluster-id --bootstrap-server your-broker-host:9096 --config admin.propertiesThe command returns a cluster ID string akin to lkc-abc123. Pay attention to this worth as a result of you will want it when creating the replicator in Step 4.
Step 3: Create your MSK Specific goal cluster
Together with your exterior cluster configured, now you can arrange the goal. Create an Amazon MSK Specific cluster with IAM authentication enabled. Make it possible for the cluster is in subnets which have entry to AWS Secrets and techniques Supervisor endpoints. See Get began utilizing Amazon MSK for extra info on creating an MSK cluster.
Step 4: Create the replicator
Now that each clusters are prepared, you possibly can join them by establishing the MSK Replicator with the suitable IAM function and replication configuration.
Arrange an IAM function for MSK Replicator
MSK Replicator wants an IAM function to work together along with your MSK Specific cluster and retrieve secrets and techniques. Arrange a service execution IAM function with a belief coverage permitting kafka.amazonaws.com and fix the AWSMSKReplicatorExecutionRole permissions coverage. Pay attention to the function ARN for creating the replicator.
Create and fix a coverage for accessing your Secrets and techniques Supervisor secrets and techniques and studying/writing information in your MSK cluster. See Creating roles and attaching insurance policies (console) for extra info on creating IAM roles and insurance policies.
The next is an instance coverage for studying and writing information to your MSK cluster and studying KMS-encrypted Secrets and techniques Supervisor secrets and techniques:
{
"Model": "2012-10-17",
"Assertion": [
{
"Sid": "SecretsManagerAccess",
"Effect": "Allow",
"Action": [
"secretsmanager:GetSecretValue",
"secretsmanager:DescribeSecret"
],
"Useful resource": [
"<SCRAM_SECRET_ARN>",
"<CERT_SECRET_ARN>"
]
},
{
"Sid": "KMSDecrypt",
"Impact": "Enable",
"Motion": "kms:Decrypt",
"Useful resource": "<SECRETSMANAGER_KMS_KEY_ARN>"
},
{
"Sid": "TargetClusterAccess",
"Impact": "Enable",
"Motion": [
"kafka-cluster:Connect",
"kafka-cluster:DescribeCluster",
"kafka-cluster:AlterCluster",
"kafka-cluster:DescribeClusterDynamicConfiguration",
"kafka-cluster:AlterClusterDynamicConfiguration",
"kafka-cluster:DescribeTopic",
"kafka-cluster:CreateTopic",
"kafka-cluster:AlterTopic",
"kafka-cluster:DescribeTopicDynamicConfiguration",
"kafka-cluster:AlterTopicDynamicConfiguration",
"kafka-cluster:WriteData",
"kafka-cluster:WriteDataIdempotently",
"kafka-cluster:ReadData",
"kafka-cluster:DescribeGroup",
"kafka-cluster:AlterGroup"
],
"Useful resource": [
"arn:aws:kafka:<REGION>:<ACCOUNT_ID>:cluster/<MSK_CLUSTER_NAME>*/*",
"arn:aws:kafka:<REGION>:<ACCOUNT_ID>:topic/<MSK_CLUSTER_NAME>/*",
"arn:aws:kafka:<REGION>:<ACCOUNT_ID>:group/<MSK_CLUSTER_NAME>*/*"
]
},
{
"Sid": "CloudWatchLogsAccess",
"Impact": "Enable",
"Motion": [
"logs:CreateLogStream",
"logs:PutLogEvents",
"logs:DescribeLogStreams"
],
"Useful resource": "<MSK_REPLICATOR_LOG_GROUP_ARN>"
}
]
}
Create the replicator for exterior to MSK replication
Use the AWS CLI, API, or Console to create your replicator. Right here’s an instance utilizing the AWS CLI:
aws kafka create-replicator
--replicator-name external-to-msk
--service-execution-role-arn "arn:aws:iam::123456789012:function/MSKReplicatorRole"
--kafka-clusters file://./kafka-clusters.json
--replication-info-list file://./replication-info.json
--log-delivery file://./log-delivery.json
--region us-east-1The kafka-clusters.json file defines the supply and goal Kafka cluster connection info, replication-info.json specifies which subjects to duplicate and the way to deal with shopper group offset synchronization, and log-delivery.json specifies the CloudWatch logging configuration. The next tables describe the required parameters:
CLI inputs:
| CLI Parameter | Description | Instance |
| replicator-name | The title of the replicator | external-to-msk |
| service-execution-role-arn | The ARN for the service execution IAM function you created | arn:aws:iam::123456789012:function/MSKReplicatorRole |
| kafka-clusters | The Kafka cluster connection data | See beneath |
