

Implementing Manufacturing-Grade Analytics on a Databricks Knowledge Warehouse
Excessive-concurrency, low-latency information warehousing is important for organizations the place information drives crucial enterprise choices. This implies supporting tons of of concurrent customers, delivering speedy question efficiency for interactive analytics and enabling actual‑time insights for quick, knowledgeable determination‑making. A manufacturing‑grade information warehouse is greater than a assist system—it’s a catalyst for development and innovation.
Databricks pioneered the lakehouse structure to unify information, analytics and AI workloads—eliminating expensive information duplication and sophisticated system integrations. With built-in autonomous efficiency optimizations, the lakehouse delivers aggressive value/efficiency whereas simplifying operations. As an open lakehouse, it additionally ensures quick, safe entry to crucial information by means of Databricks SQL, powering BI, analytics and AI instruments with unified safety and governance that stretch throughout your entire ecosystem. Open interoperability is important since most customers work together with the warehouse by means of these exterior instruments. The platform scales effortlessly—not solely with information and customers, but additionally with the rising variety of instruments your groups depend on—and gives highly effective built-in capabilities like Databricks AI/BI, Mosaic AI and extra, whereas sustaining flexibility and interoperability together with your present ecosystem.
This weblog gives a complete information for organizations at any stage of their lakehouse structure journey—from preliminary design to mid-implementation to ongoing optimization—on maximizing high-concurrency, low-latency efficiency with the Databricks Knowledge Intelligence Platform. We are going to discover:
- Core architectural parts of an information warehouse and their collective affect on platform efficiency.
- A structured performance-tuning framework to information the optimization of those architectural parts.
- Greatest practices, monitoring methods and tuning methodologies to make sure sustained efficiency at scale.
- An actual-world case research demonstrating how these rules work collectively in follow.
Key Architectural Concerns
Whereas many foundational rules of conventional information warehouses nonetheless apply—resembling sound information modeling, sturdy information administration and embedded information high quality—designing a contemporary lakehouse for manufacturing‑grade analytics requires a extra holistic strategy. Central to this can be a unified governance framework, and Unity Catalog (AWS | Azure | GCP) performs a crucial position in delivering it. By standardizing entry controls, lineage monitoring and auditability throughout all information and AI property, Unity Catalog ensures constant governance at scale—one thing that is more and more important as organizations develop in information quantity, consumer concurrency and platform complexity.
Efficient design requires:
- Adoption of confirmed architectural greatest practices
- An understanding of tradeoffs between interconnected parts
- Clear aims for concurrency, latency and scale based mostly on enterprise necessities
In a lakehouse, efficiency outcomes are influenced by architectural decisions made early within the design part. These deliberate design choices spotlight how fashionable lakehouses symbolize a elementary departure from legacy information warehouses throughout 5 crucial axes:

With these architectural issues in thoughts, let’s discover a sensible framework for implementing a production-grade information warehouse that may ship on the promise of high-concurrency and low-latency at scale.
Technical Answer Breakdown
The next framework distills greatest practices and architectural rules developed by means of real-world engagements with enterprise prospects. Whether or not you are constructing a brand new information warehouse, migrating from a legacy platform or tuning an present lakehouse, these pointers will enable you to speed up time to manufacturing whereas delivering scalable, performant and cost-efficient outcomes.
Begin With a Use Case-Pushed Evaluation
Earlier than implementing, we advocate a speedy evaluation of a crucial workload—usually your slowest dashboard or most resource-intensive pipeline. This strategy helps you determine efficiency gaps and prioritize areas for optimization.
Ask the next questions to border your evaluation:
- What efficiency metrics matter most (e.g., question latency, throughput, concurrency) and the way do they examine to enterprise expectations?
- Who makes use of this workload, when and the way incessantly?
- Are compute prices proportional to the workload’s enterprise worth?
This evaluation creates a basis for focused enhancements and helps align your optimization efforts with enterprise affect.
Implementation Framework
The framework under outlines a step-by-step strategy to implementing or modernizing your warehouse on Databricks:
- Assess the Present State and Prioritize Your Targets
- Consider and examine the present structure in opposition to efficiency, price and scalability targets.
- Outline enterprise (and know-how) necessities for concurrency, latency, scale, price, SLAs and different components so the aim posts do not preserve shifting.
- Establish gaps that affect the enterprise most and prioritize remediation based mostly on worth and complexity (whether or not designing new, mid-migration or in manufacturing).
- Outline Warehouse Structure and Governance
- Design logical segmentation: Decide which groups or use instances will share or require devoted SQL Warehouses.
- Proper-size your warehouse situations, apply tagging and outline defaults (e.g., cache settings, timeouts, and so forth.).
- Perceive and plan for fine-grained configurations like default caching, warehouse timeouts, JDBC timeouts from BI instruments and SQL configuration parameters (AWS | Azure | GPC).
- Set up a governance mannequin for warehouses masking administrator (AWS | Azure | GCP) and finish consumer (AWS | Azure | GCP) roles and obligations.
- Put money into coaching and supply implementation templates to make sure consistency throughout groups.
- Allow Observability
- Allow observability and monitoring for SQL warehouse utilization to detect anomalies, uncover inefficient workloads and optimize useful resource utilization.
