

{kind=link}
Databricks is happy to accomplice with OpenAI on GPT-5.5, their newest frontier mannequin. GPT-5.5 is OpenAI’s strongest frontier mannequin for agentic work in enterprise, complicated doc reasoning, and long-horizon coding brokers. GPT-5.5 additionally now powers Codex, OpenAI’s coding agent.
GPT-5.5 Options and Advantages
GPT-5.5 is the neatest frontier mannequin but and the following step towards a brand new manner of getting work achieved. It understands what you’re attempting to do extra shortly and might tackle extra of the work itself. Codex, OpenAI’s coding agent, is now powered by GPT-5.5, with stronger reasoning and execution capabilities for developer workflows.
The identical strengths that make GPT-5.5 nice at coding additionally make it highly effective for on a regular basis work on a pc. As a result of the mannequin is healthier at understanding intent, it might probably transfer extra naturally via the total loop of information work: discovering info, understanding what issues, utilizing instruments, checking the output, and turning uncooked materials into one thing helpful.
It might probably write and debug code, analysis on-line, analyze knowledge, create paperwork and spreadsheets, function software program, and transfer throughout instruments till a activity is completed. As a substitute of fastidiously managing each step, you may give GPT-5.5 a messy, multi-part activity and belief it to plan, use instruments, test its work, recuperate from ambiguity, and hold going.
GPT-5.5 units the state-of-the-art efficiency
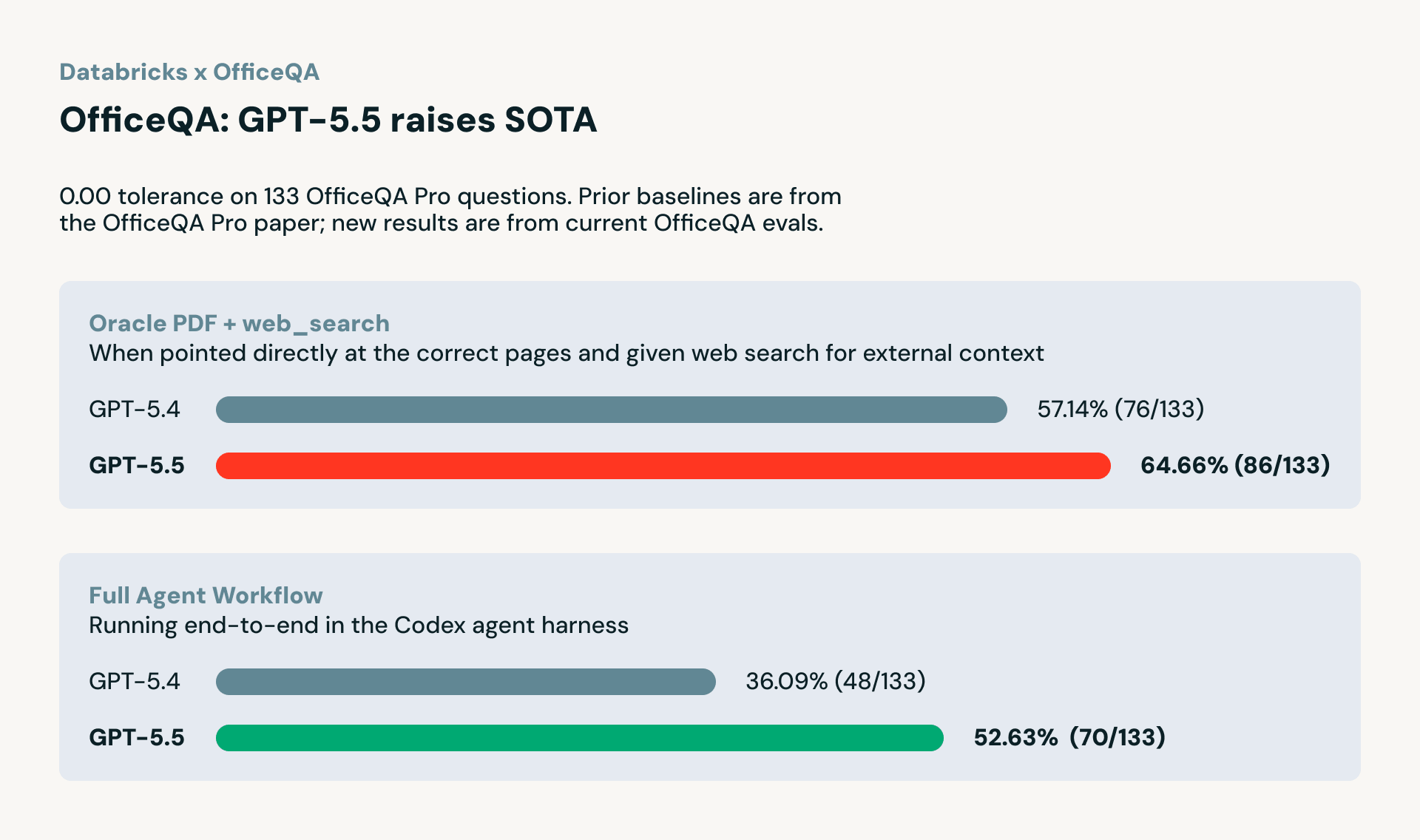
To know how these enhancements translate into actual enterprise workloads, we evaluated GPT-5.5 on OfficeQA, Databricks’ benchmark for document-heavy, multi-step analytical duties prospects carry out each day. OfficeQA, constructed from 89,000 pages of U.S. Treasury Bulletins, measures a mannequin’s capability to retrieve info throughout paperwork, interpret complicated tables, and carry out exact calculations grounded in actual enterprise knowledge.
When given the correct paperwork (OfficeQA Professional LLM with Oracle PDF + Internet Search), GPT-5.5 scored 64.66%, an honest bounce from GPT-5.4’s 57.14%, representing a ~13% enchancment and a brand new state-of-the-art on this benchmark. This checks the ceiling of what the mannequin can do when retrieval is already dealt with.
In a full-agent workflow eval (OfficeQA Professional Agent Harness), the place the mannequin should discover the correct paperwork, parse them, and compute solutions by itself utilizing the Codex agent harness, GPT-5.5 scored 52.63%, up from GPT-5.4’s 36.10%. That is a 46% discount in errors, displaying that GPT-5.5’s beneficial properties aren’t simply theoretical; they maintain up in life like, end-to-end enterprise workflows.
GPT-5.5 is coming quickly to Databricks. Carry frontier reasoning to your enterprise knowledge, securely, and at scale.