| replication-info-list | The replication configuration | See beneath |
| log-delivery | The logging configuration | See beneath |
Key kafka-clusters.json inputs:
| CLI Parameter | Description | Instance |
| ApacheKafkaClusterId | The cluster ID retrieved in Step 2 | lkc-abc123 |
| RootCaCertificate | The Secrets and techniques Supervisor ARN containing the general public CA certificates and intermediate CA chain | arn:aws:secretsmanager:<REGION>:<ACCOUNT_ID>:secret:my-cert |
| MskClusterArn | The ARN for the MSK Specific cluster | arn:aws:kafka:<REGION>:<ACCOUNT_ID>:cluster/my-cluster/abc-123 |
| SecretArn | The Secrets and techniques Supervisor ARN containing the SASL/SCRAM username and password | arn:aws:secretsmanager:<REGION>:<ACCOUNT_ID>:secret:my-creds |
| SecurityGroupIds | The safety group IDs for MSK Replicator | sg-0123456789abcdef0 |
Key replication-info.json inputs:
| CLI Parameter | Description | Instance |
| TargetCompressionType | The compression kind to make use of for replicating information | LZ4 |
| TopicsToReplicate | The record of subjects to duplicate (use [“.*”] for all subjects) | [“my-topic”] |
| ConsumerGroupsToReplicate | The record of shopper teams to duplicate | [“my-group”] |
| StartingPosition | The purpose within the Kafka subjects to start replication from (both EARLIEST or LATEST) | EARLIEST |
| ConsumerGroupOffsetSyncMode | Whether or not or to not use enhanced bidirectional shopper group offset synchronization | ENHANCED |
Observe that startingPosition is about to EARLIEST within the configuration beneath, which implies the replicator begins studying from the oldest obtainable offset on every matter. That is the advisable setting for migrations to keep away from information loss.
Key log-delivery.json inputs:
| CLI Parameter | Description | Instance |
| Enabled | Means that you can allow CloudWatch logging | true |
| LogGroup | The CloudWatch logs log group title to log to | /msk/replicator/my-replicator |
Further log supply strategies for Amazon S3 and Amazon Knowledge Firehose are supported. On this publish, we use CloudWatch logging.
The configs ought to seem like the next for exterior to MSK replication.
kafka-clusters.json:
[
{
"ApacheKafkaCluster": {
"ApacheKafkaClusterId": "lkc-abc123",
"BootstrapBrokerString": "broker1.example.com:9096"
},
"ClientAuthentication": {
"SaslScram": {
"Mechanism": "SHA512",
"SecretArn": "arn:aws:secretsmanager:<REGION>:<ACCOUNT_ID>:secret:my-creds"
}
},
"EncryptionInTransit": {
"EncryptionType": "TLS",
"RootCaCertificate": "arn:aws:secretsmanager:<REGION>:<ACCOUNT_ID>:secret:my-cert"
}
},
{
"AmazonMskCluster": {
"MskClusterArn": "arn:aws:kafka:<REGION>:<ACCOUNT_ID>:cluster/my-cluster/abc-123"
},
"VpcConfig": {
"SecurityGroupIds": ["sg-0123456789abcdef0"],
"SubnetIds": ["subnet-abc123", "subnet-abc124", "subnet-abc125"]
}
}
] replication-info.json:
[
{
"SourceKafkaClusterId": "lkc-abc123",
"TargetKafkaClusterArn": "arn:aws:kafka:<REGION>:<ACCOUNT_ID>:cluster/my-cluster/abc-123",
"TargetCompressionType": "LZ4",
"TopicReplication": {
"TopicsToReplicate": ["my-topic"],
"CopyTopicConfigurations": true,
"CopyAccessControlListsForTopics": true,
"DetectAndCopyNewTopics": true,
"StartingPosition": {"Kind": "EARLIEST"},
"TopicNameConfiguration": {"Kind": "IDENTICAL"}
},
"ConsumerGroupReplication": {
"ConsumerGroupsToReplicate": ["my-group"],
"SynchroniseConsumerGroupOffsets": true,
"DetectAndCopyNewConsumerGroups": true,
"ConsumerGroupOffsetSyncMode": "ENHANCED"
}
}
] log-delivery.json:
{
"ReplicatorLogDelivery": {
"CloudWatchLogs": {
"Enabled": true,
"LogGroup": "<LOG_GROUP_NAME>"
}
}
}Configure bidirectional replication from MSK to the exterior cluster
To allow bidirectional replication, create a second replicator that replicates in the wrong way. Use the identical IAM function and community configuration from Step 4, however swap the supply and goal. Substitute SourceKafkaClusterId with TargetKafkaClusterId and TargetKafkaClusterArn with SourceKafkaClusterArn in a brand new msk-to-external-replication-info.json file:
aws kafka create-replicator
--replicator-name msk-to-external
--service-execution-role-arn "arn:aws:iam::123456789012:function/MSKReplicatorRole"
