

{kind=link}
Matter modeling uncovers hidden themes in massive doc collections. Conventional strategies like Latent Dirichlet Allocation depend on phrase frequency and deal with textual content as baggage of phrases, usually lacking deeper context and which means.
BERTopic takes a distinct route, combining transformer embeddings, clustering, and c-TF-IDF to seize semantic relationships between paperwork. It produces extra significant, context-aware matters suited to real-world knowledge. On this article, we break down how BERTopic works and how one can apply it step-by-step.
What’s BERTopic?
BERTopic is a modular matter modeling framework that treats matter discovery as a pipeline of unbiased however related steps. It integrates deep studying and classical pure language processing methods to provide coherent and interpretable matters.
The core concept is to remodel paperwork into semantic embeddings, cluster them based mostly on similarity, after which extract consultant phrases for every cluster. This strategy permits BERTopic to seize each which means and construction inside textual content knowledge.
At a excessive degree, BERTopic follows this course of:

Every element of this pipeline may be modified or changed, making BERTopic extremely versatile for various purposes.
Key Elements of the BERTopic Pipeline
1. Preprocessing
Step one entails getting ready uncooked textual content knowledge. Not like conventional NLP pipelines, BERTopic doesn’t require heavy preprocessing. Minimal cleansing, corresponding to lowercasing, eradicating additional areas, and filtering very quick paperwork is normally enough.
2. Doc Embeddings
Every doc is transformed right into a dense vector utilizing transformer-based fashions corresponding to SentenceTransformers. This enables the mannequin to seize semantic relationships between paperwork.
Mathematically:
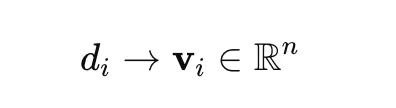
The place di is a doc and vi is its vector illustration.
3. Dimensionality Discount
Excessive-dimensional embeddings are troublesome to cluster successfully. BERTopic makes use of UMAP to cut back the dimensionality whereas preserving the construction of the information.
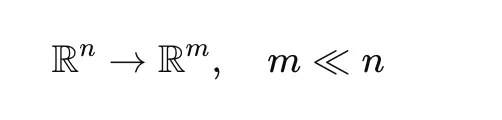
This step improves clustering efficiency and computational effectivity.
4. Clustering
After dimensionality discount, clustering is carried out utilizing HDBSCAN. This algorithm teams comparable paperwork into clusters and identifies outliers.
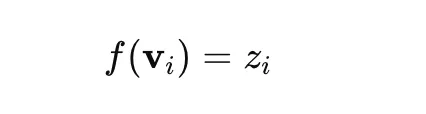
The place zi is the assigned matter label. Paperwork labeled as −1 are thought of outliers.
5. c-TF-IDF Matter Illustration
As soon as clusters are fashioned, BERTopic generates matter representations utilizing c-TF-IDF.
Time period Frequency:
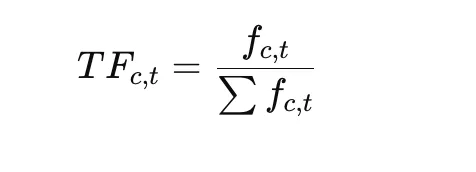
Inverse Class Frequency:
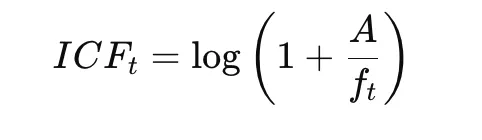
Remaining c-TF-IDF:
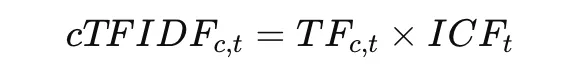
This technique highlights phrases which might be distinctive inside a cluster whereas decreasing the significance of frequent phrases throughout clusters.
Arms-On Implementation
This part demonstrates a easy implementation of BERTopic utilizing a really small dataset. The aim right here is to not construct a production-scale matter mannequin, however to grasp how BERTopic works step-by-step. On this instance, we preprocess the textual content, configure UMAP and HDBSCAN, prepare the BERTopic mannequin, and examine the generated matters.
Step 1: Import Libraries and Put together the Dataset
import re
import umap
import hdbscan
from bertopic import BERTopic
docs = [
"NASA launched a satellite",
"Philosophy and religion are related",
"Space exploration is growing"
] On this first step, the required libraries are imported. The re module is used for primary textual content preprocessing, whereas umap and hdbscan are used for dimensionality discount and clustering. BERTopic is the primary library that mixes these parts into a subject modeling pipeline.
A small record of pattern paperwork can be created. These paperwork belong to totally different themes, corresponding to house and philosophy, which makes them helpful for demonstrating how BERTopic makes an attempt to separate textual content into totally different matters.
Step 2: Preprocess the Textual content
def preprocess(textual content):
textual content = textual content.decrease()
textual content = re.sub(r"s+", " ", textual content)
return textual content.strip()
docs = [preprocess(doc) for doc in docs]This step performs primary textual content cleansing. Every doc is transformed to lowercase in order that phrases like “NASA” and “nasa” are handled as the identical token. Further areas are additionally eliminated to standardize the formatting.
Preprocessing is essential as a result of it reduces noise within the enter. Though BERTopic makes use of transformer embeddings which might be much less depending on heavy textual content cleansing, easy normalization nonetheless improves consistency and makes the enter cleaner for downstream processing.
Step 3: Configure UMAP
umap_model = umap.UMAP(
n_neighbors=2,
n_components=2,
min_dist=0.0,
metric="cosine",
random_state=42,
init="random"
)UMAP is used right here to cut back the dimensionality of the doc embeddings earlier than clustering. Since embeddings are normally high-dimensional, clustering them instantly is commonly troublesome. UMAP helps by projecting them right into a lower-dimensional house whereas preserving their semantic relationships.
The parameter init=”random” is very essential on this instance as a result of the dataset is extraordinarily small. With solely three paperwork, UMAP’s default spectral initialization could fail, so random initialization is used to keep away from that error. The settings n_neighbors=2 and n_components=2 are chosen to go well with this tiny dataset.
Step 4: Configure HDBSCAN
hdbscan_model = hdbscan.HDBSCAN(
min_cluster_size=2,
metric="euclidean",
cluster_selection_method="eom",
prediction_data=True
)HDBSCAN is the clustering algorithm utilized by BERTopic. Its function is to group comparable paperwork collectively after dimensionality discount. Not like strategies corresponding to Okay-Means, HDBSCAN doesn’t require the variety of clusters to be specified prematurely.
Right here, min_cluster_size=2 implies that at the very least two paperwork are wanted to type a cluster. That is applicable for such a small instance. The prediction_data=True argument permits the mannequin to retain data helpful for later inference and likelihood estimation.
Step 5: Create the BERTopic Mannequin
topic_model = BERTopic(
umap_model=umap_model,
hdbscan_model=hdbscan_model,
calculate_probabilities=True,
verbose=True
) On this step, the BERTopic mannequin is created by passing the customized UMAP and HDBSCAN configurations. This exhibits considered one of BERTopic’s strengths: it’s modular, so particular person parts may be personalized in accordance with the dataset and use case.
The choice calculate_probabilities=True allows the mannequin to estimate matter possibilities for every doc. The verbose=True choice is beneficial throughout experimentation as a result of it shows progress and inner processing steps whereas the mannequin is operating.
Step 6: Match the BERTopic Mannequin
matters, probs = topic_model.fit_transform(docs) That is the primary coaching step. BERTopic now performs the entire pipeline internally:
- It converts paperwork into embeddings
- It reduces the embedding dimensions utilizing UMAP
- It clusters the lowered embeddings utilizing HDBSCAN
- It extracts matter phrases utilizing c-TF-IDF
The result’s saved in two outputs:
- matters, which comprises the assigned matter label for every doc
- probs, which comprises the likelihood distribution or confidence values for the assignments
That is the purpose the place the uncooked paperwork are reworked into topic-based construction.
Step 7: View Matter Assignments and Matter Info
print("Matters:", matters)
print(topic_model.get_topic_info())
for topic_id in sorted(set(matters)):
if topic_id != -1:
print(f"nTopic {topic_id}:")
print(topic_model.get_topic(topic_id))
This remaining step is used to examine the mannequin’s output.
print("Matters:", matters)exhibits the subject label assigned to every doc.get_topic_info()shows a abstract desk of all matters, together with matter IDs and the variety of paperwork in every matter.get_topic(topic_id)returns the highest consultant phrases for a given matter.
The situation if topic_id != -1 excludes outliers. In BERTopic, a subject label of -1 implies that the doc was not confidently assigned to any cluster. This can be a regular habits in density-based clustering and helps keep away from forcing unrelated paperwork into incorrect matters.
Benefits of BERTopic
Listed below are the primary benefits of utilizing BERTopic:
- Captures semantic which means utilizing embeddings
BERTopic makes use of transformer-based embeddings to grasp the context of textual content relatively than simply phrase frequency. This enables it to group paperwork with comparable meanings even when they use totally different phrases. - Mechanically determines variety of matters
Utilizing HDBSCAN, BERTopic doesn’t require a predefined variety of matters. It discovers the pure construction of the information, making it appropriate for unknown or evolving datasets. - Handles noise and outliers successfully
Paperwork that don’t clearly belong to any cluster are labeled as outliers as a substitute of being pressured into incorrect matters. This improves the general high quality and readability of the matters. - Produces interpretable matter representations
With c-TF-IDF, BERTopic extracts key phrases that clearly signify every matter. These phrases are distinctive and simple to grasp, making interpretation simple. - Extremely modular and customizable
Every a part of the pipeline may be adjusted or changed, corresponding to embeddings, clustering, or vectorization. This flexibility permits it to adapt to totally different datasets and use instances.
Conclusion
BERTopic represents a major development in matter modeling by combining semantic embeddings, dimensionality discount, clustering, and class-based TF-IDF. This hybrid strategy permits it to provide significant and interpretable matters that align extra carefully with human understanding.
Somewhat than relying solely on phrase frequency, BERTopic leverages the construction of semantic house to establish patterns in textual content knowledge. Its modular design additionally makes it adaptable to a variety of purposes, from analyzing buyer suggestions to organizing analysis paperwork.
In apply, the effectiveness of BERTopic depends upon cautious collection of embeddings, tuning of clustering parameters, and considerate analysis of outcomes. When utilized appropriately, it offers a robust and sensible resolution for contemporary matter modeling duties.
Incessantly Requested Questions
A. It makes use of semantic embeddings as a substitute of phrase frequency, permitting it to seize context and which means extra successfully.
A. It makes use of HDBSCAN clustering, which robotically discovers the pure variety of matters with out predefined enter.
A. It’s computationally costly attributable to embedding era, particularly for giant datasets.
Hello, I’m Janvi, a passionate knowledge science fanatic presently working at Analytics Vidhya. My journey into the world of knowledge started with a deep curiosity about how we will extract significant insights from complicated datasets.
Login to proceed studying and luxuriate in expert-curated content material.