

{kind=link}
In Getting began with Apache Iceberg write assist in Amazon Redshift – half 1, you discovered how one can create Apache Iceberg tables and write information instantly from Amazon Redshift to your information lake. You arrange exterior schemas, created tables in each Amazon Easy Storage Service (Amazon S3) and S3 Tables, and carried out INSERT operations whereas sustaining ACID (Atomicity, Consistency, Isolation, Sturdiness) compliance.
Amazon Redshift now helps DELETE, UPDATE, and MERGE operations for Apache Iceberg tables saved in Amazon S3 and Amazon S3 desk buckets. With these operations, you’ll be able to modify information on the row degree, implement upsert patterns, and handle the info lifecycle whereas sustaining transactional consistency utilizing acquainted SQL syntax. You possibly can run complicated transformations in Amazon Redshift and write outcomes to Apache Iceberg tables that different analytics engines like Amazon EMR or Amazon Athena can instantly question.
On this submit, you’re employed with buyer and orders datasets that had been created and used within the beforehand talked about submit to display these capabilities in an information synchronization situation.
Resolution overview
This resolution demonstrates DELETE, UPDATE, and MERGE operations for Apache Iceberg tables in Amazon Redshift utilizing a typical information synchronization sample: sustaining buyer data and orders information throughout staging and manufacturing tables. The workflow consists of three key operations:
- DELETE – Take away buyer data primarily based on opt-out requests
- UPDATE – Modify present buyer data
- MERGE – Synchronize order information between staging and manufacturing tables utilizing upsert patterns
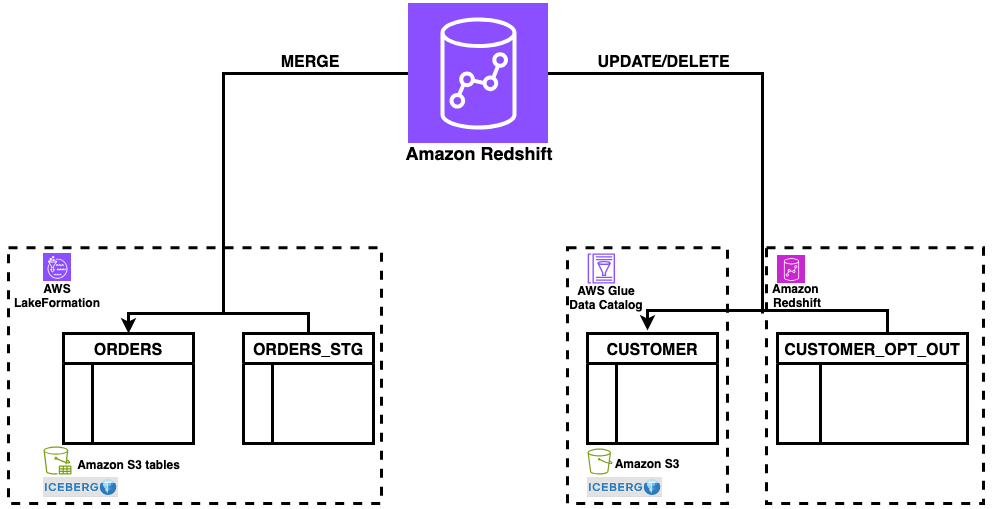
Determine 1: resolution overview
The answer makes use of a staging desk (orders_stg) saved in an S3 desk bucket for incoming information and reference tables (customer_opt_out) in Amazon Redshift for managing information lifecycle operations. With this structure, you’ll be able to course of modifications effectively whereas sustaining ACID compliance throughout each storage varieties.
Conditions
For this walkthrough, you need to have accomplished the setup steps from Getting began with Apache Iceberg write assist in Amazon Redshift – half 1, together with:
- Create an Amazon Redshift information warehouse (provisioned or Serverless)
- Arrange the required IAM function (
RedshifticebergRole) with acceptable permissions - Create an Amazon S3 bucket and S3 Desk bucket
- Configure AWS Glue Knowledge Catalog database and establishing entry
- Arrange AWS Lake Formation permissions
- Create the
buyerApache Iceberg desk in Amazon S3 normal buckets with pattern buyer information - Create the orders Apache Iceberg desk in Amazon S3 Desk buckets with pattern order information
- Amazon Redshift information warehouse on p200 model or increased
Knowledge preparation
On this part, you arrange the pattern information wanted to display MERGE, UPDATE, and DELETE operations. To arrange your information, full the next steps:
- Log in to Amazon Redshift utilizing Question Editor V2 with the Federated person choice.
- Create the
orders_stgandcustomer_opt_outtables with pattern information:

