

Over time, organizations have invested in creating purpose-built, cloud-based knowledge lakes which might be siloed from each other. A significant problem is enabling cross-organization discovery and entry to knowledge throughout these a number of knowledge lakes, every constructed on totally different know-how stacks. A knowledge mesh addresses these points with 4 rules: domain-oriented decentralized knowledge possession and structure, treating knowledge as a product, offering self-serve knowledge infrastructure as a platform, and implementing federated governance. Knowledge mesh permits organizations to prepare round knowledge domains with a concentrate on delivering knowledge as a product.
In 2019, Volkswagen AG (VW) and Amazon Internet Companies (AWS) fashioned a strategic partnership to co-develop the Digital Manufacturing Platform (DPP), aiming to boost manufacturing and logistics effectivity by 30 % whereas decreasing manufacturing prices by the identical margin. The DPP was developed to streamline entry to knowledge from shop-floor units and manufacturing methods by dealing with integrations and offering standardized interfaces. Nevertheless, as functions developed on the platform, a big problem emerged: sharing knowledge throughout functions saved in a number of remoted knowledge lakes in Amazon Easy Storage Service (Amazon S3) buckets in particular person AWS accounts with out having to consolidate knowledge right into a central knowledge lake. One other problem is discovering accessible knowledge saved throughout a number of knowledge lakes and facilitating a workflow to request knowledge entry throughout enterprise domains inside every plant. The present technique is essentially guide, counting on emails and basic communication, which not solely will increase overhead but additionally varies from one use case to a different by way of knowledge governance. This weblog put up introduces Amazon DataZone and explores how VW used it to construct their knowledge mesh to allow streamlined knowledge entry throughout a number of knowledge lakes. It focuses on the important thing facet of the answer, which was enabling knowledge suppliers to robotically publish knowledge property to Amazon DataZone, which served because the central knowledge mesh for enhanced knowledge discoverability. Moreover, the put up offers code to information you thru the implementation.
Introduction to Amazon DataZone
Amazon DataZone is a knowledge administration service that makes it quicker and simpler for purchasers to catalog, uncover, share, and govern knowledge saved throughout AWS, on premises, and third-party sources. Key options of Amazon DataZone embrace a enterprise knowledge catalog that permits customers to seek for revealed knowledge, request entry, and begin engaged on knowledge in days as an alternative of weeks. Amazon DataZone tasks allow collaboration with groups by way of knowledge property and the flexibility to handle and monitor knowledge property throughout tasks. It additionally contains the Amazon DataZone portal, which gives a customized analytics expertise for knowledge property by way of a web-based software or API. Lastly, Amazon DataZone ruled knowledge sharing ensures that the suitable knowledge is accessed by the suitable consumer for the suitable goal with a ruled workflow.
Structure for Knowledge Administration with Amazon DataZone
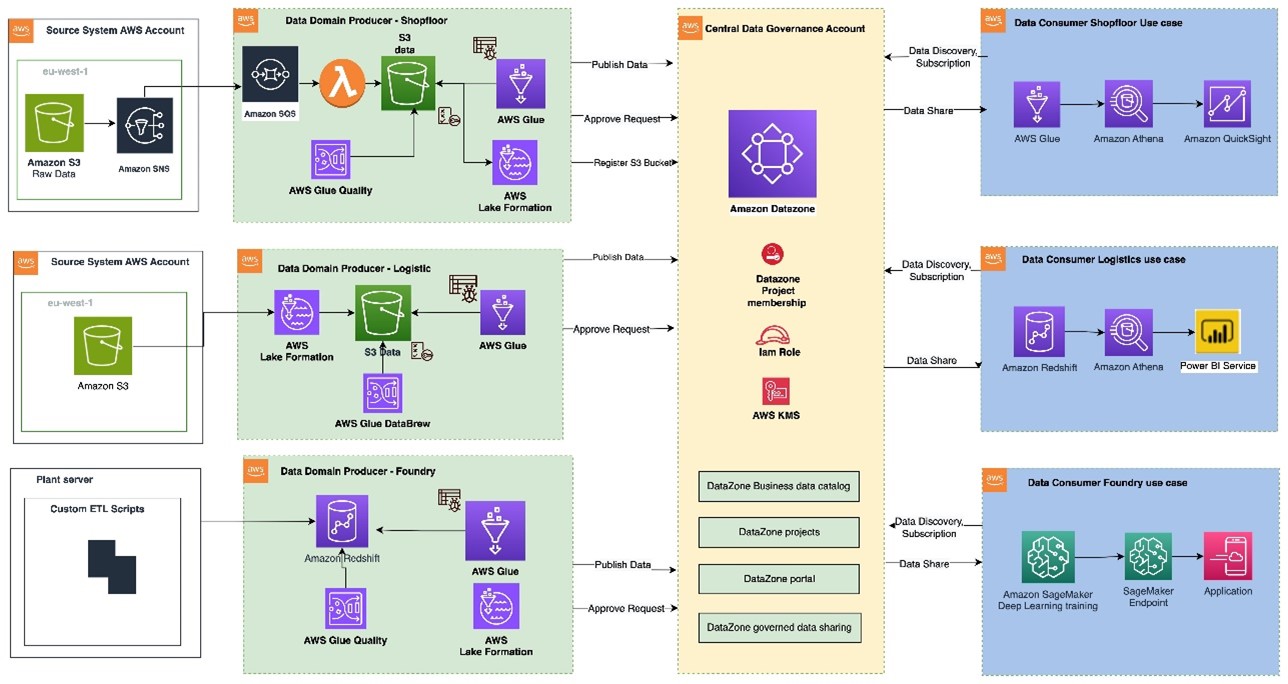
Determine 1: Knowledge mesh sample implementation on AWS utilizing Amazon DataZone
The structure diagram (Determine 1) represents a high-level design based mostly on the information mesh sample. It separates supply methods, knowledge area producers (knowledge publishers), knowledge area customers (knowledge subscribers), and central governance to spotlight key elements. This cross-account knowledge mesh structure goals to create a scalable basis for knowledge platforms, supporting producers and customers with constant governance.
- An information area producer resides in an AWS account and makes use of Amazon S3 buckets to retailer uncooked and remodeled knowledge. Producers ingest knowledge into their S3 buckets by way of pipelines they handle, personal, and function. They’re liable for the total lifecycle of the information, from uncooked seize to a kind appropriate for exterior consumption.
- An information area producer maintains its personal ETL stack utilizing AWS Glue, AWS Lambda to course of, AWS Glue Databrew to profile the information and put together the information asset (knowledge product) earlier than cataloguing it into AWS Glue Knowledge Catalog of their account.
- A second sample might be {that a} knowledge area producer prepares and shops the information asset as desk inside Amazon Redshift utilizing AWS S3 Copy.
- Knowledge area producers publish knowledge property utilizing datasource run to Amazon DataZone within the Central Governance account. This populates the technical metadata within the enterprise knowledge catalog for every knowledge asset. The enterprise metadata, will be added by enterprise customers to offer enterprise context, tags, and knowledge classification for the datasets. Producers management what to share, for the way lengthy, and the way customers work together with it.
- Producers can register and create catalog entries with AWS Glue from all their S3 buckets. The central governance account securely shares datasets between producers and customers through metadata linking, with no knowledge (besides logs) current on this account. Knowledge possession stays with the producer.
- With Amazon DataZone, as soon as knowledge is cataloged and revealed into the DataZone area, it may be shared with a number of client accounts.
- The Amazon DataZone Knowledge portal offers a customized view for customers to find/search and submit requests for subscription of information property utilizing a web-based software. The info area producer receives the notification of subscription requests within the Knowledge portal and might approve/reject the requests.
- As soon as accepted, the patron account can learn and additional course of knowledge property to implement numerous use circumstances with AWS Lambda, AWS Glue, Amazon Athena, Amazon Redshift question editor v2, Amazon QuickSight (Analytics use circumstances) and with Amazon Sagemaker (Machine studying use circumstances).
Handbook course of to publish knowledge property to Amazon DataZone
To publish a knowledge asset from the producer account, every asset should be registered in Amazon DataZone as a knowledge supply for client subscription. The Amazon DataZone Person Information offers detailed steps to attain this. Within the absence of an automatic registration course of, all required duties should be accomplished manually for every knowledge asset.
The right way to automate publishing knowledge property from AWS Glue Knowledge Catalog from the producer account to Amazon DataZone
Utilizing the automated registration workflow, the guide steps will be automated for any new knowledge asset that must be revealed in an Amazon DataZone area or when there’s a schema change in an already revealed knowledge asset.
The automated resolution reduces the repetitive guide steps to publish the information sources (AWS Glue tables) into an Amazon DataZone area.
Structure for automated knowledge asset publish
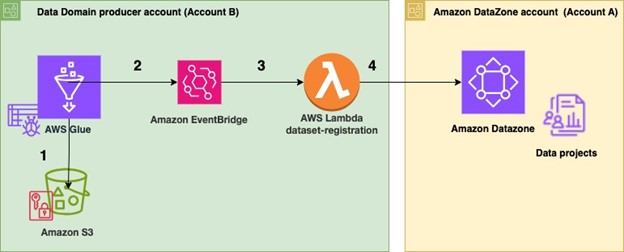
Determine 2 Structure for automated knowledge publish to Amazon DataZone
To automate publishing knowledge property:
- Within the producer account (Account B), the information to be shared resides in an Amazon S3 bucket (Determine 2). An AWS Glue crawler is configured for the dataset to robotically create the schema utilizing AWS Cloud Growth Package (AWS CDK).
- As soon as configured, the AWS Glue crawler crawls the Amazon S3 bucket and updates the metadata within the AWS Glue Knowledge Catalog. The profitable completion of the AWS Glue crawler generates an occasion within the default occasion bus of Amazon EventBridge.
- An EventBridge rule is configured to detect this occasion and invoke a dataset-registration AWS Lambda operate.
- The AWS Lambda operate performs all of the steps to robotically register and publish the dataset in Amazon Datazone.
Steps carried out within the dataset-registration AWS Lambda operate
- The AWS Lambda operate retrieves the AWS Glue database and Amazon S3 data for the dataset from the Amazon Eventbridge occasion triggered by the profitable run of the AWS Glue crawler.
- It obtains the Amazon DataZone Datalake blueprint ID from the producer account and the Amazon DataZone area ID and mission ID by assuming an IAM position within the central governance account the place the Amazon Datazone area exists.
- It permits the Amazon DataZone Datalake blueprint within the producer account.
- It checks if the Amazon Datazone setting already exists throughout the Amazon DataZone mission. If it doesn’t, then it initiates the setting creation course of. If the setting exists, it proceeds to the following step.
- It registers the Amazon S3 location of the dataset in Lake Formation within the producer account.
- The operate creates a knowledge supply throughout the Amazon DataZone mission and screens the completion of the information supply creation.
- Lastly, it checks whether or not the information supply sync job in Amazon DataZone must be began. If new AWS Glue tables or metadata is created or up to date, then it begins the information supply sync job.
Stipulations
As a part of this resolution, you’ll publish knowledge property from an current AWS Glue database in a producer account into an Amazon DataZone area for which the next conditions should be carried out.
- You want two AWS accounts to deploy the answer.
- One AWS account will act as the information area producer account (Account B) which is able to comprise the AWS Glue dataset to be shared.
- The second AWS account is the central governance account (Account A), which could have the Amazon DataZone area and mission deployed. That is the Amazon DataZone account.
- Be sure that each the AWS accounts belong to the identical AWS Group
- Take away the IAMAllowedPrincipals permissions from the AWS Lake Formation tables for which Amazon DataZone handles permissions.
- Ensure in each AWS accounts that you’ve got cleared the checkbox for Default permissions for newly created databases and tables underneath the Knowledge Catalog settings in Lake Formation (Determine 3).

Determine 3: Clear default permissions in AWS Lake Formation
- Check in to Account A (central governance account) and be sure you have created an Amazon DataZone area and a mission throughout the area.
- In case your Amazon DataZone area is encrypted with an AWS Key Administration Service (AWS KMS) key, add Account B (producer account) to the important thing coverage with the next actions:
- Guarantee you might have created an AWS Id and Entry Administration (IAM) position that Account B (producer account) can assume and this IAM position is added as a member (as contributor) of your Amazon DataZone mission. The position ought to have the next permissions:
- This IAM position known as
dz-assumable-env-dataset-registration-roleon this instance. Including this position will allow you to efficiently run thedataset-registrationLambda operate. Change theaccount-region,account id, andDataZonekmsKeywithin the following coverage together with your data. These values correspond to the place your Amazon DataZone area is created and the AWS KMS key Amazon Useful resource Identify (ARN) used to encrypt the Amazon DataZone area. - Add the AWS account within the belief relationship of this position with the next belief relationship. Change
ProducerAccountIdwith the AWS account ID of Account B (knowledge area producer account).
- This IAM position known as
- The next instruments are wanted to deploy the answer utilizing AWS CDK:
Deployment Steps
After finishing the pre-requisites, use the AWS CDK stack supplied on GitHub to deploy the answer for computerized registration of information property into DataZone area
- Clone the repository from GitHub to your most well-liked IDE utilizing the next instructions.
- On the base of the repository folder, run the next instructions to construct and deploy assets to AWS.
- Check in to the AWS account B (the information area producer account) utilizing AWS Command Line Interface (AWS CLI) together with your profile title.
- Guarantee you might have configured the AWS Area in your credential’s configuration file.
- Bootstrap the CDK setting with the next instructions on the base of the repository folder. Change
<PROFILE_NAME>with the profile title of your deployment account (Account B). Bootstrapping is a one-time exercise and isn’t wanted in case your AWS account is already bootstrapped. - Change the placeholder parameters (marked with the suffix
_PLACEHOLDER) within the fileconfig/DataZoneConfig.ts(Determine 4).
- Amazon DataZone area and mission title of your Amazon DataZone occasion. Ensure all names are in lowercase.
- The AWS account ID and Area.
- The assumable IAM position from the conditions.
- The deployment position beginning with
cfn-xxxxxx-cdk-exec-role-.
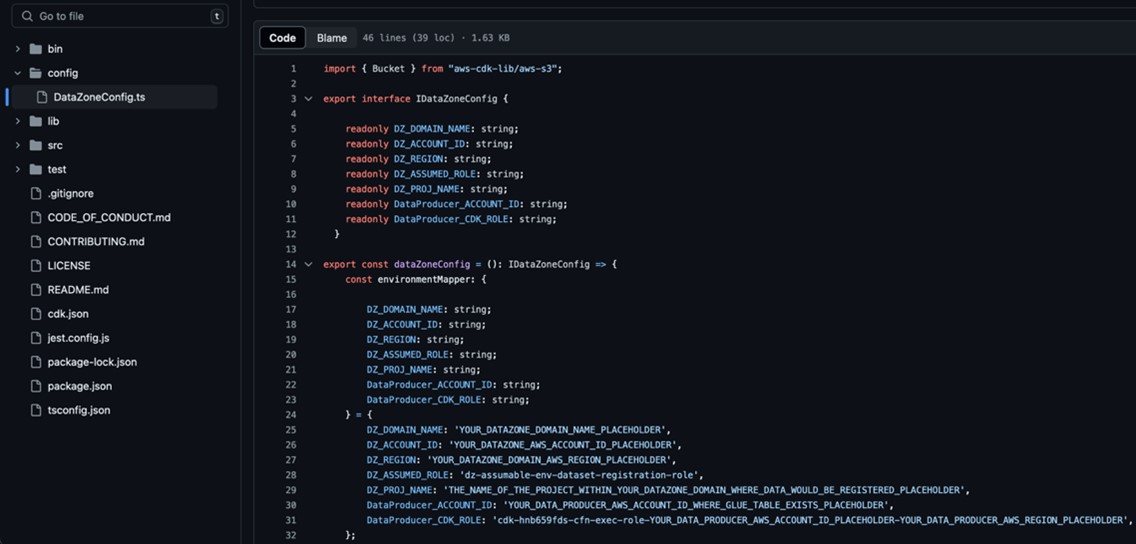
Determine 4: Edit the DataZoneConfig file
- Within the AWS Administration Console for Lake Formation, choose Administrative roles and duties from the navigation pane (Determine 5) and ensure the IAM position for AWS CDK deployment that begins with
cfn-xxxxxx-cdk-exec-role-is chosen as an administrator in Knowledge lake directors. This IAM position wants permissions in Lake Formation to create assets, corresponding to an AWS Glue database. With out these permissions, the AWS CDK stack deployment will fail.
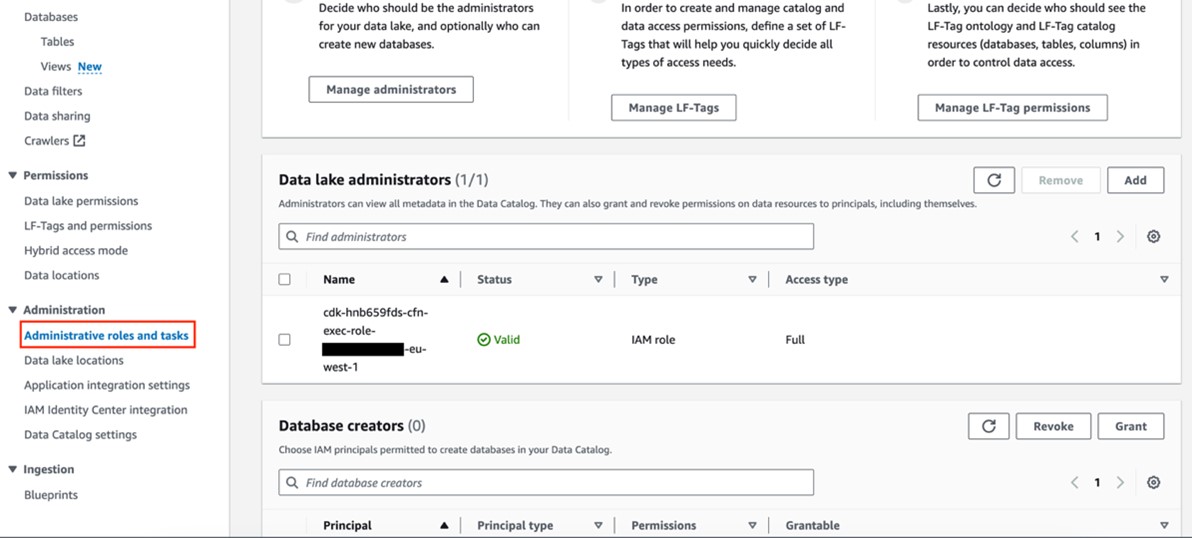
Determine 5: Add cfn-xxxxxx-cdk-exec-role- as a Knowledge Lake administrator
- Use the next command within the base folder to deploy the AWS CDK resolution
Throughout deployment, enter y if you wish to deploy the adjustments for some stacks if you see the immediate Do you want to deploy these adjustments (y/n)?
- After the deployment is full, register to your AWS account B (producer account) and navigate to the AWS CloudFormation console to confirm that the infrastructure deployed. It is best to see a listing of the deployed CloudFormation stacks as proven in Determine 6.
Determine 6: Deployed CloudFormation stacks
Check computerized knowledge registration to Amazon DataZone
To check, we use the On-line Retail Transactions dataset from Kaggle as a pattern dataset to display the automated knowledge registration.
- Obtain the On-line Retail.csv file from Kaggle dataset.
- Login to AWS Account B (producer account) and navigate to the Amazon S3 console, discover the
DataZone-test-datasourceS3 bucket, and add the csv file there (Determine 7).
Determine 7: Add the dataset CSV file
- The AWS Glue crawler is scheduled to run at a particular time every day. Nevertheless for testing, you may manually run the crawler by going to the AWS Glue console and deciding on Crawlers from the navigation pane. Run the on-demand crawler beginning with
DataZone-. After the crawler has run, confirm {that a} new desk has been created. - Go to the Amazon DataZone console in AWS account A (central governance account) the place you deployed the assets. Choose Domains within the navigation pane (Determine 8), then Choose and open your area.

Determine 8: Amazon DataZone domains
- After you open the Datazone Area, you’ll find the Amazon Datazone knowledge portal URL within the Abstract part (Determine 9). Choose and open knowledge portal.

Determine 9: Amazon DataZone knowledge portal URL
- Within the knowledge portal discover your mission (Determine 10). Then choose the Knowledge tab on the prime of the window.

Determine 10: Amazon DataZone Venture overview
- Choose the part Knowledge Sources (Determine 11) and discover the newly created knowledge supply DataZone-testdata-db.

Determine 11: Choose Knowledge sources within the Amazon Datazone Area Knowledge portal
- Confirm that the information supply has been efficiently revealed (Determine 12).

Determine 12: The info sources are seen within the Revealed knowledge part
- After the information sources are revealed, customers can uncover the revealed knowledge and might submit a subscription request. The info producer can approve or reject requests. Upon approval, customers can devour the information by querying knowledge in Amazon Athena. Determine 13 illustrates knowledge discovery within the Amazon DataZone knowledge portal.

Determine 13: Instance knowledge discovery within the Amazon DataZone portal






{kind=link}
Clear up
Use the next steps to scrub up the assets deployed by way of the CDK.
- Empty the 2 S3 buckets that had been created as a part of this deployment.
- Go to the Amazon DataZone area portal and delete the revealed knowledge property that had been created within the Amazon DataZone mission by the
dataset-registrationLambda operate. - Delete the remaining assets created utilizing the next command within the base folder:
Conclusion
Through the use of AWS Glue and Amazon DataZone, organizations could make their knowledge administration simpler and permit groups to share and collaborate on knowledge easily. Robotically sending AWS Glue knowledge to Amazon DataZone not solely makes the method easy but additionally retains the information constant, safe, and well-governed. Simplify and standardize publishing knowledge property to Amazon DataZone and streamline knowledge administration with Amazon DataZone. For steerage on establishing your group’s knowledge mesh with Amazon DataZone, contact your AWS staff immediately.
Concerning the Authors
 Bandana Das is a Senior Knowledge Architect at Amazon Internet Companies and makes a speciality of knowledge and analytics. She builds event-driven knowledge architectures to assist prospects in knowledge administration and data-driven decision-making. She can be captivated with enabling prospects on their knowledge administration journey to the cloud.
Bandana Das is a Senior Knowledge Architect at Amazon Internet Companies and makes a speciality of knowledge and analytics. She builds event-driven knowledge architectures to assist prospects in knowledge administration and data-driven decision-making. She can be captivated with enabling prospects on their knowledge administration journey to the cloud.
 Anirban Saha is a DevOps Architect at AWS, specializing in architecting and implementation of options for buyer challenges within the automotive area. He’s captivated with well-architected infrastructures, automation, data-driven options and serving to make the shopper’s cloud journey as seamless as attainable. Personally, he likes to maintain himself engaged with studying, portray, language studying and touring.
Anirban Saha is a DevOps Architect at AWS, specializing in architecting and implementation of options for buyer challenges within the automotive area. He’s captivated with well-architected infrastructures, automation, data-driven options and serving to make the shopper’s cloud journey as seamless as attainable. Personally, he likes to maintain himself engaged with studying, portray, language studying and touring.
 Chandana Keswarkar is a Senior Options Architect at AWS, who makes a speciality of guiding automotive prospects by way of their digital transformation journeys by utilizing cloud know-how. She helps organizations develop and refine their platform and product architectures and make well-informed design selections. In her free time, she enjoys touring, studying, and training yoga.
Chandana Keswarkar is a Senior Options Architect at AWS, who makes a speciality of guiding automotive prospects by way of their digital transformation journeys by utilizing cloud know-how. She helps organizations develop and refine their platform and product architectures and make well-informed design selections. In her free time, she enjoys touring, studying, and training yoga.
 Sindi Cali is a ProServe Affiliate Advisor with AWS Skilled Companies. She helps prospects in constructing knowledge pushed functions in AWS.
Sindi Cali is a ProServe Affiliate Advisor with AWS Skilled Companies. She helps prospects in constructing knowledge pushed functions in AWS.