

{kind=link}
AWS not too long ago introduced the final availability of GPU-accelerated vector (k-NN) indexing on Amazon OpenSearch Service. Now you can construct billion-scale vector databases in below an hour and index vectors as much as 10 occasions sooner at 1 / 4 of the price. This characteristic dynamically attaches serverless GPUs to spice up domains and collections working CPU-based situations. With this characteristic, you possibly can scale AI apps rapidly, innovate sooner, and run vector workloads leaner.
On this put up, we talk about the advantages of GPU-accelerated vector indexing, discover key use circumstances, and share efficiency benchmarks.
Overview of vector search and vector indexes
Vector search is a way that improves search relevance, and is a cornerstone of generative AI purposes. It entails utilizing an embeddings mannequin to transform content material into numerical encodings (vectors), enabling content material matching by semantic similarity as a substitute of simply key phrases. You possibly can construct vector databases by ingesting vectors into OpenSearch Service to construct indexes that allow searches throughout billions of vectors in milliseconds.
Challenges with scaling vector databases
Prospects are more and more scaling vector databases to multi-billion-scale on OpenSearch Service to energy generative AI purposes, product catalogs, data bases, and extra. Purposes have gotten more and more agentic, integrating AI brokers that depend on vector databases for high-quality search outcomes throughout enterprise information sources to allow chat-based interactions and automation.
Nonetheless, there are challenges on the best way to billion-scale. First, multi-million to billion-scale vector indexes take hours to days to construct. These indexes use algorithms like Hierarchal Navigable Small Worlds (HNSW) to allow high-quality, millisecond searches at scale. Nonetheless, they require extra compute energy than conventional indexes to construct. Moreover, you need to rebuild your indexes at any time when your mannequin adjustments, reminiscent of switching between distributors, variations, or after fine-tuning. Some use circumstances reminiscent of customized search require fashions to be fine-tuned every day and adapt to evolving consumer behaviors. All vectors should be regenerated when the mannequin adjustments, so the index should be rebuilt. HNSW may also degrade following vital updates and deletes, so indexes should be rebuilt to regain accuracy.
Lastly, as your agentic purposes grow to be extra dynamic, your vector database should scale for heavy streaming ingestion, updates, and deletes whereas sustaining low search latency. If search and indexing use the identical infrastructure, these intensive processes will compete for restricted compute and RAM, so search latency can degrade.
Answer overview
You possibly can overcome these challenges by enabling GPU-accelerated indexing on OpenSearch Service 3.1+ domains or collections. GPU acceleration will dynamically activate, for example, in response to a reindex command on a million-plus-size index. Throughout activation, index duties are offloaded to GPU servers that run NVIDIA cuVS to construct HNSW graphs. Superior velocity and effectivity are achieved by parallelization of vector operations. Inverted indexes will proceed utilizing your cluster’s CPU for indexing and search on non-vector information. These indexes function alongside HNSW to assist key phrase, hybrid, and filtered vector search. The assets required to construct inverted indexes is low in comparison with HNSW.
GPU acceleration is enabled as a cluster-level configuration, however it may be disabled on particular person indexes. This characteristic is serverless, so that you don’t have to handle GPU situations. You merely pay-per-use by OpenSearch Compute Models (OCUs).
The next diagram illustrates how this characteristic works.
