

{kind=link}
Validating Kafka configurations earlier than manufacturing deployment may be difficult. On this submit, we introduce the workload simulation workbench for Amazon Managed Streaming for Apache Kafka (Amazon MSK) Categorical Dealer. The simulation workbench is a instrument that you should utilize to securely validate your streaming configurations by way of sensible testing situations.
Answer overview
Various message sizes, partition methods, throughput necessities, and scaling patterns make it difficult so that you can predict how your Apache Kafka configurations will carry out in manufacturing. The standard approaches to check these variables create important limitations: ad-hoc testing lacks consistency, guide arrange of momentary clusters is time-consuming and error-prone, production-like environments require devoted infrastructure groups, and group coaching usually occurs in isolation with out sensible situations. You want a structured approach to take a look at and validate these configurations safely earlier than deployment. The workload simulation workbench for MSK Categorical Dealer addresses these challenges by offering a configurable, infrastructure as code (IaC) answer utilizing AWS Cloud Improvement Equipment (AWS CDK) deployments for sensible Apache Kafka testing. The workbench helps configurable workload situations, and real-time efficiency insights.
Categorical brokers for MSK Provisioned make managing Apache Kafka extra streamlined, less expensive to run at scale, and extra elastic with the low latency that you just count on. Every dealer node can present as much as 3x extra throughput per dealer, scale as much as 20x quicker, and recuperate 90% faster in comparison with customary Apache Kafka brokers. The workload simulation workbench for Amazon MSK Categorical dealer facilitates systematic experimentation with constant, repeatable outcomes. You should use the workbench for a number of use instances like manufacturing capability planning, progressive coaching to organize builders for Apache Kafka operations with growing complexity, and structure validation to show streaming designs and evaluate totally different approaches earlier than making manufacturing commitments.
Structure overview
The workbench creates an remoted Apache Kafka testing setting in your AWS account. It deploys a non-public subnet the place client and producer purposes run as containers, connects to a non-public MSK Categorical dealer and displays for efficiency metrics and visibility. This structure mirrors the manufacturing deployment sample for experimentation. The next picture describes this structure utilizing AWS companies.
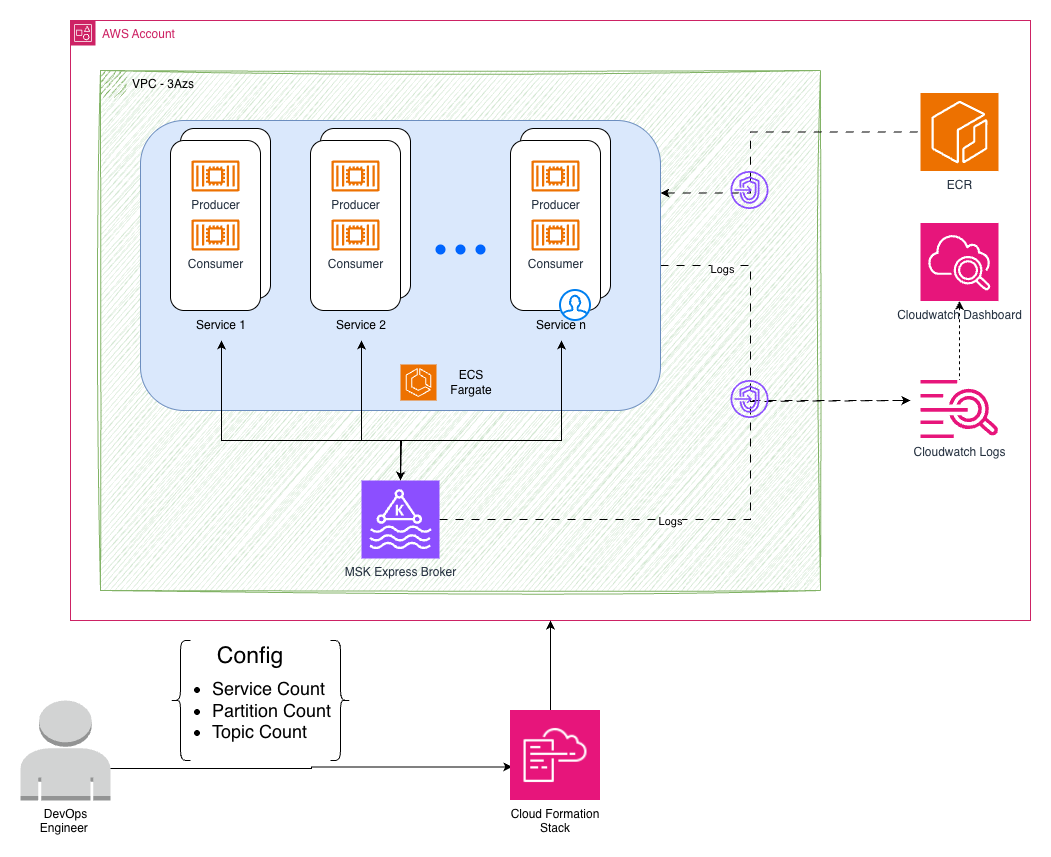
This structure is deployed utilizing the next AWS companies:
Amazon Elastic Container Service (Amazon ECS) generate configurable workloads with Java-based producers and customers, simulating numerous real-world situations by way of totally different message sizes and throughput patterns.
Amazon MSK Categorical Cluster runs Apache Kafka 3.9.0 on Graviton-based situations with hands-free storage administration and enhanced efficiency traits.
Dynamic Amazon CloudWatch Dashboards mechanically adapt to your configuration, displaying real-time throughput, latency, and useful resource utilization throughout totally different take a look at situations.
Safe Amazon Digital Personal Cloud (Amazon VPC) Infrastructure offers non-public subnets throughout three Availability Zones with VPC endpoints for safe service communication.
Configuration-driven testing
The workbench offers totally different configuration choices in your Apache Kafka testing setting, so you may customise occasion varieties, dealer rely, subject distribution, message traits, and ingress price. You possibly can modify the variety of subjects, partitions per subject, sender and receiver service situations, and message sizes to match your testing wants. These versatile configurations help two distinct testing approaches to validate totally different features of your Kafka deployment:
Strategy 1: Workload validation (single deployment)
Take a look at totally different workload patterns towards the identical MSK Categorical cluster configuration. That is helpful for evaluating partition methods, message sizes, and cargo patterns.
Strategy 2: Infrastructure rightsizing (redeploy and evaluate)
Take a look at totally different MSK Categorical cluster configurations by redeploying the workbench with totally different dealer settings whereas conserving the identical workload. That is advisable for rightsizing experiments and understanding the impression of vertical in comparison with horizontal scaling.
Every redeployment makes use of the identical workload configuration, so you may isolate the impression of infrastructure modifications on efficiency.
Workload testing situations (single deployment)
These situations take a look at totally different workload patterns towards the identical MSK Categorical cluster:
Partition technique impression testing
Situation: You might be debating the utilization of fewer subjects with many partitions in comparison with many subjects with fewer partitions in your microservices structure. You need to perceive how partition rely impacts throughput and client group coordination earlier than making this architectural determination.
Message measurement efficiency evaluation
Situation: Your software handles various kinds of occasions – small IoT sensor readings (256 bytes), medium consumer exercise occasions (1 KB), and enormous doc processing occasions (8KB). You will need to perceive how message measurement impacts your general system efficiency and in case you ought to separate these into totally different subjects or deal with them collectively.
Load testing and scaling validation
Situation: You count on site visitors to fluctuate considerably all through the day, with peak hundreds requiring 10× extra processing capability than off-peak hours. You need to validate how your Apache Kafka subjects and partitions deal with totally different load ranges and perceive the efficiency traits earlier than manufacturing deployment.
Infrastructure rightsizing experiments (redeploy and evaluate)
These situations enable you perceive the impression of various MSK Categorical cluster configurations by redeploying the workbench with totally different dealer settings:
MSK dealer rightsizing evaluation
Situation: You deploy a cluster with fundamental configuration and put load on it to determine baseline efficiency. Then you definitely need to experiment with totally different dealer configurations to see the impact of vertical scaling (bigger situations) and horizontal scaling (extra brokers) to search out the proper cost-performance steadiness in your manufacturing deployment.
Step 1: Deploy with baseline configuration
Step 2: Redeploy with vertical scaling
Step 3: Redeploy with horizontal scaling
This rightsizing method helps you perceive how dealer configuration modifications have an effect on the identical workload, so you may enhance each efficiency and price in your particular necessities.
Efficiency insights
The workbench offers detailed insights into your Apache Kafka configurations by way of monitoring and analytics, making a CloudWatch dashboard that adapts to your configuration. The dashboard begins with a configuration abstract displaying your MSK Categorical cluster particulars and workbench service configurations, serving to you to grasp what you’re testing. The next picture exhibits the dashboard configuration abstract:

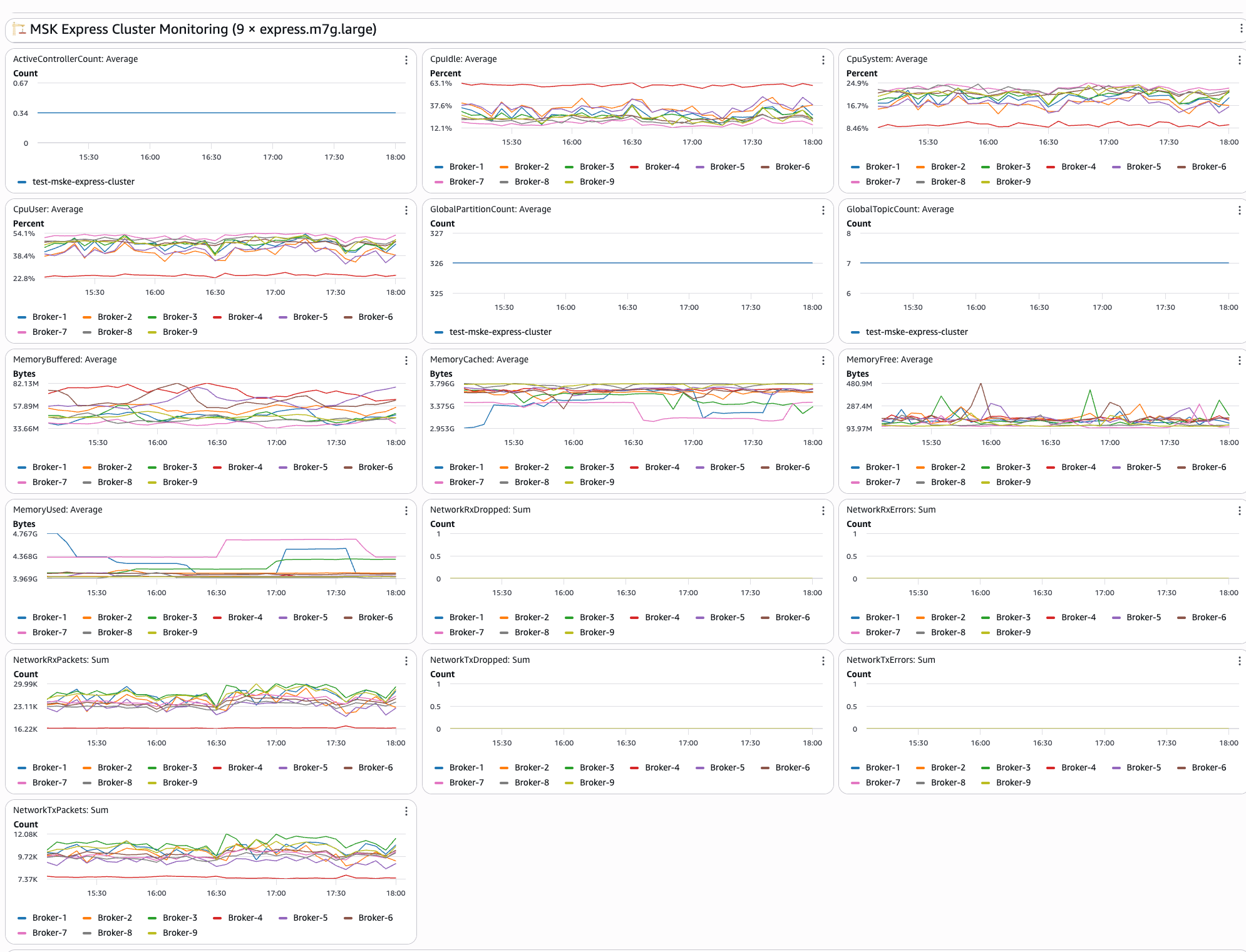
The second part of dashboard exhibits real-time MSK Categorical cluster metrics together with:
- Dealer efficiency: CPU utilization and reminiscence utilization throughout brokers in your cluster
- Community exercise: Monitor bytes in/out and packet counts per dealer to grasp community utilization patterns
- Connection monitoring: Shows energetic connections and connection patterns to assist establish potential bottlenecks
- Useful resource utilization: Dealer-level useful resource monitoring offers insights into general cluster well being
The next picture exhibits the MSK cluster monitoring dashboard:
The third part of the dashboard exhibits the Clever Rebalancing and Cluster Capability insights displaying:
- Clever rebalancing: in progress: Exhibits whether or not a rebalancing operation is at present in progress or has occurred prior to now. A price of 1 signifies that rebalancing is actively working, whereas 0 signifies that the cluster is in a gradual state.
- Cluster under-provisioned: Signifies whether or not the cluster has inadequate dealer capability to carry out partition rebalancing. A price of 1 signifies that the cluster is under-provisioned and Clever Rebalancing can’t redistribute partitions till extra brokers are added or the occasion sort is upgraded.
- World partition rely: Shows the full variety of distinctive partitions throughout all subjects within the cluster, excluding replicas. Use this to trace partition development over time and validate your deployment configuration.
- Chief rely per dealer: Exhibits the variety of chief partitions assigned to every dealer. An uneven distribution signifies partition management skew, which may result in hotspots the place sure brokers deal with disproportionate learn/write site visitors.
- Partition rely per dealer: Exhibits the full variety of partition replicas hosted on every dealer. This metric consists of each chief and follower replicas and is vital to figuring out duplicate distribution imbalances throughout the cluster.
The next picture exhibits the Clever Rebalancing and Cluster Capability part of the dashboard:
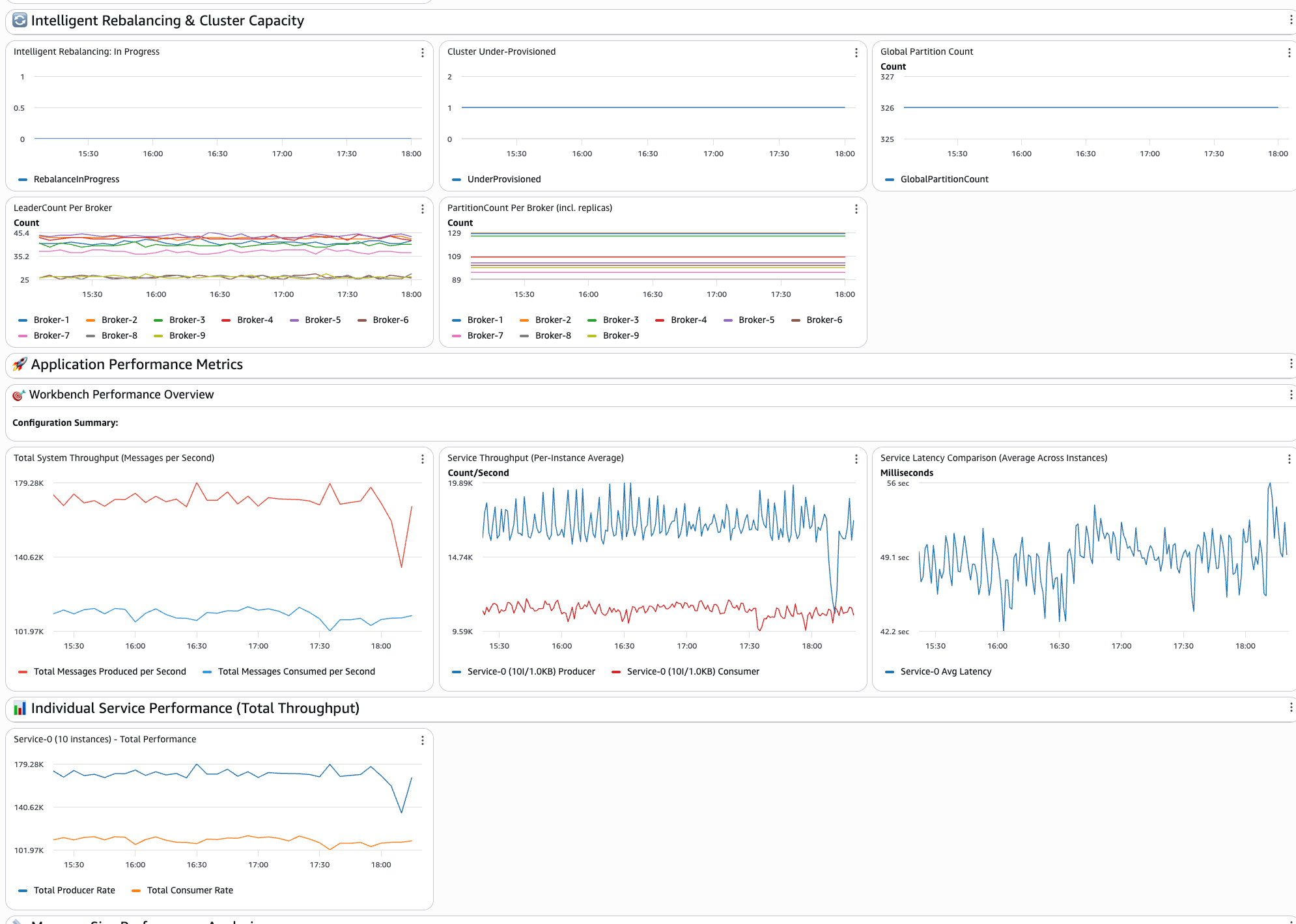
The fourth part of the dashboard exhibits the application-level insights displaying:
- System throughput: Shows the full variety of messages per second throughout companies, providing you with an entire view of system efficiency
- Service comparisons: Performs side-by-side efficiency evaluation of various configurations to grasp which approaches match
- Particular person service efficiency: Every configured service has devoted throughput monitoring widgets for detailed evaluation
- Latency evaluation: The top-to-end message supply instances and latency comparisons throughout totally different service configurations
- Message measurement impression: Efficiency evaluation throughout totally different payload sizes helps you perceive how message measurement impacts general system habits
The next picture exhibits the appliance efficiency metrics part of the dashboard:
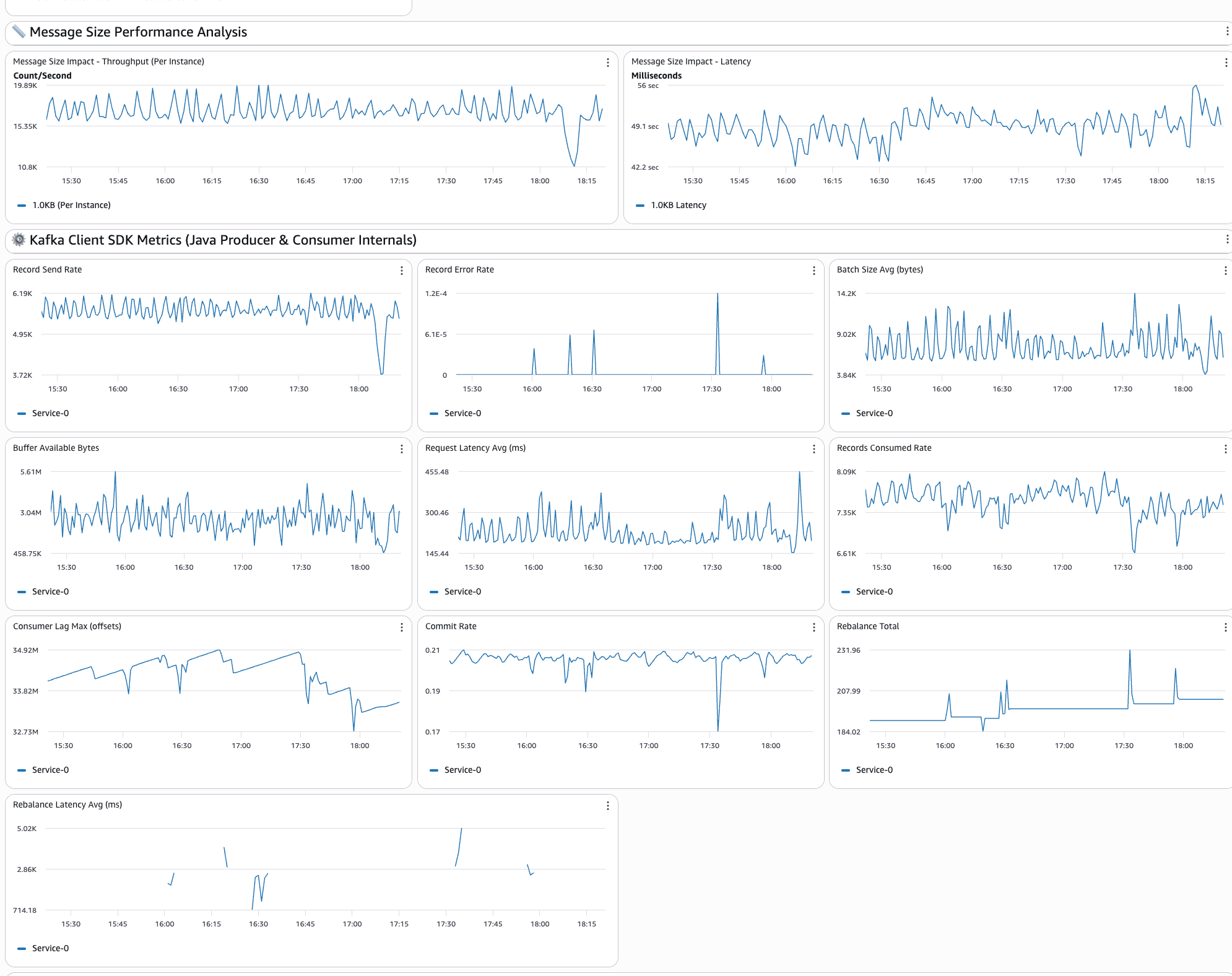
Getting began
This part walks you thru establishing and deploying the workbench in your AWS setting. You’ll configure the required stipulations, deploy the infrastructure utilizing AWS CDK, and customise your first take a look at.
Stipulations
You possibly can deploy the answer from the GitHub Repo. You possibly can clone it and run it in your AWS setting. To deploy the artifacts, you’ll require:
- AWS account with administrative credentials configured for creating AWS sources.
- AWS Command Line Interface (AWS CLI) should be configured with applicable permissions for AWS useful resource administration.
- AWS Cloud Improvement Equipment (AWS CDK) ought to be put in globally utilizing npm set up -g aws-cdk for infrastructure deployment.
- Node.js model 20.9 or increased is required, with model 22+ advisable.
- Docker engine should be put in and working regionally because the CDK builds container photographs throughout deployment. Docker daemon ought to be working and accessible to CDK for constructing the workbench software containers.
Deployment
After deployment is accomplished, you’ll obtain a CloudWatch dashboard URL to watch the workbench efficiency in real-time.You can even deploy a number of remoted situations of the workbench in the identical AWS account for various groups, environments, or testing situations. Every occasion operates independently with its personal MSK cluster, ECS companies, and CloudWatch dashboards.To deploy further situations, modify the Atmosphere Configuration in cdk/lib/config.ts:
Every mixture of AppPrefix and EnvPrefix creates utterly remoted AWS sources in order that a number of groups or environments can use the workbench concurrently with out conflicts.
Customizing your first take a look at
You possibly can edit the configuration file situated at folder “cdk/lib/config-types.ts” to outline your testing situations and run the deployment. It’s preconfigured with the next configuration:
Greatest practices
Following a structured method to benchmarking ensures that your outcomes are dependable and actionable. These greatest practices will enable you isolate efficiency variables and construct a transparent understanding of how every configuration change impacts your system’s habits. Start with single-service configurations to determine baseline efficiency:
After you perceive the baseline, add comparability situations.
Change one variable at a time
For clear insights, modify just one parameter between companies:
This method helps you perceive the impression of particular configuration modifications.
Vital issues and limitations
Earlier than counting on workbench outcomes for manufacturing selections, it is very important perceive the instrument’s meant scope and bounds. The next issues will enable you set applicable expectations and make the best use of the workbench in your planning course of.
Efficiency testing disclaimer
The workbench is designed as an academic and sizing estimation instrument to assist groups put together for MSK Categorical manufacturing deployments. Whereas it offers priceless insights into efficiency traits:
- Outcomes can fluctuate primarily based in your particular use instances, community situations, and configurations
- Use workbench outcomes as steering for preliminary sizing and planning
- Conduct complete efficiency validation along with your precise workloads in production-like environments earlier than last deployment
Beneficial utilization method
Manufacturing readiness coaching – Use the workbench to organize groups for MSK Categorical capabilities and operations.
Structure validation – Take a look at streaming architectures and efficiency expectations utilizing MSK Categorical enhanced efficiency traits.
Capability planning – Use MSK Categorical streamlined sizing method (throughput-based slightly than storage-based) for preliminary estimates.
Crew preparation – Construct confidence and experience with manufacturing Apache Kafka implementations utilizing MSK Categorical.
Conclusion
On this submit, we confirmed how the workload simulation workbench for Amazon MSK Categorical Dealer helps studying and preparation for manufacturing deployments by way of configurable, hands-on testing and experiments. You should use the workbench to validate configurations, construct experience, and enhance efficiency earlier than manufacturing deployment. In case you’re getting ready in your first Apache Kafka deployment, coaching a group, or enhancing current architectures, the workbench offers sensible expertise and insights wanted for fulfillment. Check with Amazon MSK documentation – Full MSK Categorical documentation, greatest practices, and sizing steering for extra info.