

{kind=link}
In our earlier put up, A information to Airflow employee pool optimization in Amazon MWAA, we explored when including staff to your Amazon Managed Workflows for Apache Airflow (Amazon MWAA) surroundings really solves efficiency points, and when it doesn’t. We walked by means of patterns like excessive CPU utilization and lengthy queue occasions the place scaling could also be applicable, and anti-patterns like misconfigured Airflow settings and reminiscence leaks the place including staff solely masks the actual drawback. The important thing takeaway was clear: optimize first, scale second, and all the time let information drive the choice.
However what occurs after you’ve completed the optimization work? Your DAGs are environment friendly, your configurations are tuned, and your surroundings is working properly. Then the enterprise comes knocking: new regulatory necessities, further information pipelines, expanded reporting. The workload is about to develop, and this time, you genuinely want extra capability.
That is the place capability planning is available in. Realizing what number of staff to provision, earlier than the brand new workload hits manufacturing, is the distinction between a easy rollout and a 5 AM SLA breach. On this put up, we stroll by means of a sensible capability planning framework for Amazon MWAA employee swimming pools. Utilizing a real-world monetary providers situation, we present find out how to assess your present capability, mission future wants, calculate the precise variety of base staff, and arrange monitoring to maintain your surroundings wholesome as workloads evolve.
Situation: A monetary providers firm must plan capability for a 25% directed acyclic graph (DAG) improve to assist new regulatory reporting necessities.
Present vs projected state
The next desk compares the present and anticipated state after including 25% extra DAGs.
| Metric | Present | Projected | Change | |
| 1 | DAGs | 20 | 25 | 25% |
| 2 | Peak Duties (5-7 AM) | 80 | 104 | +24 duties |
| 3 | Atmosphere Class | mw1.medium | mw1.medium | No change |
| 4 | Base Employees | 8 | 11 | +3 staff |
| 5 | Duties per Employee | 10 (mw1.medium default) | 10 | No change |
| 6 | Obtainable Capability | 80 slots (8 × 10) | 110 slots (11 × 10) | +30 slots |
| 7 | Peak Utilization | 100% (80/80 slots) ⚠️ | 95% (104/110 slots) | Improved |
| 8 | Crucial SLA | 7 AM market open | 7 AM market open | No tolerance |
Capability planning aim: Scale back utilization from 100% to 95% to take care of service stage settlement (SLA) compliance and deal with sudden spikes.
Understanding present capability: The surroundings presently runs 8 base staff, offering 80 concurrent activity slots (8 staff × 10 duties per employee). Throughout the 5-7 AM peak with 80 concurrent duties, this represents 100% utilization, a dangerous stage that leaves no headroom for sudden spikes or volatility.
With the deliberate addition of 5 new regulatory reporting DAGs, peak concurrent duties will develop to 104. To take care of wholesome operations with sufficient buffer, we have to improve to 11 base staff (110 slots), leading to 95% peak utilization with 6 slots of respiration room.
Why 100% utilization is dangerous: Operating at 100% activity utilization means:
- Zero buffer for sudden spikes
- Any further activity causes fast queuing
- No room for market volatility or information quantity will increase
- Excessive danger of SLA breaches throughout unpredictable occasions
Greatest follow: Preserve a minimum of 5-15% headroom (85-95% utilization) for manufacturing workloads with important SLAs.
Why this sizing:
- Present: 80 duties ÷ 80 slots = 100% utilization (at capability – dangerous!)
- Projected: 104 duties ÷ 110 slots = 95% utilization (wholesome with buffer)
- Buffer: 6 slots (5% headroom) protects in opposition to sudden volatility spikes
- SLA safety: Ample headroom prevents queuing throughout regular operations
Capability evaluation
Each workforce asks the identical important query: “What number of staff do I would like?” The method is to determine your peak concurrent duties from Amazon CloudWatch metrics, dividing by your surroundings’s tasks-per-worker capability, and including a 5%-15% security buffer.
Step 1: Figuring out peak concurrent duties from Amazon CloudWatch
To find out your peak workload, it’s essential to analyze RunningTasks and QueuedTasks CloudWatch metrics in your Amazon MWAA surroundings. Navigate to Amazon CloudWatch and question the next key metrics:
Main metrics for capability planning:
- RunningTasks: Variety of duties presently executing throughout all staff. This exhibits your precise concurrent activity load.
- QueuedTasks: Variety of duties ready for out there employee slots. Excessive values point out inadequate capability.
- AvailableWorkers: Present variety of energetic staff in your surroundings.
Tips on how to discover peak concurrent duties:
- Open the Amazon CloudWatch Console.
- Select Metrics.
- Select the MWAA namespace.
- Choose your surroundings title.
- Add the
RunningTasksmetric. - Set time vary to final 7-30 days.
- Change statistic to Most.
- Determine the very best worth throughout your peak hours (for instance, 5-7 AM).
Instance question:
Be aware: The next question is conceptual and doesn’t straight translate to Amazon CloudWatch-specific language. Please check with the Question your CloudWatch metrics with CloudWatch Metrics Insights for extra info.
In our situation, this evaluation revealed 80 concurrent duties through the 5-7 AM window. With the deliberate 25% DAG improve, we mission this may develop to 104 concurrent duties.
Step 2: Calculate required staff
To calculate the variety of required staff with out queuing any duties, use the next method: Peak concurrent duties ÷ Duties per employee × Security buffer = Required staff
Within the projected situation with 104 duties at peak hours, utilizing mw1.medium surroundings with default concurrency configuration and having a 5% security buffer, we’d like 11 staff
- 104 peak duties ÷ 10 duties per employee × 1.06 buffer = 11 staff required to deal with your workload with out queuing throughout busiest intervals.
Capability monitoring and triggers
There are a number of necessary Amazon CloudWatch metrics to watch for surroundings well being.
Key metrics to watch
Monitor these 5 important Amazon CloudWatch metrics to detect capability points:
- QueuedTasks (>10 for >5 minutes signifies inadequate capability)
- RunningTasks (persistently at most suggests the necessity for extra staff)
- AdditionalWorkers (energetic for greater than 6 hours day by day alerts the everlasting employee drawback)
- Employee CPU (>85% sustained requires surroundings class improve or workload optimization)
- Process Length (+15% improve means diminished efficient capability per employee).
These metrics present early warning alerts to regulate capability earlier than SLA breaches happen.
| Metric | Threshold | Motion | |
| 1 | QueuedTasks | >10 for >5 minutes | Examine capability |
| 2 | RunningTasks | Constantly at max | Enhance base staff |
| 3 | AdditionalWorkers | Lively >6 hours day by day | Enhance base staff |
| 4 | Employee CPU | >85% sustained | Improve surroundings class |
| 5 | Process Length | +15% improve | Evaluate capability per employee |
Amazon CloudWatch monitoring queries
Be aware: The next queries are conceptual and don’t straight translate to Amazon CloudWatch-specific language. Please check with the Question your CloudWatch metrics with CloudWatch Metrics Insights for extra info.
- Queue depth throughout peak hours
- Employee utilization effectivity
- Detect everlasting employee drawback
Establishing alerts
You possibly can configure these alarms to determine issues as quickly as they’re launched.
Advisable Amazon CloudWatch alarms:
- Excessive queue depth alert
- Metric: QueuedTasks
- Threshold: > 10 for two consecutive 5-minute intervals
- Motion: Notify operations workforce
- Everlasting employee detection
- Metric: AdditionalWorkers
- Threshold: > 0 for six+ hours
- Motion: Evaluate capability planning
- SLA danger alert
- Metric: QueuedTasks throughout 5-7 AM window
- Threshold: > 5 duties
- Motion: Web page on-call engineer
When to revisit capability planning
Conduct quarterly scheduled critiques to investigate tendencies and mission progress. Additionally run fast trigger-based assessments when:
- DAG depend will increase >10% (or greater than your security buffer)
- Efficiency degrades
- Price anomalies seem (indicating everlasting staff)
- Any SLA breach happens.
This twin strategy supplies proactive capability administration whereas enabling speedy response to rising points.
| Set off | Frequency | Motion | |
| 1 | Scheduled Evaluate | Quarterly | Analyze tendencies, mission progress |
| 2 | DAG Progress | >10% improve | Recalculate capability wants |
| 3 | Efficiency Degradation | As noticed | Fast capability evaluation |
| 4 | Price Anomalies | Month-to-month | Test for everlasting staff |
| 5 | SLA Breaches | Any prevalence | Emergency capability assessment |
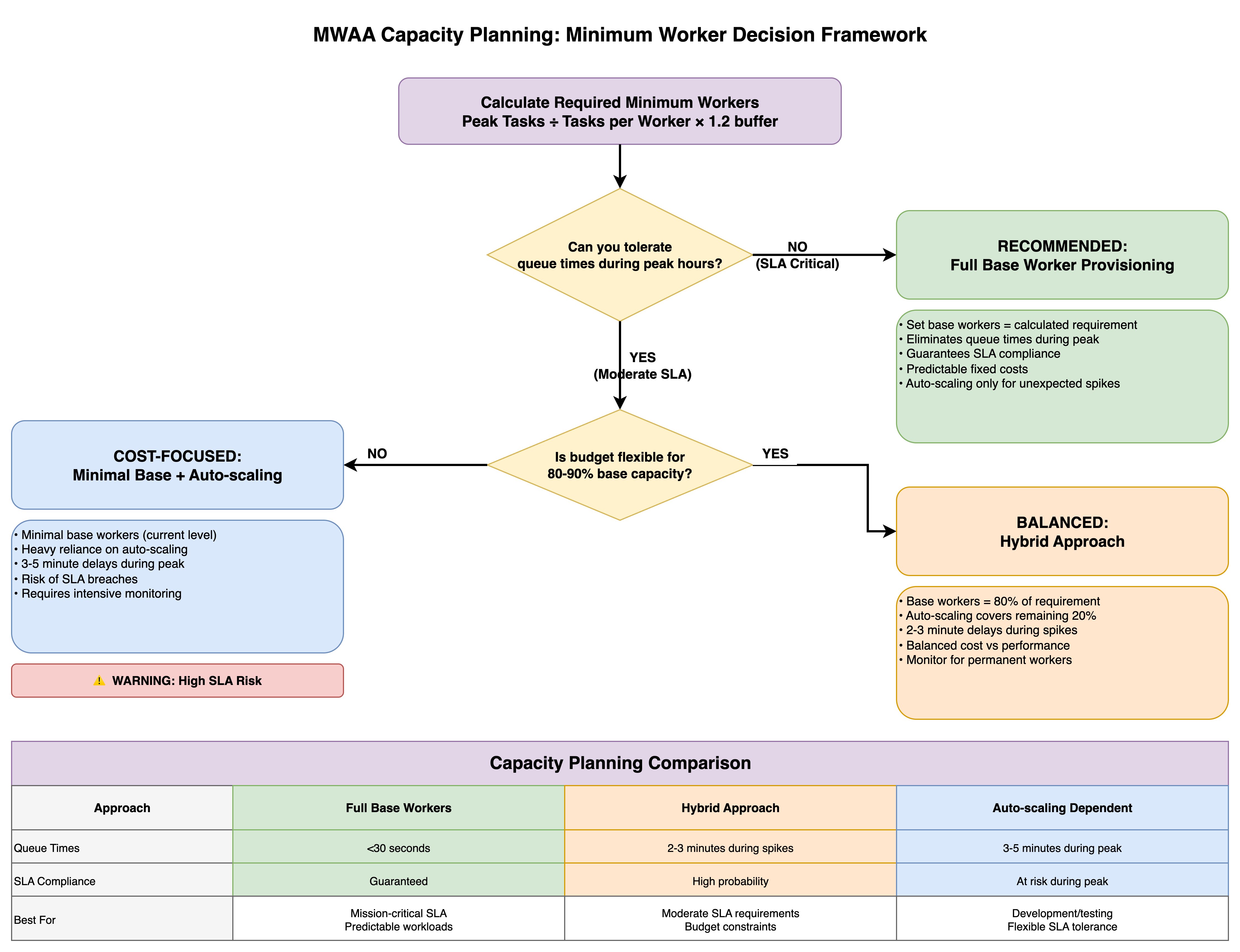
Resolution matrix
The framework presents three capability planning approaches, every optimized for various organizational priorities.
The Full Base Employee Provisioning technique (the conservative path) units base staff equal to the calculated requirement, eliminating queue occasions throughout peak intervals and guaranteeing SLA compliance with predictable mounted prices, whereas automated scaling handles solely sudden spikes—superb for mission-critical workloads with strict SLA necessities.
The Minimal Base + Computerized Scaling strategy (the cost-focused path) maintains minimal base staff at present ranges and depends closely on automated scaling, accepting 3-5 minute delays throughout peak intervals and SLA breach dangers in change for decrease baseline prices, although this requires intensive monitoring and carries specific warnings about excessive SLA danger.
The Hybrid Strategy (the balanced path) provisions base staff at 80% of the calculated requirement with automated scaling masking the remaining 20%, leading to 2-3 minute delays throughout spikes whereas balancing value in opposition to efficiency—appropriate for reasonable SLA necessities with some funds constraints.
The comparability desk contrasts queue occasions (below 30 seconds versus 2-3 minutes versus 3-5 minutes), SLA compliance ranges (assured versus excessive likelihood versus at-risk throughout peak), and superb use instances (mission-critical predictable workloads versus reasonable SLA necessities with funds constraints versus improvement environments with versatile SLA tolerance), enabling groups to make knowledgeable provisioning selections aligned with their operational necessities and monetary constraints.
Key takeaway
Efficient capability planning prevents each under-provisioning (SLA breaches) and over-provisioning (value overruns).
Capability planning ideas
- Calculate capability wants BEFORE including workload – Use peak activity projections with 5-15% security buffer
- Dimension minimal staff for peak demand – Don’t depend on automated scaling for predictable hundreds
- Use automated scaling just for sudden spikes – Deal with as security web, not main capability
- Goal 85-95% utilization throughout peak hours – Ensures headroom for sudden progress
- Plan 5-15% headroom for sudden progress – Manufacturing typically differs from testing
- Monitor AdditionalWorkers metric – If energetic >6 hours day by day, improve base staff
- Evaluate quarterly + trigger-based assessments – Common critiques plus fast motion on points
- Stability value and efficiency primarily based on SLA criticality – Enterprise influence justifies infrastructure funding
Success metrics
- Queue effectivity: Common queue time <30 seconds throughout peak
- SLA compliance: >99.5% of important duties full on time
- Useful resource utilization: 85-95% throughout peak hours (optimum effectivity)
- Price predictability: <10% variance in month-to-month employee prices
Conclusion
Capability planning is just not a one-time train. It’s an ongoing self-discipline. The framework we’ve outlined provides you a repeatable course of: measure your present peak utilization by means of CloudWatch metrics, mission progress primarily based on incoming workloads, calculate the required staff with an applicable security buffer, and monitor repeatedly to catch drift earlier than it turns into an outage.
The monetary providers situation on this put up illustrates a standard actuality: working at 100% utilization throughout peak hours leaves zero room for the sudden. By sizing to 95% peak utilization with a modest buffer, the workforce gained the headroom wanted to soak up volatility with out risking their 7 AM market-open SLA.
Whether or not you select full base employee provisioning for mission-critical pipelines, a hybrid strategy for reasonable SLA necessities, or lean on automated scaling for improvement workloads, the precise technique relies on your online business context, not a one-size-fits-all rule. Pair your capability plan with the CloudWatch alarms and assessment triggers we coated, and also you’ll catch capability gaps early.
Mixed with the optimization-first strategy from Half 1, you now have an entire toolkit: diagnose earlier than you scale, optimize earlier than you provision, and plan earlier than you deploy. Your MWAA surroundings and your on-call engineers will thanks.
To get began, go to the Amazon MWAA product web page and the Amazon MWAA console web page.
If in case you have questions or wish to share your MWAA capability planning, go away a remark.