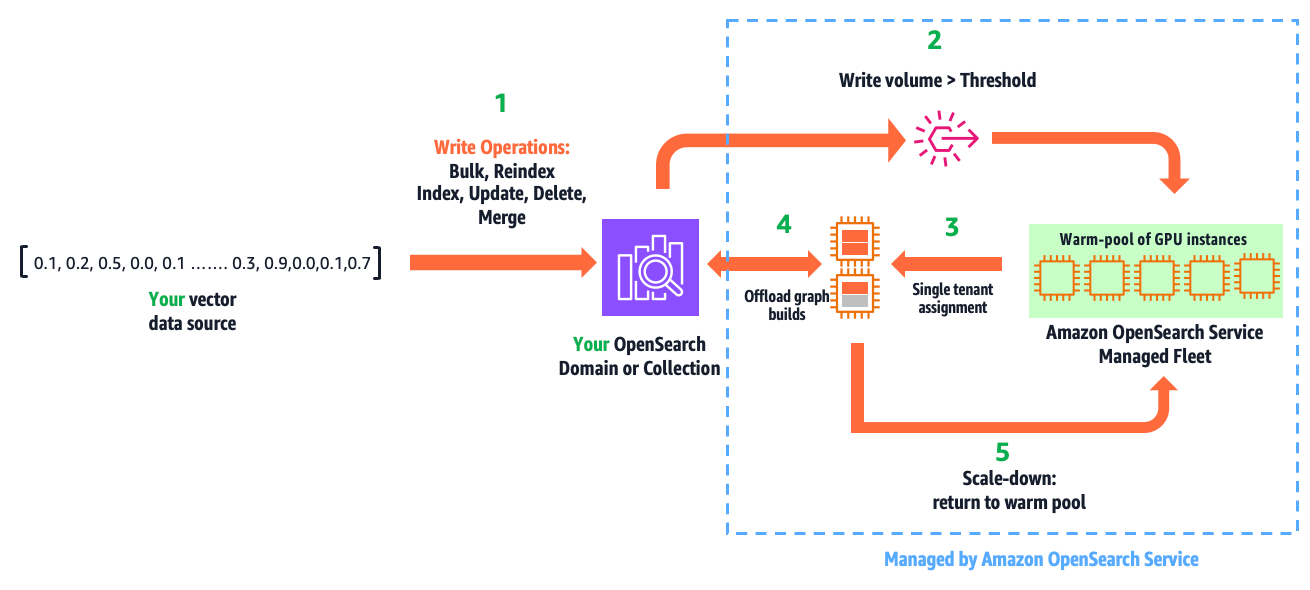
The workflow consists of the next steps:
- You write vectors into your area or assortment, utilizing the present APIs: bulk, reindex, index, replace, delete, and drive merge.
- GPU acceleration is activated when the listed vector information surpasses a configured threshold inside a refresh interval.
- This results in a safe, single-tenant project of GPU servers to your cluster from a multi-tenant heat pool of GPUs managed by OpenSearch Service.
- Inside milliseconds, OpenSearch Service initiates and offloads HNSW operations.
- When the write quantity falls under the brink, GPU servers are scaled down and returned to the nice and cozy pool.
This automation is totally managed. You solely pay for acceleration time, which you’ll be able to monitor from Amazon CloudWatch.
This characteristic isn’t simply designed for ease of use. It allows GPU acceleration advantages with out financial challenges. For instance, a site sized to host 1 billion (1,024 dimension) vectors compressed 32 occasions (utilizing binary quantization) takes three r8g.12xlarge.search situations to supply the required 1.15 TBs of RAM. A design that requires working a site on GPU situations, would want six g6.12xlarge situations to do the identical, leading to 2.4 occasions larger price and extreme GPUs. This resolution delivers effectivity by offering the correct amount of GPUs solely while you want them, so that you achieve velocity with price financial savings.
Use circumstances and advantages
This characteristic has three main makes use of and advantages:
- Construct large-scale indexes sooner, growing productiveness and innovation velocity
- Cut back price by decreasing Amazon OpenSearch Serverless indexing OCU utilization, or downsizing domains with write-heavy vector workloads
- Speed up writes, decrease search latency, and enhance consumer expertise in your dynamic AI purposes
Within the following sections, we talk about these use circumstances in additional element.
Construct large-scale indexes sooner
We benchmarked index builds for 1M, 10M, 113M, and 1B vector check circumstances to reveal velocity positive aspects on each domains and collections. Velocity positive aspects ranged from 6.4 to 13.8 occasions sooner. These exams had been carried out with manufacturing configurations (Multi-AZ with replication) and default GPU service limits. All exams had been run on right-sized search clusters, and the CPU-only exams had CPU utilization maxed completely for indexing. The next chart illustrates the relative velocity positive aspects from GPU acceleration on managed domains.
