

{kind=link}
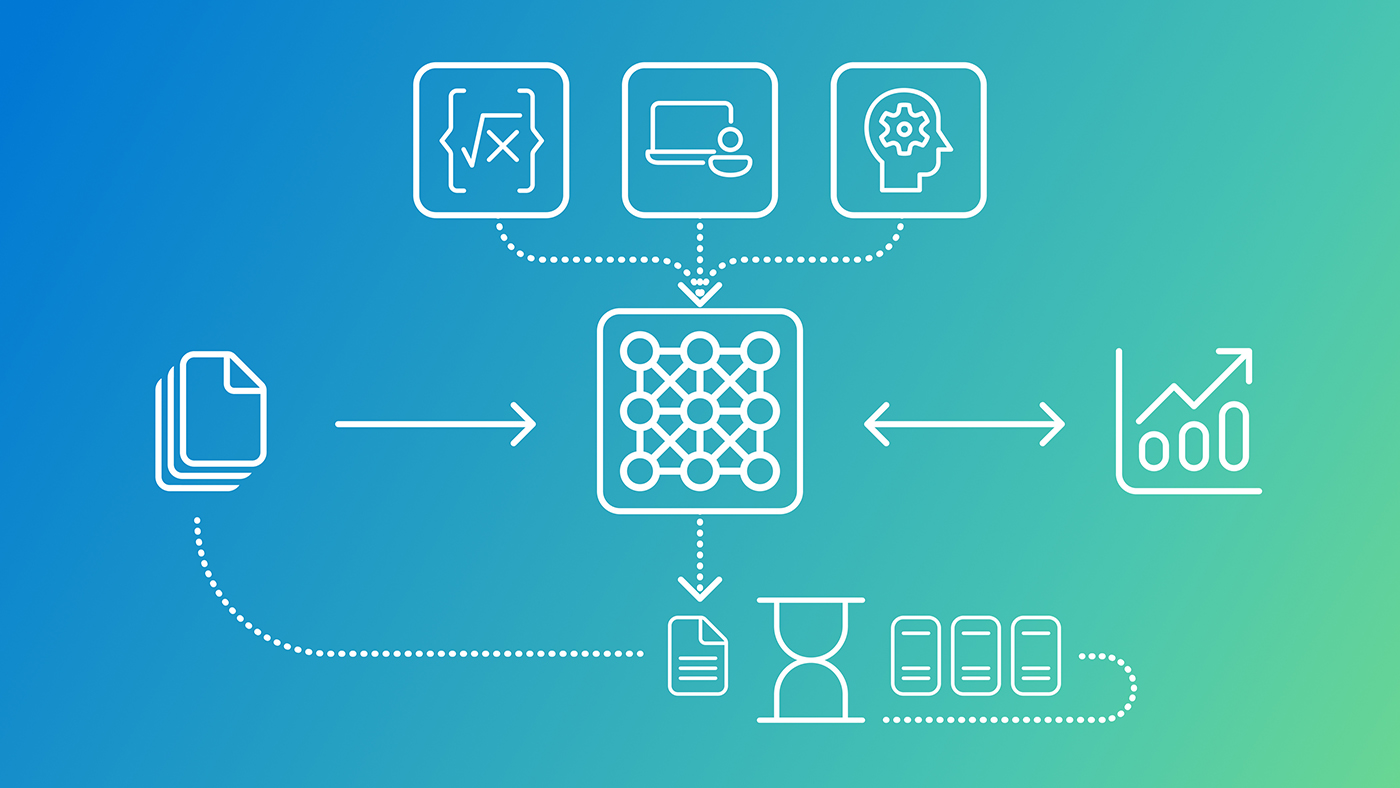
At a look
- Phi-4-reasoning-vision-15B is a compact and good open‑weight multimodal reasoning mannequin that balances reasoning energy, effectivity, and coaching information wants. It’s a broadly succesful mannequin that permits for pure interplay for a wide selection of vision-language duties and excels at math and science reasoning and understanding user-interfaces.
- We share classes discovered and greatest practices for coaching a multimodal reasoning mannequin—displaying the good thing about cautious structure selections, rigorous information curation, and the advantages of utilizing a combination of reasoning and non-reasoning information.
We’re happy to announce Phi-4-reasoning-vision-15B, a 15 billion parameter open‑weight multimodal reasoning mannequin, out there by way of Microsoft Foundry (opens in new tab), HuggingFace (opens in new tab) and GitHub (opens in new tab). Phi-4-reasoning-vision-15B is a broadly succesful mannequin that can be utilized for a wide selection of vision-language duties akin to picture captioning, asking questions on pictures, studying paperwork and receipts, serving to with homework, inferring about modifications in sequences of pictures, and far more. Past these basic capabilities, it excels at math and science reasoning and at understanding and grounding components on laptop and cell screens. Specifically, our mannequin presents an interesting worth relative to fashionable open-weight fashions, pushing the pareto-frontier of the tradeoff between accuracy and compute prices. We now have aggressive efficiency to a lot slower fashions that require ten occasions or extra compute-time and tokens and higher accuracy than equally quick fashions, significantly in the case of math and science reasoning.
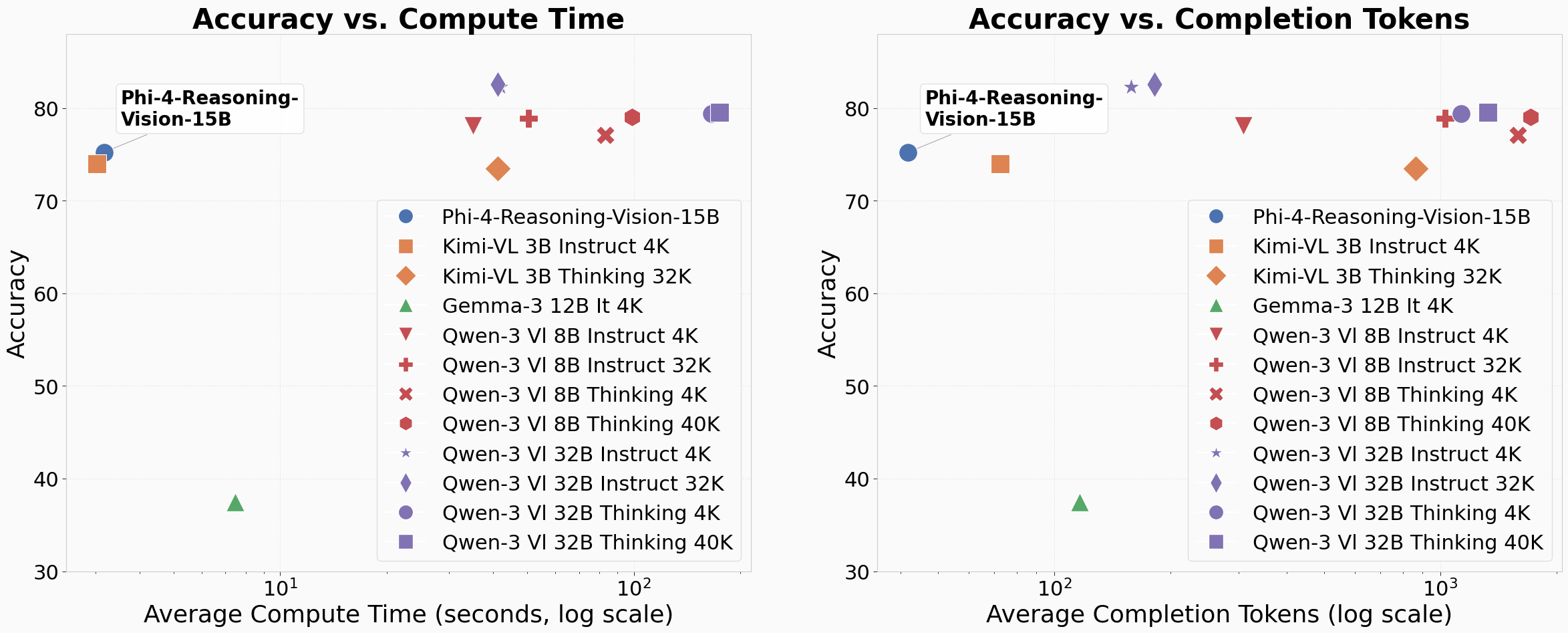
On this submit, we share the motivations, design selections, experiments, and learnings that knowledgeable its growth, in addition to an analysis of the mannequin’s efficiency and steering on find out how to use it. Our objective is to contribute sensible perception to the neighborhood on constructing smaller, environment friendly multimodal reasoning fashions and to share an open-weight mannequin that’s aggressive with fashions of comparable measurement at basic vision-language duties, excels at laptop use, and excels on scientific and mathematical multimodal reasoning.
A deal with smaller and sooner imaginative and prescient–language fashions
Many fashionable vision-language fashions (VLMs) have trended in direction of rising in parameter rely and, specifically, the variety of tokens they eat and generate. This results in enhance in coaching and inference-time price and latency, and impedes their usability for downstream deployment, particularly in useful resource‑constrained or interactive settings.