- Activate out-of-the-box performance (AWS | Azure | GCP) alongside customized telemetry and automate alerts/remediations the place attainable.
- Be taught to leverage system tables, warehouse monitoring and question profiles to determine points like spill, shuffle or queuing.
- Combine price information and lineage metadata (e.g., BI device context through question historical past tables) to correlate efficiency and spend.
- Implement Optimizations and Greatest Practices
- Leverage insights from observability to align workload efficiency with enterprise and know-how necessities.
- Implement AI options for price, structure and compute effectivity.
- Codify learnings into reusable templates, documentation and checklists to scale greatest practices throughout groups.
- Optimize incrementally utilizing an effort (complexity, timeline, experience) vs. affect (efficiency, price, upkeep overhead) matrix to prioritize.
Within the sections under, let’s stroll by means of every stage of this framework to grasp how considerate design and execution allow excessive concurrency, low latency and business-aligned price efficiency on Databricks.
Assess the Present State and Prioritize Your Targets
Earlier than diving into greatest practices and tuning strategies, it is important to grasp the foundational levers that form lakehouse efficiency—resembling compute sizing, information structure and information modeling. These are the areas groups can straight affect to fulfill high-concurrency, low-latency, scale targets.

The scorecard under gives a easy matrix to evaluate maturity throughout every lever and determine the place to focus your efforts. To make use of it, consider every lever throughout three dimensions: how effectively it meets enterprise wants, how intently it aligns with greatest practices, the extent of technical functionality your crew has in that space and governance. Apply a Crimson-Amber-Inexperienced (RAG) ranking to every intersection to shortly visualize strengths (inexperienced), areas for enchancment (amber) and significant gaps (crimson). The very best practices and analysis strategies later on this weblog will inform the ranking–use this directionality together with a extra granular maturity evaluation. This train can information discussions throughout groups, floor hidden bottlenecks and assist prioritize the place to take a position—whether or not in coaching, structure adjustments or automation.
With the parts that drive lakehouse efficiency and a framework to implement them outlined, what’s subsequent? The mix of greatest practices (what to do), tuning strategies (how to do it) and evaluation strategies (when to do it) gives the actions to take to attain your efficiency aims.
The main focus can be on particular greatest practices and granular configuration strategies for a number of crucial parts that work harmoniously to function a high-performing information warehouse.
Outline Warehouse Structure and Governance
Compute (Databricks SQL Warehouse)
Whereas compute is usually seen as the first efficiency lever, compute sizing choices ought to at all times be thought-about alongside information structure design and modeling/querying, as these straight affect the compute wanted to attain the required efficiency.
Proper-sizing SQL warehouses is crucial for cost-effective scaling. There isn’t any crystal ball for exact sizing upfront, however these are a choice of key heuristics to observe for organizing and sizing SQL warehouse compute.
- Allow SQL Serverless Warehouses: They provide instantaneous compute, elastic autoscaling and are totally managed, simplifying operations for all sorts of makes use of, together with bursty and inconsistent BI/analytics workloads. Databricks totally manages the infrastructure, with that infrastructure price baked in, providing the potential for TCO reductions.
- Perceive Workloads and Customers: Phase customers (human/automated) and their question patterns (interactive BI, advert hoc, scheduled experiences) to make use of totally different warehouses scoped by utility context, a logical grouping by function, crew, perform, and so forth. Implement a multi-warehouse structure, by these segments, to have extra fine-grained sizing management and the flexibility to watch independently. Guarantee tags for price attribution are enforced. Attain out to your Databricks account contact to entry upcoming options meant to stop noisy neighbors.
- Iterative Sizing and Scaling: Do not overthink the preliminary warehouse dimension or min/max cluster settings. Changes based mostly on monitoring actual workload efficiency, utilizing mechanisms within the subsequent part, are far simpler than upfront guesses. Knowledge volumes and the variety of customers don’t precisely estimate the compute wanted. The kinds of queries, patterns and concurrency of question load are higher metrics, and there is an automatic profit from Clever Workload Administration (IWM) (AWS | Azure | GCP).
- Perceive When to Resize vs. Scale: Enhance warehouse dimension (“T-shirt dimension”) when needing to accommodate resource-heavy, advanced queries like giant aggregations and multi-table joins, which require excessive reminiscence—monitor frequency of disk spills and reminiscence utilization. Enhance the variety of clusters for autoscaling when coping with bursty concurrent utilization and while you see persistent queuing because of many queries ready to execute, not a number of intensive queries pending.
- Stability Availability and Value: Configure auto-stop settings. Serverless’s speedy chilly begin makes auto-stopping a major cost-saver for idle intervals.
Bodily Knowledge (File) Structure within the Lakehouse
Quick queries start with information skipping, the place the question engine reads solely related information utilizing metadata and statistics for environment friendly file pruning. The bodily group of your information straight impacts this pruning, making file structure optimization crucial for high-concurrency, low-latency efficiency.
The evolution of knowledge structure strategies on Databricks gives varied approaches for optimum file group:
For brand new tables, Databricks recommends defaulting to managed tables with Auto Liquid Clustering (AWS | Azure | GCP) and Predictive Optimization (AWS | Azure | GCP). Auto Liquid Clustering intelligently organizes information based mostly on question patterns, and you’ll specify preliminary clustering columns as hints to allow it in a single command. Predictive Optimization robotically handles upkeep jobs like OPTIMIZE, VACUUM and ANALYZE.
For present deployments utilizing exterior tables, take into account migrating to managed tables to completely leverage these AI-powered options, prioritizing high-read and latency-sensitive tables first. Databricks gives an automatic answer (AWS | Azure | GCP) with the ALTER TABLE...SET MANAGED command to simplify the migration course of. Moreover, Databricks helps managed Iceberg tables as a part of its open desk format technique.
Knowledge Modeling / Querying
Modeling is the place enterprise necessities meet information construction. All the time begin by understanding your finish consumption patterns, then mannequin to these enterprise wants utilizing your group’s most well-liked methodology—Kimball, Inmon, Knowledge Vault or denormalized approaches. The lakehouse structure on Databricks helps all of them.
Unity Catalog options lengthen past observability and discovery with lineage, main keys (PKs), constraints and schema evolution capabilities. They supply essential hints to the Databricks question optimizer, enabling extra environment friendly question plans and enhancing question efficiency. As an illustration, declaring PKs and international keys with RELY permits the optimizer to get rid of redundant joins, straight impacting pace. Unity Catalog’s sturdy assist for schema evolution additionally ensures agility as your information fashions adapt over time. Unity Catalog gives a regular governance mannequin based mostly on ANSI SQL.
Further related assets embody Knowledge Warehousing Modeling Strategies and a three-part sequence on Dimensional Knowledge Warehousing (Half 1, Half 2 and Half 3).
Allow Observability
Activating monitoring and motion tuning choices completely highlights the interconnectedness of knowledge warehouse parts amongst compute, bodily file structure, question effectivity and extra.
- Begin by establishing observability by means of dashboards and purposes.
- Outline discovered patterns for figuring out and diagnosing efficiency bottlenecks after which correcting them.
- Iteratively construct in automation by means of alerting and agentic corrective actions.
- Compile frequent developments inflicting bottlenecks and incorporate them into improvement greatest practices, code evaluate checks and templates.
Steady monitoring is important for sustained excessive, constant efficiency and value effectivity in manufacturing. Understanding commonplace patterns permits one to refine one’s tuning choices as utilization evolves.
Monitor and Regulate: Use every warehouse’s built-in Monitoring tab (AWS | Azure | GCP) for real-time insights into peak concurrent queries, utilization and different key statistics. This gives a fast reference for statement, however needs to be supplemented with additional strategies to drive alerts and motion.
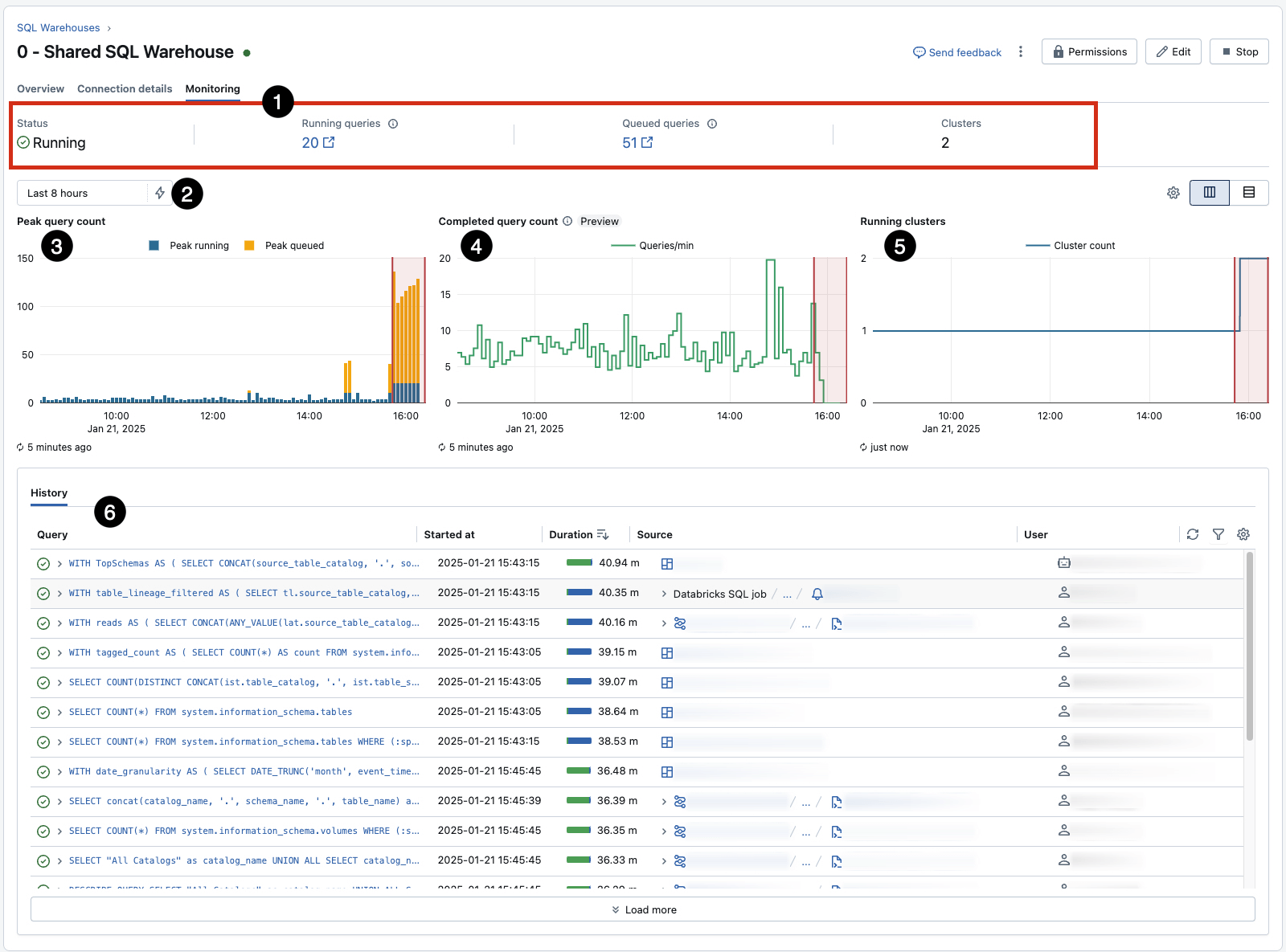
- Pay specific consideration to 3, which reveals queueing because of concurrency limits for a given warehouse (and will be influenced by resizing) and 5, which reveals autoscaling occasions in response to the queue. 6 captures question historical past, a terrific place to begin for figuring out and investigating long-running and inefficient workloads.
Leverage system tables: Helps extra granular, bespoke monitoring. Over time, develop customized dashboards and alerts, however make the most of ready choices:
- The Granular SQL Warehouse Monitoring Dashboard gives a complete view of knowledgeable scaling choices by understanding who and what drives prices.
- The DBSQL Workflow Advisor gives a view throughout scaling, question efficiency to determine bottlenecks and value attribution.
- Introduce customized SQL Alerts (AWS | Azure | GCP) for in-built notifications discovered from the monitoring occasions from the above.
For purchasers interested by price attribution and observability past simply the SQL Warehouse, this devoted weblog, From Chaos to Management: A Value Maturity Journey with Databricks, on the fee maturity journey, is a beneficial useful resource.
Make the most of Question Profiles: The Question Profile (AWS | Azure | GCP) device is your main diagnostic for particular person question efficiency points. It gives detailed execution plans and helps pinpoint bottlenecks that have an effect on required compute.
 |
|

{kind=link}
A number of place to begin recommendations of what to search for from the question profile:
- Examine if pruning happens. If there needs to be pruning (AWS | Azure | GCP) (i.e., decreasing information learn from storage utilizing metadata/statistics of tables), which you’d anticipate if making use of predicates or joins, but it surely’s not occurring, then analyze the file structure technique. Ideally, information/partitions learn needs to be low and information pruned needs to be excessive.
- A big quantity of wall-clock time spent in “Scheduling” (higher than a number of seconds) suggests queuing.
- If the ‘Outcome fetching by consumer’ length takes more often than not, it signifies a possible community subject between the exterior device/utility and SQL warehouse.
- Bytes learn from the cache will differ relying on utilization patterns, as customers operating queries utilizing the identical tables on the identical warehouse will naturally leverage the cached information moderately than re-scanning information.
- The DAG (Directed Acyclic Graph–AWS | Azure | GCP) lets you determine steps by period of time they took, reminiscence utilized and rows learn. This may help slender down efficiency points for extremely advanced queries.
- To detect the small file downside (the place information information are considerably smaller than the optimum dimension, inflicting inefficient processing), ideally, the common file dimension needs to be between 128MB and 1GB, relying on the scale of the desk:
- Nearly all of the question plan spent scanning supply desk(s).
- Run
DESCRIBE DETAIL [Table Name]. To search out the common file dimension, divide thesizeInBytesby thenumFiles. Or, within the question profile, use [Bytes read] / [Files read].
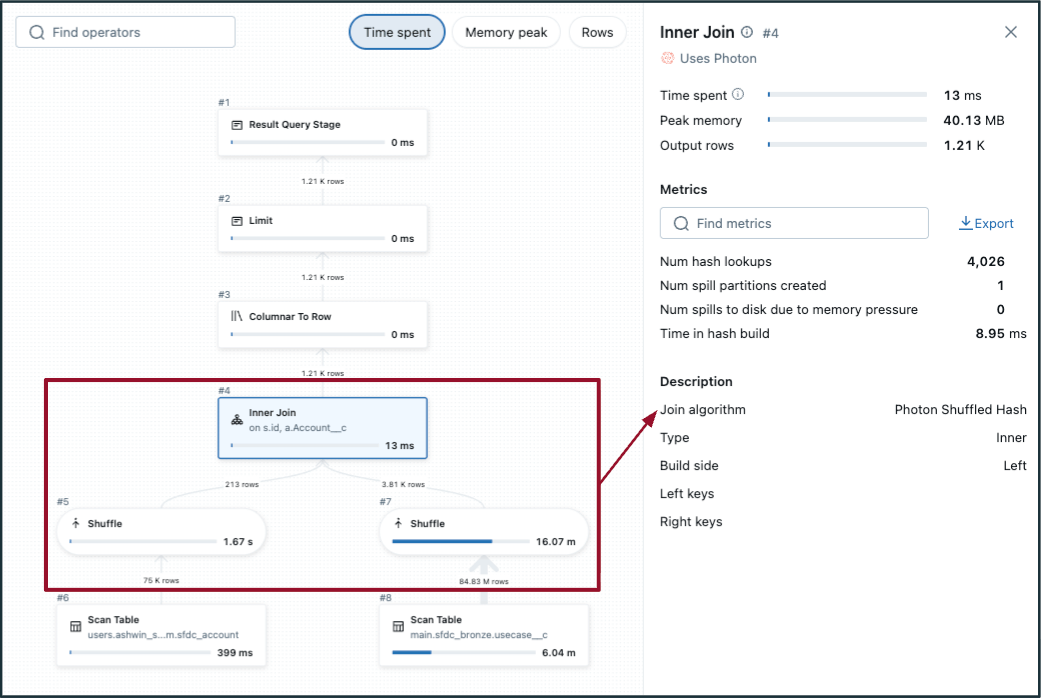
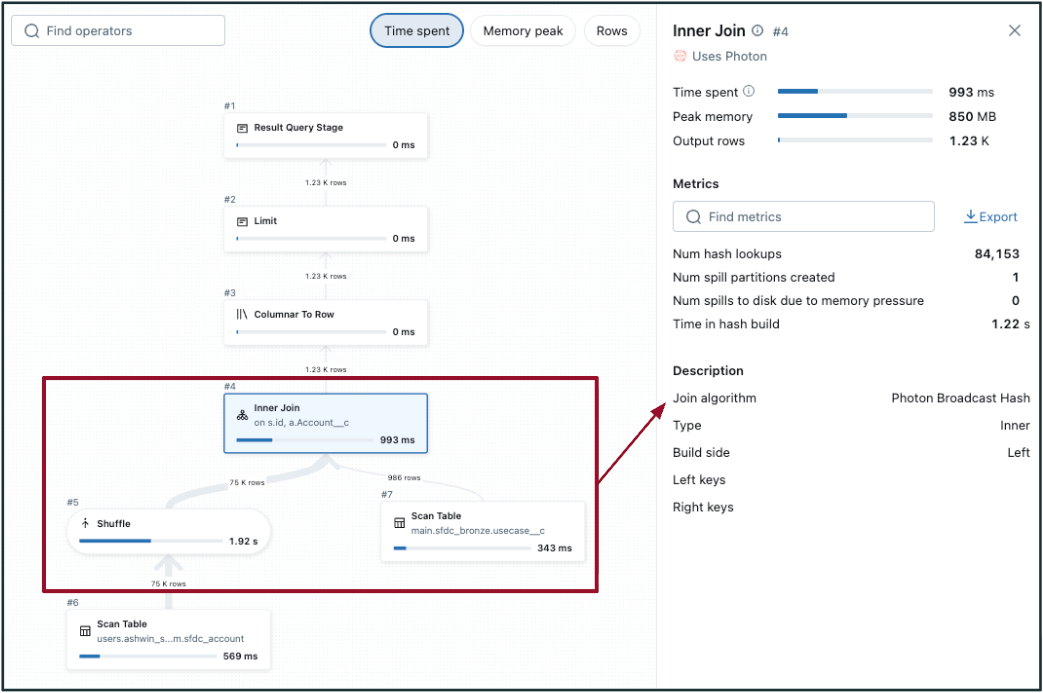
- To detect a doubtlessly inefficient shuffle hash be part of:
- Select the be part of step within the DAG and test the “Be part of algorithm”.
- No/low file pruning.
- Within the DAG, shuffle happens on each tables (on both facet of the be part of, like within the picture to the left). If one of many tables is sufficiently small, take into account broadcasting to carry out a broadcast hash be part of as an alternative (proven within the picture to the fitting).
- Adaptive question execution (AQE) defaults to <=30 MB information dimension for broadcast joins — usually, tables with information dimension lower than 200 MB are good candidates to judge for broadcasting. 1 GB is the exhausting restrict.
- All the time guarantee filters are being utilized to scale back supply datasets.
 |  |
Implement Optimizations and Greatest Practices
Efficiency Points: The 4 S’s + Queuing
Whether or not configuring compute for a brand new workload or optimizing, it’s a necessity to grasp the most typical efficiency points. These match into a typical moniker, “The 4 S’s”, with a fifth (queuing) added on:
To scale back question latency in your SQL warehouse, decide whether or not spill, queuing and/or shuffle (skew and small information will come up later) is the first efficiency bottleneck. This complete information gives extra particulars. After figuring out the basis trigger, apply the rules under to regulate SQL warehouse sizing accordingly and measure the affect.
- Disk Spill (from reminiscence to disk): Spill happens when a SQL warehouse runs out of reminiscence and writes non permanent outcomes to disk, considerably slower than in-memory processing. In a Question Profile, any quantities in opposition to “spill (bytes)” or “spill time” point out that is occurring.
To mitigate spills, enhance the SQL warehouse T-shirt dimension to supply extra reminiscence. Question reminiscence utilization will also be lowered by means of question optimization strategies resembling early filtering, decreasing skew and simplifying joins. Enhancing file structure—utilizing appropriately sized information or making use of Liquid Clustering—can additional restrict the quantity of knowledge scanned and shuffled throughout execution.
Helper question on system tables that may be transformed to a SQL Alert or AI/BI Dashboard
- Question Queuing: If the SQL Warehouse Monitoring display screen reveals persistent queuing (the place peak queued queries are >10) that does not instantly resolve with an autoscaling occasion, enhance the max scaling worth on your warehouse. Queuing straight provides latency as queries anticipate obtainable assets.
Helper question on system tables that may be transformed to a SQL Alert or AI/BI Dashboard
- Excessive Parallelization/Low Shuffle: For queries that may be cut up into many unbiased duties—resembling filters or aggregations throughout giant datasets—and present low shuffle in Question Profiles, growing the SQL warehouse T-shirt dimension can enhance throughput and cut back queuing. Low shuffle signifies minimal information motion between nodes, which permits extra environment friendly parallel execution.
- Slim transformations (e.g., level lookups, combination lookups) usually profit from extra scaling for concurrent question dealing with. Vast transformations (advanced joins with aggregation) usually profit extra from bigger warehouse sizes versus scaling.
- Excessive Shuffle: Conversely, when shuffle is excessive, giant quantities of knowledge are exchanged between nodes throughout question execution—usually because of joins, aggregations or poorly organized information. This generally is a vital efficiency bottleneck. In Question Profiles, excessive shuffle is indicated by giant values below “shuffle bytes written”, “shuffle bytes learn” or lengthy durations in shuffle-related phases. If these metrics are constantly elevated, optimizing the question or enhancing bodily information structure moderately than merely scaling up compute is greatest.
Helper question on system tables that may be transformed to a SQL Alert or AI/BI Dashboard
Taking a Macro Monitoring View
Whereas these analyses and guidelines assist perceive how queries affect the warehouse on the micro stage, sizing choices are made on the macro stage. Usually, begin by enabling the monitoring capabilities within the earlier part (and customise them) to determine what is going on after which set up threshold measures for spill, skew, queuing, and so forth., to function indicators for when resizing is required. Consider these thresholds to generate an affect rating by the frequency with which the thresholds are met or the proportion of time the thresholds are exceeded throughout common operation. To share a number of instance measures (outline these utilizing your particular enterprise necessities and SLAs):
- Share of time every day that peak queued queries > 10
- Queries which are within the prime 5% of highest shuffle for an prolonged interval or constantly within the prime 5% highest shuffle throughout peak utilization
- Durations the place not less than 20% of queries spill to disk or queries that spill to disk on greater than 25% of their executions
It is necessary to floor this in recognizing there are tradeoffs to think about, not a single recipe to observe or one-size-fits-all for each information warehouse. If queue latency just isn’t a priority, doubtlessly for in a single day queries that refresh, then do not tune for ultra-low-concurrency and acknowledge price effectivity with greater latency. This weblog gives a information on greatest practices and methodologies to diagnose and tune your information warehouse based mostly in your distinctive implementation wants.
Optimizing Bodily Knowledge (File) Structure within the Lakehouse
Under are a number of greatest practices for managing and optimizing bodily information information saved in your lakehouse. Use these and monitoring strategies to diagnose and resolve points impacting your information warehouse analytic workloads.
- Regulate the info skipping of a desk (AWS | Azure | GCP) if essential. Delta tables retailer min/max and different statistics metadata for the primary 32 columns by default. Growing this quantity can enhance DML operation execution occasions, however might lower question runtime if the extra columns are filtered in queries.
- To determine if in case you have the small file downside, evaluate desk properties (numFiles, sizeInBytes, clusteringColumns, partitionColumns) and use both Predictive Optimization with Liquid Clustering or make sure you run OPTIMIZE compaction routines on prime of correctly organized information.
- Whereas the advice is to allow Auto Liquid Clustering and make the most of Predictive Optimization to take away guide tuning, it’s useful to grasp underlying greatest practices and be empowered to tune in choose situations manually. Under are helpful guidelines of thumb for choosing clustering columns:
- Begin with a single column, the one most naturally used as a predicate (and utilizing the recommendations under), until there are a number of apparent candidates. Usually, solely enormous tables profit from >1 cluster key.
- Prioritizing columns to make use of prioritizes optimizing reads over writes. They need to be 1) used as filter predicates, 2) utilized in GROUP BY or JOIN operations and three) MERGE columns.
- Usually, it ought to have excessive cardinality (however not distinctive). Keep away from meaningless values like UUID strings until you require fast lookups on these columns.
- Do not cut back cardinality (e.g., convert from timestamp up to now) as you’d when setting a partition column.
- Do not use two associated columns (e.g., timestamp and datestamp)—at all times select the one with the upper cardinality.
- The order of keys within the CREATE TABLE syntax doesn’t matter. Multi-dimensional clustering is used.
Bringing it All Collectively: A Systematic Strategy
This weblog focuses on the primary three architectural levers. Different crucial implementation parts contribute to architecting a high-concurrency, scalable, low-latency information warehouse, together with ETL/ELT, infrastructure footprint, DevOps and Governance. Further product perspective on implementing a lakehouse will be discovered right here, and an array of greatest practices is accessible from the Complete Information to Optimize Databricks, Spark and Delta Lake Workloads.
The foundational parts of your information warehouse—compute, information structure and modeling/querying—are extremely interdependent. Addressing efficiency successfully requires an iterative course of: repeatedly monitoring, optimizing and guaranteeing new workloads adhere to an optimized blueprint. And evolve that blueprint as know-how greatest practices change and your online business necessities change. You need the instruments and know-how to tune your warehouse to fulfill your exact concurrency, latency and scalability necessities. Strong governance, transparency, monitoring and safety allow this core architectural framework. These aren’t separate issues however the bedrock for delivering best-in-class information warehouse experiences on Databricks.
Now, let’s discover a current buyer instance during which the framework and foundational greatest practices, tuning and monitoring levers, have been utilized in follow, and a corporation considerably improved its information warehouse efficiency and effectivity.
Actual-World Eventualities and Tradeoffs
Electronic mail Advertising Platform Optimization
Enterprise Context
An electronic mail advertising platform gives e-commerce retailers with instruments to create personalised buyer journeys based mostly on wealthy buyer information. The appliance permits customers to orchestrate electronic mail campaigns to focused audiences, serving to shoppers craft segmentation methods and observe efficiency. Actual-time analytics are crucial to their enterprise—prospects anticipate rapid visibility into marketing campaign efficiency metrics like click-through charges, bounces and engagement information.
Preliminary Problem
The platform was experiencing efficiency and value points with its analytics infrastructure. They have been operating a Massive SQL Serverless warehouse with autoscaling from 1-5 clusters and even wanted to improve to XL throughout peak reporting intervals. Their structure relied on:
- Actual-time streaming information from a message queue into Delta Lake through steady structured streaming
- A nightly job to consolidate streamed data right into a historic desk
- Question-time unions between the historic desk and streaming information
- Complicated aggregations and deduplication logic executed at question time
This strategy meant that each buyer dashboard refresh required intensive processing, resulting in greater prices and slower response occasions.
From monitoring the SQL warehouse, there was vital queueing (yellow columns), with bursty intervals of utilization, the place autoscaling correctly engaged however was not in a position to sustain with workloads:

To diagnose the reason for queueing, we recognized a number of long-running queries and most incessantly executed queries utilizing the question historical past (AWS | Azure | GCP) and system tables to find out whether or not queueing was merely because of a excessive quantity of comparatively fundamental, slender queries or if optimization was wanted to enhance poor-performing queries.
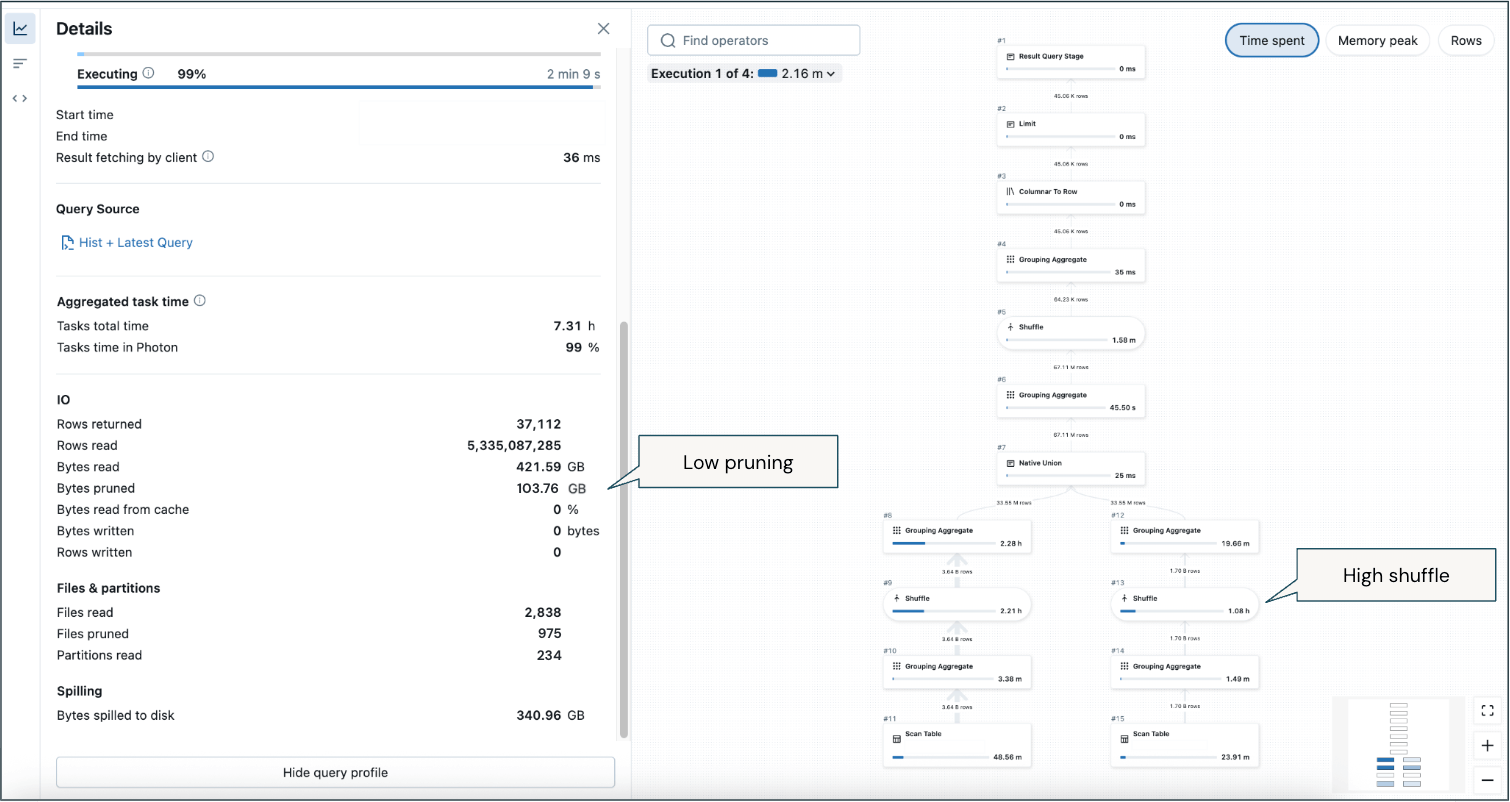
A number of crucial callouts from this instance profile from a long-running question:
- Low pruning (regardless of vital filtering on time interval to return the newest 2 weeks) means a substantial quantity of knowledge is being scanned.
- Excessive shuffle—there’ll inherently be shuffle because of analytical aggregations, however it’s the majority of reminiscence utilization throughout historic and up to date information.
- Spill to disk in some situations.
These learnings from observing crucial queries led to optimization actions throughout compute, information structure and question strategies.
Optimization Strategy
Working with a Databricks Supply Options Architect, the platform carried out a number of key optimizations:
- Elevated merge frequency: Modified from nightly to hourly merges, considerably decreasing the quantity of streaming information that wanted processing at question time.
- Implement Materialized Views: Transformed the aggregation desk right into a materialized view that refreshes incrementally every hour, pre-computing advanced aggregation logic throughout refresh in order that query-time processing is proscribed to solely the newest hour’s information.
- Fashionable information group: Switched from Hive-style partitioning to automated liquid clustering, which intelligently selects optimum clustering columns based mostly on question patterns and adapts over time.
Outcomes
After a six-week discovery and implementation course of, the platform noticed rapid and noteworthy enhancements as soon as deployed:
- Lowered infrastructure prices: Downsized from a Massive serverless warehouse with autoscaling to a Small serverless warehouse with no autoscaling.
- Improved question efficiency: Decrease latency for end-user dashboards, enhancing buyer expertise.
- Streamlined operations: Eradicated operational overhead from frequent end-user efficiency complaints and assist instances.
An instance of a question profile after optimization:
- Because the file structure was optimized, extra file pruning occurred to scale back the quantity of knowledge/information that wanted to be learn.
- No spill to disk.
- Shuffle nonetheless happens due to analytical aggregations, however the quantity of shuffling is considerably lowered because of extra environment friendly pruning and pre-aggregated parts that do not should be calculated at runtime.

This transformation demonstrates how making use of information modeling greatest practices, leveraging serverless compute and using Databricks superior options like materialized views and liquid clustering can dramatically enhance each efficiency and cost-efficiency.
Key Takeaways
- Focus your necessities on information warehouse concurrency, latency and scale. Then, use greatest practices, observability capabilities and tuning strategies to fulfill these necessities.
- Concentrate on right-sizing compute, implementing robust information structure practices (considerably helped by AI) and addressing information fashions and queries because the precedence.
- The very best information warehouse is a Databricks lakehouse—make the most of revolutionary approaches that result in new options, married with foundational information warehouse rules.
- Meet conventional information warehousing wants with out sacrificing AI/ML (you are capitalizing on them with Databricks).
- Do not dimension and tune blindly; leverage built-in observability to watch, optimize and automate cost-saving actions.
- Undertake Databricks SQL Serverless for optimum value efficiency and assist the variable utilization patterns typical of BI and analytics workloads.
Subsequent Steps and Further Sources
Reaching a high-concurrency, low-latency information warehouse that scales doesn’t occur by following a boilerplate recipe. There are tradeoffs to think about, and plenty of parts all work collectively. Whether or not you are cementing your information warehousing technique, in progress with an implementation and struggling to go reside, or optimizing your present footprint, take into account the most effective practices and framework outlined on this weblog to deal with it holistically. Attain out if you would like assist or to debate how Databricks can assist all of your information warehousing wants.
Databricks Supply Options Architects (DSAs) speed up Knowledge and AI initiatives throughout organizations. They supply architectural management, optimize platforms for price and efficiency, improve developer expertise and drive profitable undertaking execution. DSAs bridge the hole between preliminary deployment and production-grade options, working intently with varied groups, together with information engineering, technical leads, executives and different stakeholders to make sure tailor-made options and quicker time to worth. To learn from a customized execution plan, strategic steering and assist all through your information and AI journey from a DSA, please get in contact together with your Databricks Account Group.