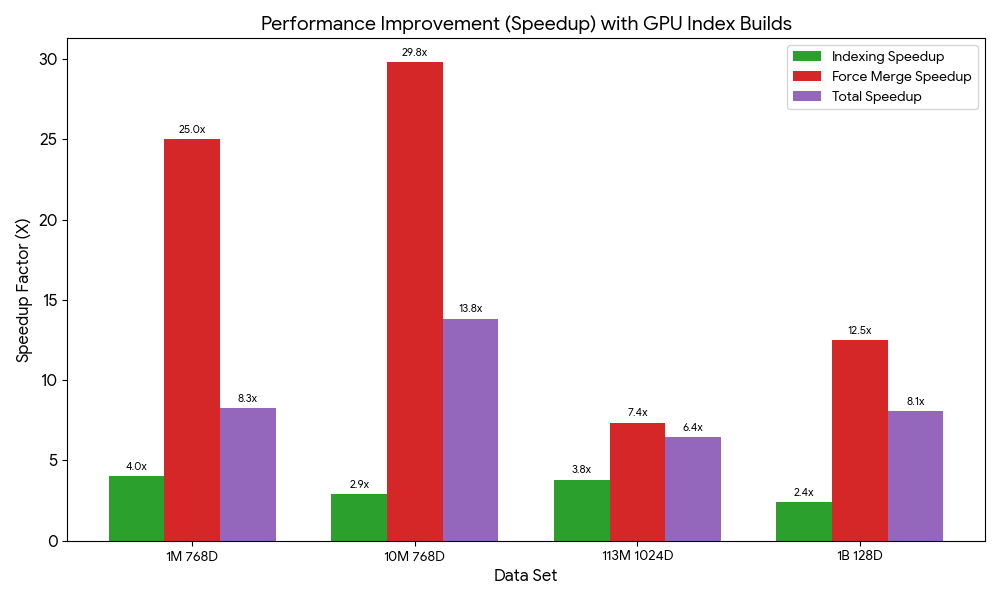
The full index construct time on domains features a drive merge to optimize the underlying storage engine for search efficiency. Throughout regular operation, merges are automated. Nonetheless, when benchmarking domains, we carry out a guide merge after indexing to verify merging influence is constant throughout exams. The next desk summarizes the index construct benchmarks and dataset references for domains.
We ran the identical efficiency exams on collections. The efficiency is totally different on OpenSearch Serverless as a result of its serverless structure entails efficiency trade-offs reminiscent of automated scaling, which introduces a ramp-up to succeed in peak efficiency. The next desk summarizes these outcomes.
OpenSearch Serverless doesn’t assist drive merge, so the total profit from GPU acceleration may be delayed till the automated background merges full. The default minimal OCUs needed to be elevated for exams past 1 million vectors to deal with larger indexing throughput.
Cut back price
Our serverless GPU design uniquely delivers velocity positive aspects and price financial savings. With OpenSearch Serverless, your web indexing prices will probably be lowered you probably have indexing workloads which can be vital sufficient to activate GPU acceleration. The next desk presents the OCU utilization and price consumption utilization from the earlier index construct exams.
The vector acceleration OCUs offload and cut back indexing OCUs. The full OCU utilization is much less with GPU as a result of the index is constructed extra effectively, leading to price financial savings.
With managed domains, price financial savings are situational as a result of search and indexing infrastructure isn’t decoupled like on OpenSearch Serverless. Nonetheless, you probably have a write-heavy, compute-bound vector search utility (that’s, your area is sized for vCPUs to maintain write throughput), you can downsize your area.
The next benchmarks reveal the effectivity positive aspects from GPU acceleration. We measure the infrastructure prices throughout the indexing duties. GPU acceleration has the extra price of GPUs at $0.24 per OCU/hour. Nonetheless, as a result of indexes are constructed sooner and extra effectively, it’s extra economical to make use of GPU to scale back CPU utilization in your area and downsize it.
*Domains are working a high-availability configuration with none cost-optimizations
Speed up writes, decrease search latency
In skilled palms, domains supply operational management and the power to realize nice scalability, efficiency, and price optimizations. Nonetheless, operational tasks embody managing indexing and search workloads on shared infrastructure. In case your vector deployment entails heavy, sustained streaming ingestion, updates, and deletes, you would possibly observe larger search occasions in your area. As illustrated within the following chart, as you enhance vector writes, the CPU utilization will increase to assist HNSW graph constructing. Concurrent search latency additionally will increase due to competitors for compute and RAM assets.
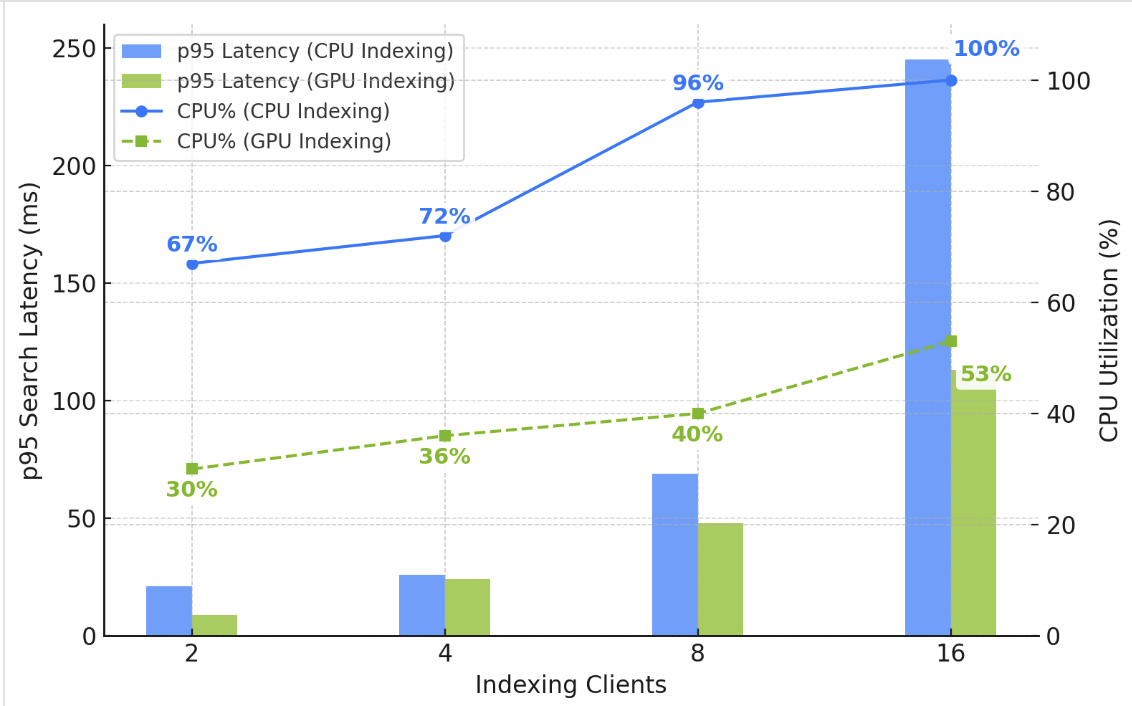
You may clear up the issue by including information nodes to extend your area’s compute capability. Nonetheless, enabling GPU acceleration is less complicated and cheaper. As illustrated within the chart, GPU frees up CPU and RAM in your area, serving to you maintain low and secure search latency below excessive write throughput.
Get began
Able to get began? If you have already got an OpenSearch Service vector deployment, use the AWS Administration Console, AWS Command Line Interface (AWS CLI), or API to allow GPU acceleration in your OpenSearch 3.1+ area or vector assortment. Check it together with your present indexing workloads. For those who’re planning to construct a brand new vector database, check out our new vector ingestion characteristic, which simplifies vector ingestion, indexing, and automates optimizations. Try this demonstration on YouTube.
Acknowledgments
The authors want to thank Manas Singh, Nathan Stephens, Jiahong Liu, Ben Gardner, and Zack Meeks from NVIDIA, and Yigit Kiran and Jay Deng from AWS for his or her contributions to this put up.
In regards to the authors
Authors want to add particular due to Manas Singh, Nathan Stephens, Jiahong Liu, Ben Gardner, Zack Meeks NVIDIA and Yigit Kiran and Jay Deng from AWS.