

AWS Glue Information High quality is a function of AWS Glue that helps preserve belief in your knowledge and help higher decision-making and analytics throughout your group. It permits customers to outline, monitor, and implement knowledge high quality guidelines throughout their knowledge lakes and knowledge pipelines. With AWS Glue Information High quality, you possibly can mechanically detect anomalies, validate knowledge in opposition to predefined guidelines, and generate high quality scores on your datasets. This function offers flexibility in the way you validate your knowledge – you possibly can incorporate high quality checks into your ETL processes for transformation-time validation, or validate knowledge instantly in opposition to cataloged tables for ongoing knowledge lake monitoring. By leveraging machine studying, it might probably additionally recommend knowledge high quality guidelines primarily based in your knowledge patterns.
You should utilize Terraform, an open supply Infrastructure as Code (IaC) device developed by HashiCorp, to deploy AWS Glue Information High quality pipelines.
It permits builders and operations groups to outline, provision, and handle cloud infrastructure utilizing a declarative language. With Terraform, you possibly can model, share, and reuse your infrastructure code throughout a number of cloud suppliers and companies. Its highly effective state administration and planning capabilities allow groups to collaborate effectively and preserve constant infrastructure throughout totally different environments.
Utilizing Terraform to deploy AWS Glue Information High quality pipeline allows IaC greatest practices to make sure constant, model managed and repeatable deployments throughout a number of environments, whereas fostering collaboration and decreasing errors attributable to handbook configuration.
On this put up, we discover two complementary strategies for implementing AWS Glue Information High quality utilizing Terraform:
- ETL-based Information High quality – Validates knowledge throughout ETL (Extract, Rework, Load) job execution, producing detailed high quality metrics and row-level validation outputs
- Catalog-based Information High quality – Validates knowledge instantly in opposition to Glue Information Catalog tables with out requiring ETL execution, ideally suited for monitoring knowledge at relaxation
Resolution overview
This put up demonstrates methods to implement AWS Glue Information High quality pipelines utilizing Terraform utilizing two complementary approaches talked about above to make sure complete knowledge high quality throughout your knowledge lake.
We’ll use the NYC yellow taxi journey knowledge, a real-world public dataset, for example knowledge high quality validation and monitoring capabilities. The pipeline ingests parquet-formatted taxi journey knowledge from Amazon Easy Storage Service (Amazon S3) and applies complete knowledge high quality guidelines that validate knowledge completeness, accuracy, and consistency throughout numerous journey attributes.
Technique 1: ETL-based Information High quality
ETL-based Information High quality validates knowledge throughout Extract, Rework, Load (ETL) job execution. This method is good for:
- Validating knowledge because it strikes by transformation pipelines
- Making use of high quality checks throughout knowledge processing workflows
- Producing row-level validation outputs alongside remodeled knowledge
The pipeline generates two key outputs:
- Information High quality Outcomes – Detailed high quality metrics and rule analysis outcomes saved within the dqresults/ folder, offering insights into knowledge high quality tendencies and anomalies
- Row-Stage Validation – Particular person data with their corresponding high quality test outcomes written to the processed/ folder, enabling granular evaluation of knowledge high quality points
Technique 2: Catalog-based Information High quality
Catalog-based Information High quality validates knowledge high quality guidelines instantly in opposition to AWS Glue Information Catalog tables with out requiring ETL job execution. This method is good for:
- Validating knowledge at relaxation within the knowledge lake
- Working scheduled knowledge high quality checks impartial of ETL pipelines
- Monitoring knowledge high quality throughout a number of tables in a database
Structure overview
The next diagram illustrates how each approaches work collectively to supply complete knowledge high quality validation:
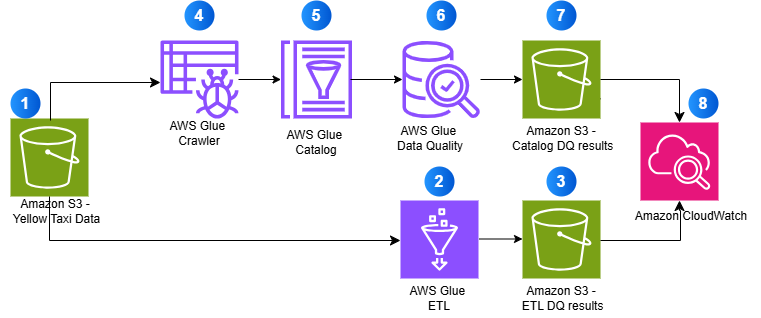
- Supply knowledge saved in Amazon S3 (Yellow Taxi Information)
- AWS Glue ETL processes knowledge with high quality checks
- ETL validation outcomes are saved in S3
- AWS Glue Crawler discovers schema
- Metadata is saved in AWS Glue Catalog
- AWS Glue Information High quality validates catalog tables
- Catalog validation outcomes are saved in S3
- Amazon CloudWatch displays all operations
Through the use of AWS Glue’s serverless ETL capabilities and Terraform’s infrastructure-as-code method, this resolution offers a scalable, maintainable, and automatic framework for making certain knowledge high quality in your analytics pipeline.
Conditions:
Resolution Implementation
Full the next steps to construct AWS Glue Information High quality pipeline utilizing Terraform:
Clone the Repository
This put up features a GitHub repository that generates the next sources when deployed. To clone the repository, run the next command in your terminal:
Core Infrastructure:
- Amazon S3 bucket:
glue-data-quality-{AWS AccountID}-{env}with AES256 encryption - Pattern NYC taxi dataset (
sample-data.parquet) mechanically uploaded to theknowledge/folder - AWS Identification and Entry Administration (IAM) position:
aws-glue-data-quality-role-{env}with Glue execution permissions and S3 learn/write entry - CloudWatch dashboard:
glue-data-quality-{env}for monitoring job execution and knowledge high quality metrics - CloudWatch Log Teams for job logging with configurable retention
ETL-Based mostly Information High quality Assets:
- AWS Glue ETL job:
data-quality-pipelinewith 8 complete validation guidelines - Python script:
GlueDataQualityDynamicRules.pysaved inglue-scripts/folder - Outcomes storage in
dqresults/folder with detailed rule outcomes - Row-level validation outputs in
processed/folder - Non-compulsory scheduled triggers for automated execution
- CloudWatch alarm:
etl-glue-data-quality-failure-{env}for monitoring job failures
Catalog-Based mostly Information High quality Assets (Non-compulsory – when catalog_dq_enabled = true):
- Glue Database:
{catalog_database_name}for catalog desk administration - Glue Crawler:
{job_name}-catalog-crawlerfor computerized schema discovery from S3 knowledge - Crawler schedule set off for automated execution (default: each day at 4 AM)
- Glue Catalog Tables mechanically found and created by the crawler
- Catalog Information High quality job:
{job_name}-catalogwith 7 catalog-specific validation guidelines - Python script:
CatalogDataQuality.pyfor catalog validation - Outcomes storage in
catalog-dq-results/folder partitioned by desk title - Catalog DQ schedule set off for automated validation (default: each day at 6 AM)
- CloudWatch alarm:
catalog-glue-data-quality-failure-{env}for monitoring catalog job failures - Enhanced CloudWatch dashboard widgets for crawler standing and catalog metrics
Evaluation the Glue Information High quality Job Script
Evaluation the Glue Information High quality job script GlueDataQualityDynamicRules.py positioned within the folder scripts, which has the next guidelines:
Temporary rationalization of guidelines for NY Taxi knowledge is as follows:
| Rule Sort | Situation | Description |
| CustomSql | “choose vendorid from major the place passenger_count > 0” with threshold > 0.9 | Checks if at the least 90% of rides have at the least one passenger |
| Imply | “trip_distance” < 150 | Ensures the typical journey distance is lower than 150 miles |
| Sum | “total_amount” between 1000 and 100000 | Verifies that whole income from all journeys falls inside this vary |
| RowCount | between 1000 and 1000000 | Checks if the dataset has between 1,000 and 1 million data |
| Completeness | “fare_amount” > 0.9 | Ensures over 90% of data have a fare quantity |
| DistinctValuesCount | “ratecodeid” between 3 and 10 | Verifies fee codes fall between 3-10 distinctive values |
| DistinctValuesCount | “pulocationid” > 100 | Checks if there are over 100 distinctive pickup areas |
| ColumnCount | 19 | Validates that dataset has precisely 19 columns |
These guidelines collectively guarantee knowledge high quality by validating quantity, completeness, cheap values and correct construction of the taxi journey knowledge.
Configure Terraform Variables
Earlier than deploying the infrastructure, configure your Terraform variables within the terraform.tfvars file positioned within the examples listing. This configuration determines which options might be deployed – ETL-based Information High quality solely, or each ETL-based and Catalog-based Information High quality.
Fundamental Configuration
The answer makes use of default values for many settings, however you possibly can customise the next in your terraform.tfvars file:
- AWS Area – The AWS area the place sources might be deployed
- Setting – Setting identifier (comparable to, “dev”, “prod”) utilized in useful resource naming
- Job Title – Title for the Glue job (default:
data-quality-pipeline)
Allow Catalog-Based mostly Information High quality
By default, the answer deploys solely ETL-based Information High quality. To allow Catalog-based Information High quality validation, add the next configuration to your terraform.tfvars file:
Configuration Notes:
- catalog_dq_enabled – Set to true to allow Catalog-based validation alongside ETL-based validation,which can deploy each ETL and Catalog validation
- catalog_database_name – Title of the Glue database that might be created for catalog tables
- s3_data_paths – S3 folders containing parquet knowledge that the Glue Crawler will uncover
- catalog_table_names – Depart empty to validate all tables, or specify particular desk names
- catalog_dq_rules – Outline validation guidelines particular to catalog tables (can differ from ETL guidelines)
- catalog_enable_schedule – Set to true to allow computerized scheduled execution
- Schedule expressions – Use cron format for automated execution (crawler runs earlier than DQ job)
When you’ve configured your variables, save the terraform.tfvars file and proceed to the following step.
Set Up AWS CLI Authentication
Earlier than you possibly can work together with AWS companies utilizing the command line, it’s essential arrange and authenticate the AWS CLI. This part guides you thru the method of configuring your AWS CLI and verifying your authentication. Observe these steps to make sure you have the mandatory permissions to entry AWS sources.
- Open your terminal or command immediate.
- Arrange authentication within the AWS CLI. You want administrator permissions to arrange this surroundings.
- To check in case your AWS CLI is working and also you’re authenticated, run the next command:
The output ought to look much like the next:
Deploy with Terraform
Observe these steps to deploy your infrastructure utilizing Terraform. This course of will initialize your working listing, evaluation deliberate adjustments, and apply your infrastructure configuration to AWS.
To deploy with Terraform, navigate to the examples folder by operating the next command in your CLI from contained in the repository
Run the next bash instructions:
Initializes a Terraform working listing, downloads required supplier plugins, and units up the backend for storing state.
On success you’ll obtain output Terraform has been efficiently initialized!
Creates an execution plan, reveals what adjustments Terraform will make to your infrastructure. This command doesn’t make any adjustments.
Deploys infrastructure and code to the AWS Account. By default, it asks for affirmation earlier than making any adjustments. Use ‘terraform apply -auto-approve’ to skip the affirmation step.
When prompted with ‘Do you need to carry out these actions?’, kind ‘sure’ and press Enter to verify and permit Terraform to execute the described actions.
Upon profitable execution, the system will show ‘Apply full!’ message.
Run the AWS Glue Information High quality Pipeline
After deploying the infrastructure with Terraform, you possibly can validate knowledge high quality utilizing two strategies – ETL-based and Catalog-based. Every technique serves totally different use circumstances and will be run independently or collectively.
Technique 1: Run the ETL-Based mostly Information High quality Job
ETL-based knowledge high quality validates knowledge in the course of the transformation course of, making it ideally suited for catching points early in your knowledge pipeline.
Steps to execute:
- Navigate to the AWS Glue Console and choose ETL Jobs from the left navigation panel
- Find and choose the job named
data-quality-pipeline

- Select Run to start out the job execution

- Monitor the job standing – it usually completes in 2-3 minutes
- Evaluation the outcomes:


The job processes the NYC taxi knowledge and applies all 8 validation guidelines in the course of the ETL execution. You’ll see a top quality rating together with detailed metrics for every rule.
Technique 2: Run the Catalog-Based mostly Information High quality Pipeline
Catalog-based knowledge high quality validates knowledge at relaxation in your knowledge lake, impartial of ETL processing. This technique requires the Glue Crawler to first uncover and catalog your knowledge.
- Run the Glue Crawler (first-time setup or when schema adjustments):
- Navigate to AWS Glue Console and choose Crawlers
- Find
data-quality-pipeline-catalog-crawler

- Choose
data-quality-pipeline-catalog-crawlercheckbox and click on Run and anticipate completion (1-2 minutes) - Confirm the desk was created in your Glue database

- Run the Catalog Information High quality Job:
- Navigate to the AWS Glue Console and choose ETL Jobs from the left navigation panel
- Choose the job named
data-quality-pipeline-catalog

- Click on Run job to execute the validation
- Monitor the job standing till completion

- Evaluation the outcomes:


{kind=link}
Catalog vs ETL Information High quality Comparability
| Characteristic | ETL Information High quality | Catalog Information High quality |
| Execution Context | Validates knowledge throughout ETL job processing | Validates knowledge in opposition to catalog tables at relaxation |
| Information Supply | Reads instantly from S3 information (parquet format) | Queries Glue Information Catalog tables |
| Outcomes Location | s3://…/dqresults/ | s3://…/catalog-dq-results/ |
| Main Use Case | Validate knowledge high quality throughout transformation pipelines | Monitor knowledge lake high quality impartial of ETL workflows |
| Execution Set off | Runs as a part of Glue ETL job execution | Runs independently as scheduled Information High quality job |
| Scheduling | Configured by way of Glue job schedule or on-demand | Configured by way of Information High quality job schedule or on-demand |
| Desk Discovery | Handbook – requires express S3 path configuration | Automated – Glue Crawler discovers schema and creates tables |
| Schema Administration | Outlined in ETL job script | Managed by Glue Information Catalog |
| Output Format | Information High quality metrics + row-level validation outputs | Information High quality metrics solely |
| Greatest For | Catching points early in knowledge pipelines | Ongoing monitoring of knowledge at relaxation in knowledge lakes |
| Dependencies | Requires ETL job execution | Requires Glue Crawler to run first |
| CloudWatch Integration | Job-level metrics and logs | Information High quality-specific metrics and logs |
Monitoring and Troubleshooting
Each knowledge high quality strategies mechanically ship metrics and logs to Amazon CloudWatch. You may arrange alarms to inform you when high quality scores drop beneath acceptable thresholds.
Clear up
To keep away from incurring pointless AWS costs, ensure to delete all sources created throughout this tutorial. Guarantee you’ve gotten backed up any essential knowledge earlier than operating these instructions, as this can completely delete the sources and their related knowledge. To destroy all sources created as a part of this weblog, run following command in your terminal:
Conclusion
On this weblog put up, we demonstrated methods to construct and deploy a scalable knowledge high quality pipeline utilizing AWS Glue Information High quality and Terraform. The answer implements two validation strategies:
- ETL-based Information High quality – Built-in validation throughout ETL job execution for transformation pipeline high quality assurance
- Catalog-based Information High quality – Unbiased validation in opposition to Glue Information Catalog tables for knowledge lake high quality monitoring
By implementing knowledge high quality checks on NYC taxi journey knowledge, we confirmed how organizations can automate their knowledge validation processes and preserve knowledge integrity at scale. The mixture of AWS Glue’s serverless structure and Terraform’s infrastructure-as-code capabilities offers a strong framework for implementing reproducible, version-controlled knowledge high quality options. This method not solely helps groups catch knowledge points early but additionally allows them to take care of constant knowledge high quality requirements throughout totally different environments. Whether or not you’re coping with small datasets or processing large quantities of knowledge, this resolution will be tailored to satisfy your group’s particular knowledge high quality necessities. As knowledge high quality continues to be a vital facet of profitable knowledge initiatives, implementing automated high quality checks utilizing AWS Glue Information High quality and Terraform units a robust basis for dependable knowledge analytics and decision-making.
To study extra about AWS Glue Information High quality, check with the next: