

{kind=link}
If you’re looking for free LLM APIs, likelihood is you already wish to construct one thing with AI. A chatbot. A coding assistant. A knowledge evaluation workflow. Or a fast prototype with out burning cash on infrastructure. The excellent news is that you simply now not want paid subscriptions or complicated mannequin internet hosting to get began. Many main AI suppliers now provide free entry to highly effective LLMs by means of APIs, with beneficiant price limits and OpenAI-compatible interfaces. This information brings collectively the finest free LLM APIs obtainable proper now, together with their mannequin choices, request limits, token caps, and actual code examples.
Understanding LLM APIs
LLM APIs function on a simple request-response mannequin:
- Request Submission: Your software sends a request to the API, formatted in JSON, containing the mannequin variant, immediate, and parameters.
- Processing: The API forwards this request to the LLM, which processes it utilizing its NLP capabilities.
- Response Supply: The LLM generates a response, which the API sends again to your software.
Pricing and Tokens
- Tokens: Within the context of LLMs, tokens are the smallest models of textual content processed by the mannequin. Pricing is often based mostly on the variety of tokens used, with separate prices for enter and output tokens.
- Value Administration: Most suppliers provide pay-as-you-go pricing, permitting companies to handle prices successfully based mostly on their utilization patterns.
Free LLM APIs Assets
That will help you get began with out incurring prices, right here’s a complete listing of LLM-free API suppliers, together with their descriptions, benefits, pricing, and token limits.
1. OpenRouter
OpenRouter supplies quite a lot of LLMs for various duties, making it a flexible alternative for builders. The platform permits as much as 20 requests per minute and 200 requests per day.
A number of the notable fashions obtainable embrace:
- DeepSeek R1
- Llama 3.3 70B Instruct
- Mistral 7B Instruct
All obtainable fashions: Hyperlink
Documentation: Hyperlink
Benefits
- Excessive request limits.
- A various vary of fashions.
Pricing: Free tier obtainable.
Instance Code
from openai import OpenAI
consumer = OpenAI(
base_url="https://openrouter.ai/api/v1",
api_key="<OPENROUTER_API_KEY>",
)
completion = consumer.chat.completions.create(
mannequin="cognitivecomputations/dolphin3.0-r1-mistral-24b:free",
messages=[
{
"role": "user",
"content": "What is the meaning of life?"
}
]
)
print(completion.selections[0].message.content material)Output
The that means of life is a profound and multifaceted query explored by means of
numerous lenses of philosophy, faith, science, and private expertise.
This is a synthesis of key views:1. **Existentialism**: Philosophers like Sartre argue life has no inherent
that means. As a substitute, people create their very own goal by means of actions and
selections, embracing freedom and duty.2. **Faith/Spirituality**: Many traditions provide frameworks the place that means
is discovered by means of religion, divine connection, or service to the next trigger. For
instance, in Christianity, it'd relate to fulfilling God's will.3. **Psychology/Philosophy**: Viktor Frankl proposed discovering that means by means of
work, love, and overcoming struggling. Others counsel that means derives from
private progress, relationships, and contributing to one thing significant....
...
...
2. Google AI Studio
Google AI Studio is a robust platform for AI mannequin experimentation, providing beneficiant limits for builders. It permits as much as 1,000,000 tokens per minute and 1,500 requests per day.
Some fashions obtainable embrace:
- Gemini 2.0 Flash
- Gemini 1.5 Flash
All obtainable fashions: Hyperlink
Documentation: Hyperlink
Benefits
- Entry to highly effective fashions.
- Excessive token limits.
Pricing: Free tier obtainable.
Instance Code
from google import genai
consumer = genai.Consumer(api_key="YOUR_API_KEY")
response = consumer.fashions.generate_content(
mannequin="gemini-2.0-flash",
contents="Clarify how AI works",
)
print(response.textual content)Output
/usr/native/lib/python3.11/dist-packages/pydantic/_internal/_generate_schema.py:502: UserWarning: <built-in
operate any> is just not a Python sort (it could be an occasion of an object),
Pydantic will permit any object with no validation since we can't even
implement that the enter is an occasion of the given sort. To eliminate this
error wrap the kind with `pydantic.SkipValidation`.warn(
Okay, let's break down how AI works, from the high-level ideas to a few of
the core strategies. It is a huge discipline, so I am going to attempt to present a transparent and
accessible overview.**What's AI, Actually?**
At its core, Synthetic Intelligence (AI) goals to create machines or programs
that may carry out duties that sometimes require human intelligence. This
contains issues like:* **Studying:** Buying data and guidelines for utilizing the data
* **Reasoning:** Utilizing data to attract conclusions, make predictions,
and clear up issues....
...
...
3. Mistral (La Plateforme)
Mistral presents quite a lot of fashions for various purposes, specializing in excessive efficiency. The platform permits 1 request per second and 500,000 tokens per minute. Some fashions obtainable embrace:
- mistral-large-2402
- mistral-8b-latest
All obtainable fashions: Hyperlink
Documentation: Hyperlink
Benefits
- Excessive request limits.
- Concentrate on experimentation.
Pricing: Free tier obtainable.
Instance Code
import os
from mistralai import Mistral
api_key = os.environ["MISTRAL_API_KEY"]
mannequin = "mistral-large-latest"
consumer = Mistral(api_key=api_key)
chat_response = consumer.chat.full(
mannequin= mannequin,
messages = [
{
"role": "user",
"Content": "What is the best French cheese?",
},
]
)
print(chat_response.selections[0].message.content material)Output
The "finest" French cheese will be subjective because it depends upon private style
preferences. Nonetheless, a number of the most well-known and extremely regarded French
cheeses embrace:1. Roquefort: A blue-veined sheep's milk cheese from the Massif Central
area, recognized for its robust, pungent taste and creamy texture.2. Brie de Meaux: A mushy, creamy cow's milk cheese with a white rind,
originating from the Brie area close to Paris. It's recognized for its gentle,
buttery taste and will be loved at varied levels of ripeness.3. Camembert: One other mushy, creamy cow's milk cheese with a white rind,
much like Brie de Meaux, however usually extra pungent and runny. It comes from
the Normandy area....
...
...
4. HuggingFace Serverless Inference
HuggingFace supplies a platform for deploying and utilizing varied open fashions. It’s restricted to fashions smaller than 10GB and presents variable credit monthly.
Some fashions obtainable embrace:
All obtainable fashions: Hyperlink
Documentation: Hyperlink
Benefits
- Big selection of fashions.
- Straightforward integration.
Pricing: Variable credit monthly.
Instance Code
from huggingface_hub import InferenceClient
consumer = InferenceClient(
supplier="hf-inference",
api_key="hf_xxxxxxxxxxxxxxxxxxxxxxxx"
)
messages = [
{
"role": "user",
"content": "What is the capital of Germany?"
}
]
completion = consumer.chat.completions.create(
mannequin="meta-llama/Meta-Llama-3-8B-Instruct",
messages=messages,
max_tokens=500,
)
print(completion.selections[0].message)Output
ChatCompletionOutputMessage(function="assistant", content material="The capital of Germany
is Berlin.", tool_calls=None)
5. Cerebras
Cerebras supplies entry to Llama fashions with a concentrate on excessive efficiency. The platform permits 30 requests per minute and 60,000 tokens per minute.
Some fashions obtainable embrace:
- Llama 3.1 8B
- Llama 3.3 70B
All obtainable fashions: Hyperlink
Documentation: Hyperlink
Benefits
- Excessive request limits.
- Highly effective fashions.
Pricing: Free tier obtainable, be a part of the waitlist
Instance Code
import os
from cerebras.cloud.sdk import Cerebras
consumer = Cerebras(
api_key=os.environ.get("CEREBRAS_API_KEY"),
)
chat_completion = consumer.chat.completions.create(
messages=[
{"role": "user", "content": "Why is fast inference important?",}
],
mannequin="llama3.1-8b",
)Output
Quick inference is essential in varied purposes as a result of it has a number of
advantages, together with:1. **Actual-time choice making**: In purposes the place choices should be
made in real-time, akin to autonomous automobiles, medical analysis, or on-line
advice programs, quick inference is important to keep away from delays and
guarantee well timed responses.2. **Scalability**: Machine studying fashions can course of a excessive quantity of information
in real-time, which requires quick inference to maintain up with the tempo. This
ensures that the system can deal with massive numbers of customers or occasions with out
important latency.3. **Power effectivity**: In deployment environments the place energy consumption
is proscribed, akin to edge units or cell units, quick inference may help
optimize power utilization by decreasing the time spent on computations....
...
...
6. Groq
Groq presents varied fashions for various purposes, permitting 1,000 requests per day and 6,000 tokens per minute.
Some fashions obtainable embrace:
- DeepSeek R1 Distill Llama 70B
- Gemma 2 9B Instruct
All obtainable fashions: Hyperlink
Documentation: Hyperlink
Benefits
- Excessive request limits.
- Numerous mannequin choices.
Pricing: Free tier obtainable.
Instance Code
import os
from groq import Groq
consumer = Groq(
api_key=os.environ.get("GROQ_API_KEY"),
)
chat_completion = consumer.chat.completions.create(
messages=[
{
"role": "user",
"content": "Explain the importance of fast language models",
}
],
mannequin="llama-3.3-70b-versatile",
)
print(chat_completion.selections[0].message.content material)Output
Quick language fashions are essential for varied purposes and industries, and
their significance will be highlighted in a number of methods:1. **Actual-Time Processing**: Quick language fashions allow real-time processing
of enormous volumes of textual content information, which is important for purposes akin to:* Chatbots and digital assistants (e.g., Siri, Alexa, Google Assistant) that
want to reply shortly to consumer queries.* Sentiment evaluation and opinion mining in social media, buyer suggestions,
and assessment platforms.* Textual content classification and filtering in e mail purchasers, spam detection, and content material moderation.
2. **Improved Person Expertise**: Quick language fashions present on the spot responses, which is significant for:
* Enhancing consumer expertise in search engines like google and yahoo, advice programs, and
content material retrieval purposes.* Supporting real-time language translation, which is important for international
communication and collaboration.* Facilitating fast and correct textual content summarization, which helps customers to
shortly grasp the details of a doc or article.3. **Environment friendly Useful resource Utilization**: Quick language fashions:
* Cut back the computational assets required for coaching and deployment,
making them extra energy-efficient and cost-effective.* Allow the processing of enormous volumes of textual content information on edge units, such
as smartphones, sensible house units, and wearable units....
...
...
7. Scaleway Generative Free API
Scaleway presents quite a lot of generative fashions totally free, with 100 requests per minute and 200,000 tokens per minute.
Some fashions obtainable embrace:
- BGE-Multilingual-Gemma2
- Llama 3.1 70B Instruct
All obtainable fashions: Hyperlink
Documentation: Hyperlink
Benefits
- Beneficiant request limits.
- Number of fashions.
Pricing: Free beta till March 2025.
Instance Code
from openai import OpenAI
# Initialize the consumer along with your base URL and API key
consumer = OpenAI(
base_url="https://api.scaleway.ai/v1",
api_key="<SCW_API_KEY>"
)
# Create a chat completion for Llama 3.1 8b instruct
completion = consumer.chat.completions.create(
mannequin="llama-3.1-8b-instruct",
messages=[{"role": "user", "content": "Describe a futuristic city with advanced technology and green energy solutions."}],
temperature=0.7,
max_tokens=100
)
# Output the outcome
print(completion.selections[0].message.content material)Output
**Luminaria Metropolis 2125: A Beacon of Sustainability**Perched on a coastal cliff, Luminaria Metropolis is a marvel of futuristic
structure and progressive inexperienced power options. This self-sustaining
metropolis of the 12 months 2125 is a testomony to humanity's capability to engineer
a greater future.**Key Options:**
1. **Power Harvesting Grid**: A community of piezoelectric tiles masking the
metropolis's streets and buildings generates electrical energy from footsteps,
vibrations, and wind currents. This decentralized power system reduces
reliance on fossil fuels and makes Luminaria Metropolis almost carbon-neutral.2. **Photo voltaic Skiescraper**: This 100-story skyscraper contains a distinctive double-
glazed facade with energy-generating home windows that amplify photo voltaic radiation,
offering as much as 300% extra illumination and 50% extra power for the town's
houses and companies....
...
...
8. OVH AI Endpoints
OVH supplies entry to varied AI fashions totally free, permitting 12 requests per minute. Some fashions obtainable embrace:
- CodeLlama 13B Instruct
- Llama 3.1 70B Instruct
Documentation and All obtainable fashions:https://endpoints.ai.cloud.ovh.web/
Benefits
- Straightforward to make use of.
- Number of fashions.
Pricing: Free beta obtainable.
Instance Code
import os
from openai import OpenAI
consumer = OpenAI(
base_url="https://llama-2-13b-chat-hf.endpoints.kepler.ai.cloud.ovh.web/api/openai_compat/v1",
api_key=os.getenv("OVH_AI_ENDPOINTS_ACCESS_TOKEN")
)
def chat_completion(new_message: str) -> str:
history_openai_format = [{"role": "user", "content": new_message}]
return consumer.chat.completions.create(
mannequin="Llama-2-13b-chat-hf",
messages=history_openai_format,
temperature=0,
max_tokens=1024
).selections.pop().message.content material
if __name__ == '__main__':
print(chat_completion("Write a narrative within the type of James Joyce. The story needs to be a couple of journey to the Irish countryside in 2083, to see the gorgeous surroundings and robots.d"))Output
Certain, I might be blissful to assist! This is a narrative within the type of James Joyce, set
within the Irish countryside in 2083: As I stepped off the pod-train and onto
the luxurious inexperienced grass of the countryside, the crisp air crammed my lungs and
invigorated my senses. The 12 months was 2083, and but the rolling hills and
glowing lakes of Eire appeared unchanged by the passage of time. The one
distinction was the presence of robots, their modern metallic our bodies and
glowing blue eyes a testomony to the developments of expertise. I had come
to this place in search of solace and inspiration, to lose myself within the magnificence
of nature and the marvel of machines. As I wandered by means of the hills, I
got here throughout a bunch of robots tending to a discipline of crops, their delicate
actions and exact calculations making certain a bountiful harvest. One of many
robots, a modern and agile mannequin with wings like a dragonfly, fluttered over
to me and provided a pleasant greeting. "Good day, traveler," it mentioned in a
melodic voice. "What brings you to our humble abode?" I defined my need
to expertise the great thing about the Irish countryside, and the robotic nodded
sympathetically.
9. Collectively Free API
Collectively is a collaborative platform for accessing varied LLMs, with no particular limits talked about. Some fashions obtainable embrace:
- Llama 3.2 11B Imaginative and prescient Instruct
- DeepSeek R1 Distil Llama 70B
All obtainable fashions: Hyperlink
Documentation: Hyperlink
Benefits
- Entry to a spread of fashions.
- Collaborative atmosphere.
Pricing: Free tier obtainable.
Instance Code
from collectively import Collectively
consumer = Collectively()
stream = consumer.chat.completions.create(
mannequin="meta-llama/Meta-Llama-3.1-8B-Instruct-Turbo",
messages=[{"role": "user", "content": "What are the top 3 things to do in New York?"}],
stream=True,
)
for chunk in stream:
print(chunk.selections[0].delta.content material or "", finish="", flush=True)Output
The town that by no means sleeps - New York! There are numerous issues to see and
do within the Large Apple, however listed below are the highest 3 issues to do in New York:1. **Go to the Statue of Liberty and Ellis Island**: Take a ferry to Liberty
Island to see the long-lasting Statue of Liberty up shut. It's also possible to go to the
Ellis Island Immigration Museum to study concerning the historical past of immigration in
the US. It is a must-do expertise that provides breathtaking
views of the Manhattan skyline.2. **Discover the Metropolitan Museum of Artwork**: The Met, because it's
affectionately recognized, is among the world's largest and most well-known museums.
With a group that spans over 5,000 years of human historical past, you may discover
every part from historical Egyptian artifacts to fashionable and modern artwork.
The museum's grand structure and exquisite gardens are additionally price
exploring.3. **Stroll throughout the Brooklyn Bridge**: This iconic bridge presents gorgeous
views of the Manhattan skyline, the East River, and Brooklyn. Take a
leisurely stroll throughout the bridge and cease on the Brooklyn Bridge Park for
some nice foods and drinks choices. It's also possible to go to the Brooklyn Bridge's
pedestrian walkway, which presents spectacular views of the town.After all, there are a lot of extra issues to see and do in New York, however these
three experiences are an amazing start line for any customer....
...
...
10. GitHub Fashions – Free API
GitHub presents a group of varied AI fashions, with price limits depending on the subscription tier.
Some fashions obtainable embrace:
- AI21 Jamba 1.5 Massive
- Cohere Command R
Documentation and All obtainable fashions: Hyperlink
Benefits
- Entry to a variety of fashions.
- Integration with GitHub.
Pricing: Free with a GitHub account.
Instance Code
import os
from openai import OpenAI
token = os.environ["GITHUB_TOKEN"]
endpoint = "https://fashions.inference.ai.azure.com"
model_name = "gpt-4o"
consumer = OpenAI(
base_url=endpoint,
api_key=token,
)
response = consumer.chat.completions.create(
messages=[
{
"role": "system",
"content": "You are a helpful assistant.",
},
{
"role": "user",
"content": "What is the capital of France?",
}
],
temperature=1.0,
top_p=1.0,
max_tokens=1000,
mannequin=model_name
)
print(response.selections[0].message.content material)Output
The capital of France is **Paris**.
11. Fireworks AI – Free API
Fireworks provide a spread of varied highly effective AI fashions, with Serverless inference as much as 6,000 RPM, 2.5 billion tokens/day.
Some fashions obtainable embrace:
- Llama-v3p1-405b-instruct.
- deepseek-r1
All obtainable fashions: Hyperlink
Documentation: Hyperlink
Benefits
- Value-effective customization
- Quick Inferencing.
Pricing: Free credit can be found for $1.
Instance Code
from fireworks.consumer import Fireworks
consumer = Fireworks(api_key="<FIREWORKS_API_KEY>")
response = consumer.chat.completions.create(
mannequin="accounts/fireworks/fashions/llama-v3p1-8b-instruct",
messages=[{
"role": "user",
"content": "Say this is a test",
}],
)
print(response.selections[0].message.content material)Output
I am prepared for the check! Please go forward and supply the questions or immediate
and I am going to do my finest to reply.
12. Cloudflare Employees AI
Cloudflare Employees AI offers you serverless entry to LLMs, embeddings, picture, and audio fashions. It features a free allocation of 10,000 Neurons per day (Neurons are Cloudflare’s unit for GPU compute), and limits reset every day at 00:00 UTC.
Some fashions obtainable embrace:
- @cf/meta/llama-3.1-8b-instruct
- @cf/mistral/mistral-7b-instruct-v0.1
- @cf/baai/bge-m3 (embeddings)
- @cf/black-forest-labs/flux-1-schnell (picture)
All obtainable fashions: Hyperlink
Documentation: Hyperlink
Benefits
- Free every day utilization for fast prototyping
- OpenAI-compatible endpoints for chat completions and embeddings
- Large mannequin catalog throughout duties (LLM, embeddings, picture, audio)
Pricing: Free tier obtainable (10,000 Neurons/day). Pay-as-you-go above that on Employees Paid.
Instance Code
import os
import requests
ACCOUNT_ID = "YOUR_CLOUDFLARE_ACCOUNT_ID"
API_TOKEN = "YOUR_CLOUDFLARE_API_TOKEN"
response = requests.put up( f"https://api.cloudflare.com/consumer/v4/accounts/{ACCOUNT_ID}/ai/v1/responses",
headers={"Authorization": f"Bearer {AUTH_TOKEN}"},
json={
"mannequin": "@cf/openai/gpt-oss-120b",
"enter": "Inform me all about PEP-8"
}
)
outcome = response.json()
from IPython.show import Markdown
Markdown(outcome["output"][1]["content"][0]["text"]) Output
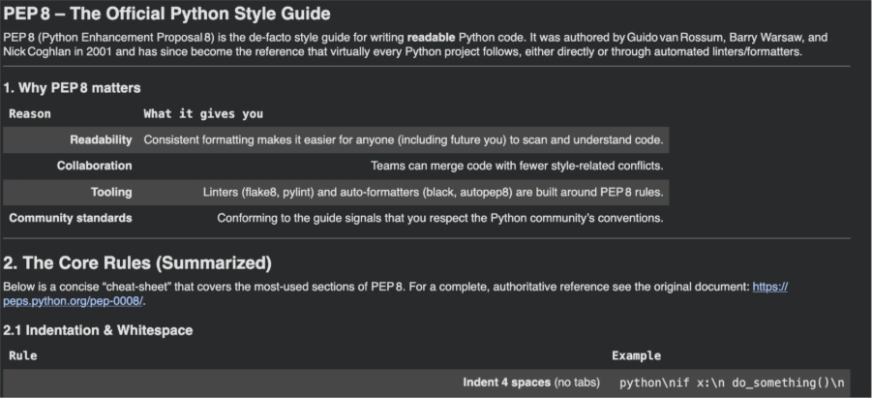
NVIDIA’s API Catalog (construct.nvidia.com) supplies entry to many NIM-powered mannequin endpoints. NVIDIA states that Developer Program members get free entry to NIM API endpoints for prototyping, and the API Catalog is a trial expertise with price limits that modify per mannequin (you’ll be able to test limits in your construct.nvidia.com account UI).
Some fashions obtainable embrace:
- deepseek-ai/deepseek-r1
- ai21labs/jamba-1.5-mini-instruct
- google/gemma-2-9b-it
- nvidia/llama-3.1-nemotron-nano-vl-8b-v1
All obtainable fashions: Hyperlink
Documentation: Hyperlink
Benefits
- OpenAI-compatible chat completions API
- Massive catalog for analysis and prototyping
- Clear observe on prototyping vs manufacturing licensing (AI Enterprise for manufacturing use)
Pricing: Free prototyping entry through NVIDIA Developer Program; manufacturing use requires applicable licensing.
Instance Code
from openai import OpenAI
consumer = OpenAI(
base_url = "https://combine.api.nvidia.com/v1",
api_key="YOUR_NVIDIA_API_KEY"
)
completion = consumer.chat.completions.create(
mannequin="deepseek-ai/deepseek-v3.2",
messages=[{"role":"user","content":"WHat is PEP-8"}],
temperature=1,
top_p=0.95,
max_tokens=8192,
extra_body={"chat_template_kwargs": {"considering":True}},
stream=True
)
for chunk in completion:
if not getattr(chunk, "selections", None):
proceed
reasoning = getattr(chunk.selections[0].delta, "reasoning_content", None)
if reasoning:
print(reasoning, finish="")
if chunk.selections[0].delta.content material is not None:
print(chunk.selections[0].delta.content material, finish="")Output

14. Cohere
Cohere supplies a free analysis/trial key expertise, however trial keys are rate-limited. Cohere’s docs listing trial limits like 1,000 API calls monthly and per-endpoint request limits.
Some fashions obtainable embrace:
- Command A
- Command R
- Command R+
- Embed v3 (embeddings)
- Rerank fashions
All obtainable fashions: Hyperlink
Documentation: Hyperlink
Benefits
- Robust chat fashions (Command household) plus embeddings and rerank for RAG/search
- Easy Python SDK setup (ClientV2)
- Clear revealed trial limits for predictable testing
Pricing: Free trial/analysis entry obtainable (rate-limited), paid plans for increased utilization.
Instance Code
import cohere
co = cohere.ClientV2("YOUR_COHERE_API_KEY")
response = co.chat(
mannequin="command-a-03-2025",
messages=[{"role": "user", "content": "Tell me about PEP8"}],
)
from IPython.show import Markdown
Markdown(response.message.content material[0].textual content) Output

15.AI21 Labs
AI21 presents a free trial that features $10 in credit for as much as 3 months (no bank card required, per their pricing web page). Their basis fashions embrace Jamba variants, and their revealed price limits for basis fashions are 10 RPS and 200 RPM (Jamba Massive and Jamba Mini).
Some fashions obtainable embrace:
All obtainable fashions: Hyperlink
Documentation: Hyperlink
Benefits
- Clear free-trial credit to experiment with out cost particulars
- Easy SDK + REST endpoint for chat completions
- Revealed per-model price limits for predictable load testing
Pricing: Free trial credit obtainable; paid utilization after credit are consumed.
Instance Code
from ai21 import AI21Client
from ai21.fashions.chat import ChatMessage
messages = [
ChatMessage(role="user", content="What is PEP8?"),
]
consumer = AI21Client(api_key="YOUR_API_KEY")
outcome = consumer.chat.completions.create(
messages=messages,
mannequin="jamba-large",
max_tokens=1024,
)
from IPython.show import Markdown
Markdown(outcome.selections[0].message.content material) Output

Advantages of Utilizing Free APIs
Listed here are a number of the advantages of utilizing Free APIs:
- Accessibility: No want for deep AI experience or infrastructure funding.
- Customization: High quality-tune fashions for particular duties or domains.
- Scalability: Deal with massive volumes of requests as your corporation grows.
Ideas for Environment friendly Use of Free APIs
Listed here are some suggestions. to make environment friendly use of Free APIs, coping with their shortcoming and limitations:
- Select the Proper Mannequin: Begin with less complicated fashions for fundamental duties and scale up as wanted.
- Monitor Utilization: Use dashboards to trace token consumption and set spending limits.
- Optimize Tokens: Craft concise prompts to reduce token utilization whereas nonetheless attaining desired outcomes.
Additionally Learn:
Conclusion
With the provision of those free APIs, builders and companies can simply combine superior AI capabilities into their purposes with out important upfront prices. By leveraging these assets, you’ll be able to improve consumer experiences, automate duties, and drive innovation in your initiatives. Begin exploring these APIs at the moment and unlock the potential of AI in your purposes.
Continuously Requested Questions
A. An LLM API permits builders to entry massive language fashions through HTTP requests, enabling duties like textual content era, summarization, and reasoning with out internet hosting the mannequin themselves.
A. Free LLM APIs are perfect for studying, prototyping, and small-scale purposes. For manufacturing workloads, paid tiers often provide increased reliability and limits.
A. In style choices embrace OpenRouter, Google AI Studio, Hugging Face Inference, Groq, and Cloudflare Employees AI, relying on use case and price limits.
A. Sure. Many free LLM APIs assist chat completions and are appropriate for constructing chatbots, assistants, and inside instruments.
Harsh Mishra is an AI/ML Engineer who spends extra time speaking to Massive Language Fashions than precise people. Keen about GenAI, NLP, and making machines smarter (so that they don’t change him simply but). When not optimizing fashions, he’s most likely optimizing his espresso consumption. 🚀☕
Login to proceed studying and revel in expert-curated content material.