Determine 2: orders_stg outcome set
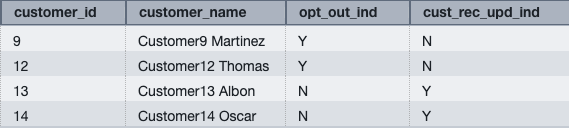
Determine 3: customer_opt_out outcome set
Now you can use the orders_stg and customer_opt_out tables to display information manipulation operations on the orders and buyer tables created within the prerequisite part.
MERGE
MERGE conditionally inserts, updates, or deletes rows in a goal desk primarily based on the outcomes of a be a part of with a supply desk. You should use MERGE to synchronize two tables by inserting, updating, or deleting rows in a single desk primarily based on variations discovered within the different desk.
To carry out a MERGE operation:
- Confirm that the present information within the orders desk for order IDs 1014, 1015, 1016, and 1017.You loaded this pattern information in Half 1:

Determine 4: orders information for present orders for orders in orders_stg
The orders desk comprises present rows for order IDs 1014 and 1015.
- Run the next MERGE operation utilizing order_id as the important thing column to match rows between the orders and orders_stg tables:
The operation updates present rows (1014 and 1015) and inserts new rows for order IDs that don’t exist within the orders desk (1016 and 1017).
- Confirm the up to date information within the orders desk:

Determine 5: merged information on orders from orders_stg
The MERGE operation performs the next modifications:
- Updates present rows – Order IDs 1014 and 1015 have up to date total_order_amt and total_order_tax_amt values from the orders_stg desk
- Inserts new rows – Order IDs 1016 and 1017 are inserted as a result of they don’t exist within the orders desk
This demonstrates the upsert sample, the place MERGE conditionally updates or inserts rows primarily based on the matching key column.
UPDATE
UPDATE modifies present rows in a desk primarily based on specified circumstances or values from one other desk.
Replace the buyer Apache Iceberg desk utilizing information from the customer_opt_out Amazon Redshift native desk. The UPDATE operation makes use of the cust_rec_upd_ind column as a filter, updating solely rows the place the worth is ‘Y’.
To carry out an UPDATE operation:
- Confirm the present
customer_namevalues for buyer IDs 13 and 14 incustomer_opt_outandbuyer(loaded this pattern information in Half 1) tables:

Determine 6: confirm present buyer information for patrons from customer_opt_out

Determine 7: confirm present buyer identify for patrons from customer_opt_out
- Run the next UPDATE operation to switch buyer names primarily based on the
cust_rec_upd_indfromcustomer_opt_out:
- Confirm the modifications for buyer IDs 13 and 14:

Determine 8: up to date buyer names in buyer desk
The UPDATE operation modifies the customer_name values primarily based on the be a part of situation with the customer_opt_out desk. Buyer IDs 13 and 14 now have up to date names (Customer13 Albon and Customer14 Oscar).
DELETE
DELETE removes rows from a desk primarily based on specified circumstances. And not using a WHERE clause, DELETE removes all of the rows from desk.
Delete rows from the buyer Apache Iceberg desk utilizing information from the customer_opt_out Amazon Redshift native desk. The DELETE operation makes use of the opt_out_ind column as a filter, eradicating solely rows the place the worth is ‘Y’.
To carry out a DELETE operation:
- Confirm the opt-out indicator information within the
customer_opt_outdesk:

Determine 9: confirm buyer data for decide out
- Confirm the present buyer information for buyer IDs 9 and 12:

Determine 10: confirm present clients information in buyer desk for decide out
- Assessment the question execution plan:

Determine 11: question plan for the DELETE question. The execution plan reveals Amazon S3 scans for Apache Iceberg format tables, indicating that Amazon Redshift removes rows instantly from the Amazon S3 bucket.
- Run the next DELETE operation:
- Confirm that the rows had been eliminated:

Determine 12: outcome set from buyer desk for decide out buyer after delete
The question returns no rows, confirming that buyer IDs 9 and 12 had been efficiently deleted from the buyer desk.
Greatest practices
After performing a number of UPDATE or DELETE operations, think about operating desk upkeep to optimize learn efficiency:
- For AWS Glue tables – Use AWS Glue desk optimizers. For extra data, see Desk optimizers within the AWS Glue Developer Information.
- For S3 Tables – Use S3 Tables upkeep operations. For extra data, see S3 Tables upkeep within the Amazon S3 Consumer Information.
Desk upkeep merges and compacts deletion information generated by Merge-on-Learn operations, enhancing question efficiency for subsequent reads.
Conclusion
You should use Amazon Redshift assist for DELETE, UPDATE, and MERGE operations on Apache Iceberg tables to construct information architectures that mix warehouse efficiency with information lake scalability. You possibly can modify information on the row degree whereas sustaining ACID compliance, giving you a similar flexibility with Apache Iceberg tables as you will have with native Amazon Redshift tables.
Get began: