

{kind=link}
Are you modernizing your legacy batch processing techniques? At Vanguard, we confronted important challenges with our legacy mainframe system that restricted our means to ship trendy, personalised buyer experiences. Our centralized database structure created efficiency bottlenecks and made it tough to scale providers independently for our thousands and thousands of non-public and institutional traders.
On this submit, we present you the way we modernized our knowledge structure utilizing Amazon Redshift as our Operational Learn-only Information Retailer (ORDS). You’ll learn the way we transitioned to a cloud-native, domain-driven structure whereas preserving essential batch processing capabilities. We present you the way this resolution enabled us to create logically remoted knowledge domains whereas sustaining cross-domain analytics capabilities—all whereas adhering to the rules of bounded contexts and distributed knowledge possession.
Background and challenges
As monetary wants proceed to evolve, Vanguard is dedicated to delivering adaptable, top-notch experiences that foster long-lasting buyer relationships. This dedication spans from enhancing the private investor journey to bringing personalised cell dashboards and connecting institutional shoppers with superior recommendation choices.
To raise buyer expertise and drive digital transformation, Vanguard has embraced domain-driven design rules. This method focuses on creating autonomous groups, fostering sooner innovation, and constructing knowledge mesh structure. Central to this transformation is the Private Investor staff’s mainframe modernization effort, transitioning from a legacy system to a cloud-based, distributed knowledge structure organized round bounded contexts – distinct enterprise domains that handle their very own knowledge. As a part of this shift, every microservice now manages its personal native knowledge retailer utilizing Amazon Aurora PostgreSQL-Appropriate Version or Amazon DynamoDB. This method allows domain-level knowledge possession and operational autonomy.
Vanguard’s present mainframe system, constructed on a centralized Db2 database, allows cross-domain knowledge entry and integration but additionally introduces a number of architectural challenges. Although batch processes can be a part of knowledge throughout a number of bounded contexts utilizing SQL joins and database operations to combine data from numerous sources, this tight coupling creates important dangers and operational points.
Challenges with the centralized database method embrace:
- Useful resource Competition: Processes from one area can negatively affect different domains resulting from shared compute sources, resulting in efficiency degradation throughout the system.
- Lack of Area Isolation: Modifications in a single bounded context can have unintended ripple results throughout different domains, rising the chance of system-wide failures.
- Scalability Constraints: The centralized structure creates bottlenecks as load will increase, making it tough to scale particular person elements independently.
- Excessive Coupling: Tight integration between domains makes it difficult to change or improve particular person elements with out affecting your complete system.
- Restricted Fault Tolerance: Points in a single area can cascade throughout your complete system resulting from shared infrastructure and knowledge dependencies.
To handle these architectural challenges, we selected to make use of Amazon Redshift as our Operational Learn-only Information Retailer (ORDS). The Amazon Redshift structure has compute and storage separation, which allows us to create multi-cluster architectures with a separate endpoint for every area with impartial scaling of compute and storage sources. Our resolution leverages the info sharing capabilities of Amazon Redshift to create logically remoted knowledge domains whereas sustaining the flexibility to carry out cross-domain analytics when wanted.
Key advantages of the Amazon Redshift resolution embrace:
- Useful resource Isolation: Every area will be assigned devoted Amazon Redshift compute sources, ensuring one area’s workload doesn’t affect others.
- Impartial Scaling: Domains can scale their compute sources independently primarily based on their particular wants.
- Managed Information Sharing: Amazon Redshift’s knowledge sharing function allows safe and managed cross-domain knowledge entry with out tight coupling, sustaining clear area boundaries.
Let’s discover the completely different options we evaluated earlier than deciding on ORDS with Amazon Redshift as our optimum method.
Options explored
We carried out ORDS as our optimum resolution after conducting a complete analysis of accessible choices. This part outlines our decision-making course of and examines the options we thought-about throughout our evaluation.
Operational Learn-only Information Retailer (ORDS):
In our analysis, we discovered that utilizing Amazon Redshift for ORDS supplies a robust resolution for dealing with knowledge throughout completely different enterprise areas. It excels at managing giant volumes of knowledge from a number of sources, offering quick entry to replicated knowledge for batch processes that require cross-bounded context knowledge, and mixing data utilizing acquainted SQL queries. The answer notably shines in dealing with high-volume reads from our knowledge sources.
Benefits:
- Works nicely in a relational database
- Excels at real-time entry to knowledge from a number of enterprise areas
- Improves efficiency of batch jobs coping with giant knowledge volumes
- Shops knowledge in acquainted desk format, accessible by way of SQL
- Enforces clear knowledge possession, with every enterprise space chargeable for its knowledge
- Presents scalable structure that reduces the chance of single level of failure
Disadvantages:
- Requires extra knowledge validation throughout loading processes to take care of knowledge uniqueness
- Wants cautious administration of main key constraints since Amazon Redshift optimizes for analytical efficiency
- Might require extra monitoring and controls in comparison with conventional RDBMS techniques
Listed here are the opposite options we evaluated:
Bulk APIs:
We discovered that Bulk APIs supplies an method for dealing with giant volumes of knowledge.
Benefits:
- Close to actual time entry to bulk knowledge by a single request
- Autonomous groups have management over entry patterns
- Environment friendly batch processing of huge datasets with multi-record retrieval
Disadvantages:
- Every product staff must create their very own bulk API
- If you happen to want knowledge from completely different areas, you should mix it your self
- The staff offering the API should be certain it will possibly deal with giant quantities of requests
- You may want to make use of a number of APIs to get all the info you need
- If you happen to’re getting knowledge in chunks (pagination), you may miss some data if it modifications between requests
Whereas Bulk APIs provide highly effective capabilities, we discovered they require substantial staff coordination and cautious implementation to be efficient.
Information Lake:
Our analysis confirmed that knowledge lakes can successfully mix data from completely different elements of our enterprise. They excel at processing giant quantities of knowledge without delay, offering search capabilities by unified knowledge codecs, and managing giant volumes of various and complicated knowledge.
Benefits:
- Handles large knowledge volumes effectively
- Helps a number of knowledge codecs and constructions
- Permits advanced analytics and knowledge science workloads
- Offers cost-effective storage options
- Accommodates each structured and unstructured knowledge
Disadvantages:
- Might not present real-time, high-speed knowledge entry
- Requires extra effort with advanced knowledge constructions, particularly these with many interconnected elements
- Wants particular methods to prepare knowledge in a easy, flat construction
- Calls for important knowledge governance and administration
- Requires specialised abilities for efficient implementation
Whereas knowledge lakes excel at big-picture evaluation of huge datasets, they weren’t optimum for our real-time knowledge wants and complicated knowledge relationships.
S3 Export/Trade:
In our evaluation, we discovered that S3 Export/Trade supplies a technique for sharing knowledge between completely different enterprise areas utilizing file storage. This method successfully handles giant volumes of knowledge and permits easy filtering of knowledge utilizing knowledge frames.
Benefits:
- Offers easy, cost-effective knowledge storage
- Helps high-volume knowledge transfers
- Permits easy knowledge filtering capabilities
- Presents versatile entry management
- Facilitates cross-region knowledge sharing
Disadvantages:
- Not appropriate for real-time knowledge wants
- Requires further processing to transform knowledge into usable desk format
- Calls for important knowledge preparation effort
- Lacks rapid knowledge consistency
- Wants extra instruments for knowledge transformation
Whereas S3 Export/Trade works nicely for sharing giant datasets between groups, it didn’t meet our necessities for fast, real-time entry or instantly usable knowledge codecs.
The next desk supplies a high-level comparability of the completely different knowledge integration options we thought-about for our modernization efforts. It outlines the place every resolution is most acceptable to make use of and when it may not be the only option:
| Answer | Bulk APIs | Information Lake | ORDS | S3 Export/Trade |
| When to make use of | Actual-time operational knowledge is required Fetching particular knowledge subsets | Processing giant quantities of knowledge without delay Many bounded context | Close to real-time entry throughout a number of bounded contexts Massive quantity batch processing | Few bounded contextsHandling giant volumes of knowledge Level-in-time export is ample |
| When to not use | Many bounded contexts concerned | Actual-time knowledge entry wanted Structured, transactional knowledge processing | Inside a single bounded context | Actual-time knowledge wants Many bounded contexts |
Desk 1: Information Integration Options Comparability
Based mostly on our comparability, we discovered ORDS to be the optimum resolution for our wants, notably when our batch processes require entry to knowledge from a number of bounded contexts in real-time. Our implementation effectively handles giant volumes of knowledge, considerably enhancing the efficiency of our batch jobs. We selected ORDS as a result of it shops knowledge in a well-recognized desk format, accessible by way of SQL, making it easy and environment friendly for our groups to make use of.
The structure additionally aligns with our domain-driven design rules by implementing clear knowledge possession, the place every bounded context maintains accountability for its personal knowledge administration. This method supplies us with each scalability and reliability, decreasing the chance of a single level of failure.
Amazon Redshift: Powering Vanguard’s ORDS Answer
Amazon Redshift serves because the spine of our ORDS implementation, providing a number of essential options that help our modernization targets:
Information Sharing
Our resolution leveraged the sturdy knowledge sharing capabilities of Amazon Redshift, accessible on each Server-based Redshift RA3 situations and Redshift Serverless choices. This performance supplied us with on the spot, safe, and reside knowledge entry with out copies, sustaining transactional consistency throughout our surroundings. The flexibleness of identical account, cross-account, and cross-Area knowledge sharing has been notably useful for our distributed structure.
Excessive Efficiency
We’ve achieved important efficiency enhancements by Amazon Redshift’s environment friendly question processing and knowledge retrieval capabilities. The system successfully handles our advanced knowledge wants whereas sustaining sturdy efficiency throughout numerous workloads and knowledge volumes.
Multi-Availability Zone Assist
Our implementation benefited from Amazon Redshift’s Multi-AZ help, which maintains excessive availability and reliability for our essential operations. This function minimizes downtime with out requiring intensive setup and considerably reduces our threat of knowledge loss.
Acquainted Interface
The relational surroundings of Amazon Redshift, comparable conventional databases like Amazon RDS and IBM Db2, has enabled a clean transition for our groups. This familiarity has accelerated adoption and improved productiveness, as our groups can leverage their present SQL experience. By centralizing knowledge from a number of enterprise areas in ORDS utilizing Amazon Redshift, we keep constant, environment friendly, and safe knowledge entry throughout our product groups. This setup is especially useful for our batch processing that requires knowledge from numerous elements of the enterprise, providing us a mix of efficiency, reliability, and ease of use.
Operational Learn-only Information Retailer (ORDS) utilizing Amazon Redshift
Right here’s how our ORDS structure implements Amazon Redshift knowledge sharing to unravel these challenges:
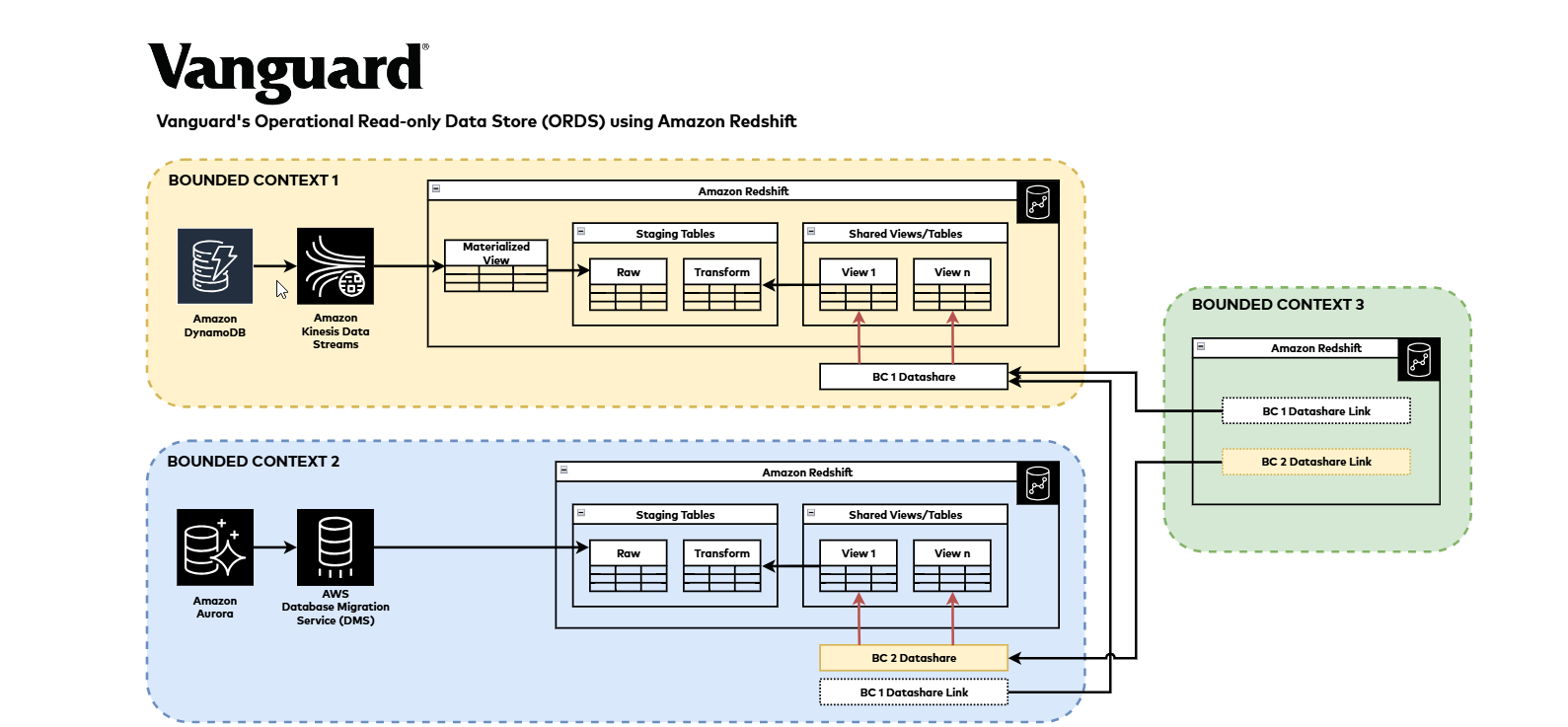
Determine 1: Vanguard’s ORDS Structure utilizing Amazon Redshift Information Sharing
Amazon Redshift Ingestion Sample:
We utilized Amazon Redshift’s zero-ETL performance to combine knowledge and allow real-time analytics instantly on operational knowledge, which helped cut back complexity and upkeep overhead. To enhance this functionality and to satisfy our complete compliance necessities that necessitate full transaction replication, we carried out extra knowledge ingestion pipelines.
Our knowledge ingestion technique for Amazon Redshift employs completely different AWS providers relying on the supply. For Amazon Aurora PostgreSQL databases, we use AWS Database Migration Service (AWS DMS) to instantly replicate knowledge into Amazon Redshift. For knowledge from Amazon DynamoDB, we leverage Amazon Kinesis to stream the info into Amazon Redshift, the place it lands in materialized views. These views are then additional processed to generate tables for end-users.
This method permits us to effectively ingest knowledge from our operational knowledge shops whereas assembly each analytical wants and compliance necessities.
Amazon Redshift Information Sharing:
We used the Amazon Redshift’s knowledge sharing function to successfully decouple our knowledge producers from customers, permitting every group to function inside their very own boundaries whereas sustaining a unified and simplified ruled mechanism for knowledge sharing.
Our implementation adopted a transparent course of: as soon as knowledge is ingested and accessible in Amazon Redshift desk format, we created views for customers to entry the info. We then established knowledge shares and granted entry to those views to shopper Amazon Redshift knowledge warehouses for batch processing. In our surroundings with a number of bounded contexts, we’ve established a collaborative mannequin the place customers work with numerous producer groups to entry knowledge from completely different knowledge shares, every created per bounded context.
This entry remained strictly read-only—when customers have to replace or write new knowledge that falls outdoors their bounded context, they have to use APIs or different designated mechanisms for such operations. This method has confirmed efficient for our group, selling clear knowledge possession and governance whereas enabling versatile knowledge entry throughout organizational boundaries. It simplified our knowledge administration and made positive every staff can function independently whereas nonetheless sharing knowledge successfully.
Instance: VG couple of cross bounded context
Disclaimer: That is supplied for reference functions solely and doesn’t signify an actual instance.
Let’s take a look at a sensible instance: our brokerage account assertion era course of. This cross-bounded context batch course of requires integrating knowledge from a number of sources, accessing a whole bunch of tables and processing giant volumes of knowledge month-to-month. The problem was to create an environment friendly, cost-effective resolution that minimizes knowledge replication whereas sustaining knowledge accessibility.ORDS proved superb for this use case, because it supplies knowledge from a number of bounded contexts with out replication, affords close to real-time entry, and allows easy knowledge aggregation utilizing SQL-like queries in Amazon Redshift.
The next diagram exhibits how we carried out this resolution:
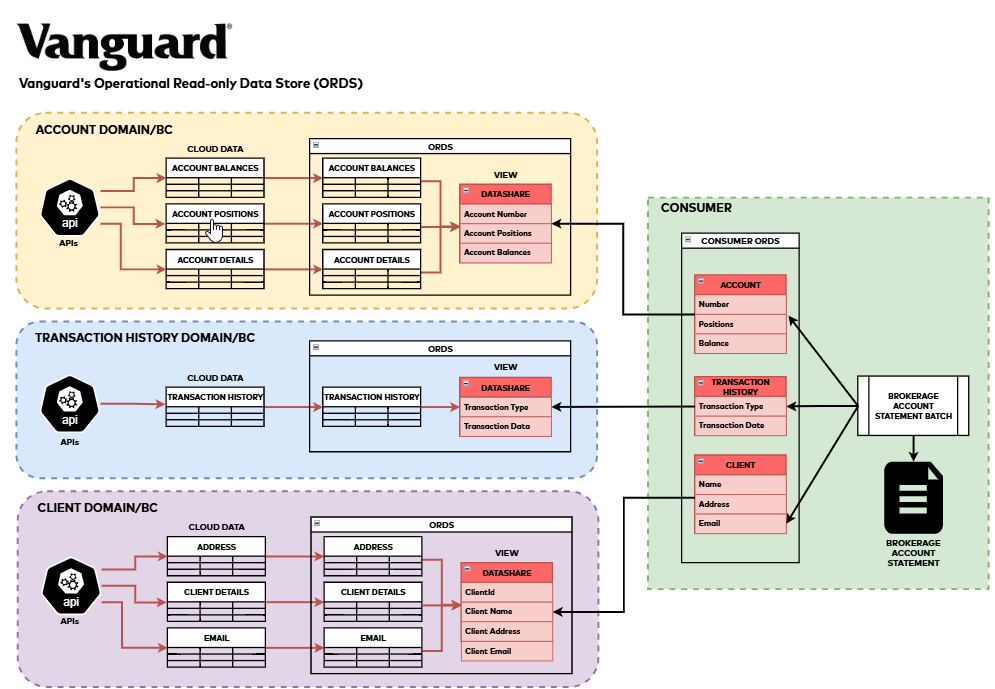
Determine 2: Cross-Bounded Context Instance for Brokerage Account Assertion Technology
We want the next bounded contexts to generate brokerage statements for thousands and thousands of our shoppers.
- Account:
- Particulars: Contains details about the consumer’s brokerage accounts, reminiscent of account numbers, varieties, and statuses.
- Holdings and Positions: Offers present holdings and positions throughout the account, detailing the securities owned, their portions, and present market values.
- Stability Data: Accommodates the steadiness data of the account, together with money balances, margin balances, and complete account worth.
- Consumer Profile:
- Private Data: Details about the consumer, reminiscent of their title, date of beginning, and social safety quantity.
- Contact Data: Contains the consumer’s electronic mail handle, bodily handle, and cellphone numbers.
- Transaction Historical past:
- Transaction Information: A complete report of transactions related to the account, together with buys, gross sales, transfers, and dividends.
- Transaction Particulars: Every transaction report consists of particulars reminiscent of transaction date, sort, amount, worth, and related charges.
- Historic Information: Historic knowledge of transactions over time, offering a whole view of the account’s exercise.
By way of this structure, we effectively generate correct and complete brokerage account statements by consolidating knowledge from these bounded contexts, assembly each our shoppers’ wants and regulatory necessities.
Enterprise Final result
Our journey with the Operational Learn-only Information Retailer (ORDS) and Amazon Redshift has enhanced our consumer expertise (CX) by improved knowledge administration and accessibility. By transitioning from our mainframe system to a cloud-based, domain-driven structure, now we have empowered our autonomous groups and established a resilient batch structure.
This shift facilitates environment friendly cross-domain knowledge entry, maintains high-quality knowledge consistency, and supplies scalability. Our ORDS implementation, supported by Amazon Redshift, affords near-real-time entry to giant knowledge volumes, guaranteeing excessive efficiency, reliability, and cost-effectiveness. This modernization effort aligns with our mission to ship distinctive, personalised consumer experiences and maintain long-lasting consumer relationships.
Name to Motion
In case you are dealing with comparable challenges along with your batch processing techniques, we encourage you to discover how an Operational Learn-only Information Retailer (ORDS) can rework your knowledge structure. Begin by assessing your present system’s limitations and figuring out alternatives for enchancment by domain-driven design and cloud-based options. Take into account how this method may help you handle giant volumes of knowledge from a number of sources, present quick entry to replicated knowledge for batch processes, and help high-volume reads from numerous knowledge sources.
Take the subsequent step by conducting a proof of idea (POC) to guage ORDS effectiveness in attaining environment friendly cross-domain knowledge entry, enhancing the efficiency of batch jobs, and sustaining clear knowledge possession inside what you are promoting domains. By implementing this resolution, you may improve your knowledge administration capabilities, cut back operational dangers, and drive innovation inside your group. Embrace this chance to raise your knowledge structure and ship distinctive buyer experiences.
Conclusion
Our transition to a cloud-native, domain-driven structure with ORDS utilizing Amazon Redshift has efficiently reworked our batch processing capabilities in AWS cloud. This modernization effort has considerably enhanced the efficiency, reliability, and scalability of our batch operations whereas sustaining seamless knowledge entry and integration throughout completely different enterprise domains.
The strategic adoption of ORDS has harnessed the potential of cross-domain knowledge entry in a distributed surroundings, offering us with a sturdy resolution for real-time knowledge entry and environment friendly batch processing. This transformation has empowered us to raised meet the calls for of the digital age, delivering superior buyer experiences and reinforcing our dedication to innovation within the monetary providers trade.
Concerning the authors
© 2025 The Vanguard Group, Inc. All rights reserved.