--kafka-clusters file:///./kafka-clusters.json
--replication-info-list file:///./msk-to-external-replication-info.json
--log-delivery file:///./log-delivery.json
--region us-east-1Monitoring replication well being
Monitor your replication utilizing Amazon CloudWatch metrics. Three key metrics to grasp are MessageLag, SumOffsetLag, and ReplicationLatency. MessageLag measures how far behind the replicator is from the exterior cluster when it comes to messages not but replicated, whereas SumOffsetLag measures how far behind a shopper group is from the newest message in a subject. ReplicationLatency is the quantity of latency between the supply and goal clusters in information replication. When the three attain a sustained low stage, your clusters are totally synchronized for each information and shopper group offsets.
To troubleshoot MSK Replicator replication or errors, use the CloudWatch logs to get extra particulars in regards to the well being of the replicator. MSK Replicator logs standing and troubleshooting info which could be useful in diagnosing points like connectivity, authentication, and SSL errors.
Observe that the replication is asynchronous, so there will likely be some lag throughout replication. The lag will attain zero as soon as a shopper is shut down throughout migration to the goal cluster. This takes about 30 seconds beneath regular operations, permitting a low downtime migration with out information loss. In case your lag is frequently rising or doesn’t attain a sustained low stage, this means that you’ve got inadequate partitions for high-throughput replication. Confer with Troubleshoot MSK Replicator for extra info on troubleshooting replication throughput and lag.
Key metrics embrace:
- MessageLag – Screens the sync between the MSK Replicator and the supply cluster. MessageLag signifies the lag between the messages produced to the supply cluster and messages consumed by the replicator. It isn’t the lag between the supply and goal cluster.
- ReplicationLatency – Time taken for data to duplicate from supply to focus on cluster (ms)
- ReplicatorThroughput – Common variety of bytes replicated per second
- ReplicatorFailure – Variety of failures the replicator is experiencing
- KafkaClusterPingSuccessCount – Connection well being indicator (1 = wholesome, 0 = unhealthy)
- ConsumerGroupCount – Complete shopper teams being synchronized
- ConsumerGroupOffsetSyncFailure – Failures throughout offset synchronization
- AuthError – Variety of connections with failed authentication per second, by cluster
- ThrottleTime – Common time in ms a request was throttled by brokers, by cluster
- SumOffsetLag – Aggregated offset lag throughout partitions for a shopper group on a subject (MSK cluster-level metric)
For extra particulars on these metrics, see the MSK Replicator metrics documentation.
Your functions are able to migrate when the next situations are met. For many workloads, it’s best to count on these metrics to stabilize inside a number of hours of beginning replication. Excessive-throughput clusters could take longer relying on matter quantity and partition rely.
- ReplicatorFailure = 0
- ConsumerGroupOffsetSyncFailure = 0
- KafkaClusterPingSuccessCount = 1 for each supply and goal clusters
- MessageLag < 1,000
- Your sustained lag could also be decrease or increased relying in your throughput per partition, message dimension, and different elements
- Sustained excessive message lag normally signifies inadequate partitions for high-throughput replication
- ReplicationLatency < 90 seconds
- Your sustained latency could also be decrease or increased relying in your throughput per partition, message dimension, and different elements
- Sustained excessive latency normally signifies inadequate partitions for high-throughput replication
- SumOffsetLag is at a sustained low stage on each clusters
- Offset values on the 2 clusters will not be numerically similar.
- MSK Replicator interprets offsets between clusters so that customers resume from the right place, however the uncooked offset numbers can differ because of how offset translation works. What issues is that SumOffsetLag is at a sustained low stage.
- ConsumerGroupCount (MSK) = Anticipated rely (exterior cluster)
- If ConsumerGroupCount is zero or doesn’t match the anticipated rely, then there is a matter within the Replicator configuration or a permissions problem stopping shopper group synchronization
Migrating your functions
With bidirectional shopper offset synchronization, you possibly can migrate your producers and customers no matter order. Begin by monitoring replication metrics till they attain the goal values described within the earlier part. Then migrate your functions (producers or customers) to make use of the MSK Specific cluster endpoints and confirm that they’re producing and consuming as anticipated. If you happen to encounter points, you possibly can roll again by switching functions again to the exterior cluster. The buyer offset synchronization makes positive that your functions resume from their final dedicated place no matter which cluster they hook up with.
For a complete, hands-on walkthrough of the end-to-end migration course of, discover the MSK Migration Workshop, which supplies step-by-step steerage for migrating your Kafka workloads to Amazon MSK.
Safety concerns
MSK Replicator makes use of SASL/SCRAM authentication with SSL encryption for safe information switch between your exterior cluster and AWS. The answer helps each publicly trusted certificates and personal or self-signed certificates. Credentials are saved securely in AWS Secrets and techniques Supervisor, and the goal MSK Specific cluster makes use of IAM authentication for entry management.
When configuring safety, hold the next in thoughts:
- Make it possible for the IAM function you create in Step 4 follows the precept of least privileges. Solely connect
AWSMSKReplicatorExecutionRoleand an IAM coverage for Secrets and techniques Supervisor with least-privileges entry to learn secret values and keep away from including broader permissions. - Confirm that your Secrets and techniques Supervisor secret is encrypted with an AWS KMS key that the MSK Replicator service execution function has permission to decrypt.
- Affirm that the safety teams assigned to MSK Replicator permit outbound visitors to your exterior cluster’s dealer ports (usually 9096 for SASL/SCRAM with TLS) and to the MSK Specific cluster.
- Rotate your SASL/SCRAM credentials periodically and replace the corresponding Secrets and techniques Supervisor secret. MSK Replicator picks up the brand new credentials robotically on the subsequent connection try.
Beneath the AWS shared accountability mannequin, AWS is accountable for securing the underlying infrastructure that runs MSK Replicator, together with the compute, storage, and networking sources. You might be accountable for configuring authentication mechanisms (SASL/SCRAM), managing credentials in AWS Secrets and techniques Supervisor, configuring community safety (safety teams and VPC settings), implementing IAM insurance policies following least privilege, and rotating credentials. For extra info, see Safety in Amazon MSK within the Amazon MSK Developer Information.
Cleanup
To keep away from ongoing prices, delete the sources you created throughout this walkthrough. Begin by deleting the replicators first, as a result of they depend upon the opposite sources:
aws kafka delete-replicator --replicator-arn <replicator-arn>
After each replicators are deleted, you possibly can take away the next sources in the event that they had been created solely for this walkthrough:
- The MSK Specific cluster (deleting a cluster additionally removes its saved information, so confirm that your functions have totally migrated earlier than continuing)
- The Secrets and techniques Supervisor secrets and techniques containing your SASL/SCRAM credentials and certificates
- The IAM function and insurance policies created for MSK Replicator
You’ll be able to confirm {that a} replicator has been totally deleted by working aws kafka list-replicators and confirming it now not seems within the output.
Conclusion
Amazon MSK Replicator simplifies the method of migrating to Amazon MSK Specific brokers and establishes hybrid Kafka architectures. The totally managed service alleviates the operational complexity of managing replication whereas bidirectional shopper offset synchronization allows versatile, low-risk software migration.
Subsequent Steps
To get began utilizing MSK Replicator emigrate functions to MSK Specific brokers, use the MSK Migration Workshop for a hands-on, end-to-end migration walkthrough. The Amazon MSK Replicator documentation consists of detailed configuration particulars to assist configure MSK Replicator to your use case. From there, use MSK Replicator emigrate your Apache Kafka workloads to MSK Specific dealer.
As soon as your migration is full, contemplate exploring multi-region replication patterns for catastrophe restoration, or integrating your MSK Specific cluster with AWS analytics providers akin to Amazon Knowledge Firehose and Amazon Athena. If you happen to need assistance planning your migration, attain out to your AWS account crew, AWS Assist or AWS Skilled Companies.