A rising countertrend in direction of smaller (opens in new tab) fashions goals to spice up effectivity, enabled by cautious mannequin design and information curation – a objective pioneered by the Phi household of fashions (opens in new tab) and furthered by Phi-4-reasoning-vision-15B. We particularly construct on learnings from the Phi-4 and Phi-4-Reasoning language fashions and present how a multimodal mannequin might be educated to cowl a variety of imaginative and prescient and language duties with out counting on extraordinarily massive coaching datasets, architectures, or extreme inference‑time token era. Our mannequin is meant to be light-weight sufficient to run on modest {hardware} whereas remaining able to structured reasoning when it’s useful. Our mannequin was educated with far much less compute than many latest open-weight VLMs of comparable measurement. We used simply 200 billion tokens of multimodal information leveraging Phi-4-reasoning (educated with 16 billion tokens) primarily based on a core mannequin Phi-4 (400 billion distinctive tokens), in comparison with greater than 1 trillion tokens used for coaching multimodal fashions like Qwen 2.5 VL (opens in new tab) and 3 VL (opens in new tab), Kimi-VL (opens in new tab), and Gemma3 (opens in new tab). We will subsequently current a compelling choice in comparison with present fashions pushing the pareto-frontier of the tradeoff between accuracy and compute prices.
Classes from coaching a multimodal mannequin
Coaching a multimodal reasoning mannequin raises quite a few questions and requires many nuanced design selections round mannequin structure, dataset high quality and composition, and the interplay between reasoning‑heavy and non-reasoning notion‑centered duties.
Mannequin structure: Early- vs mid-fusion
Mannequin architectures for VLMs differ primarily in how visible and textual info is fused. Mid-fusion fashions use a pretrained imaginative and prescient encoder to transform pictures into visible tokens which might be projected right into a pretrained LLM’s embedding house, enabling cross-modal reasoning whereas leveraging elements already educated on trillions of tokens. Early-fusion fashions course of picture patches and textual content tokens in a single mannequin transformer, yielding richer joint representations however at considerably increased compute, reminiscence, and information price. We adopted a mid-fusion structure because it gives a sensible trade-off for constructing a performant mannequin with modest assets.
Mannequin structure: Imaginative and prescient encoder and picture processing
We construct on the SigLIP-2 (opens in new tab) imaginative and prescient encoder and the Phi-4-Reasoning spine. In earlier analysis, we discovered that multimodal language fashions typically struggled to resolve duties, not due to an absence of reasoning proficiency, however quite an incapability to extract and choose related perceptual info from the picture. An instance could be a high-resolution screenshot that’s information-dense with comparatively small interactive components.
A number of open-source multimodal language fashions have tailored their methodologies accordingly, e.g., Gemma3 (opens in new tab) makes use of pan-and-scan and NVILA (opens in new tab) makes use of Dynamic S2. Nevertheless, their trade-offs are obscure throughout totally different datasets and hyperparameters. To this finish, we performed an ablation examine of a number of strategies. We educated a smaller 5 billion parameter Phi-4 primarily based proxy mannequin on a dataset of 10 million image-text pairs, primarily composed of computer-use and GUI grounding information. We in contrast with Dynamic S2, which resizes pictures to an oblong decision that minimizes distortion whereas admitting a tiling by 384×384 squares; Multi-crop, which splits the picture into doubtlessly overlapping 384×384 squares and concatenates their encoded options on the token dimension; Multi-crop with S2, which broadens the receptive subject by cropping into 1536×1536 squares earlier than making use of S2; and Dynamic decision utilizing the Naflex variant of SigLIP-2, a natively dynamic-resolution encoder with adjustable patch counts.
Our main discovering is that dynamic decision imaginative and prescient encoders carry out the perfect and particularly properly on high-resolution information. It’s significantly attention-grabbing to match dynamic decision with 2048 vs 3600 most tokens: the latter roughly corresponds to native HD 720p decision and enjoys a considerable enhance on high-resolution benchmarks, significantly ScreenSpot-Professional. Reinforcing the high-resolution pattern, we discover that multi-crop with S2 outperforms commonplace multi-crop regardless of utilizing fewer visible tokens (i.e., fewer crops general). The dynamic decision method produces essentially the most tokens on common; as a consequence of their tiling subroutine, S2-based strategies are constrained by the unique picture decision and sometimes solely use about half the utmost tokens. From these experiments we select the SigLIP-2 Naflex variant as our imaginative and prescient encoder.
| Methodology | Max Tokens | MathVista | ScreenSpot | ScreenSpot-Professional | V*Bench |
|---|---|---|---|---|---|
| Dynamic-S2 | 3096 | 42.9 | 78.4 | 9.4 | 52.9 |
| Multi-crop | 3096 | 43.4 | 67.8 | 5.4 | 51.8 |
| Multi-crop with S2 | 2048 | 43.4 | 79.1 | 10.6 | 57.1 |
| Dynamic decision | 2048 | 45.2 | 81.5 | 9.2 | 51.3 |
| Dynamic decision | 3600 | 44.9 | 79.7 | 17.5 | 56.0 |
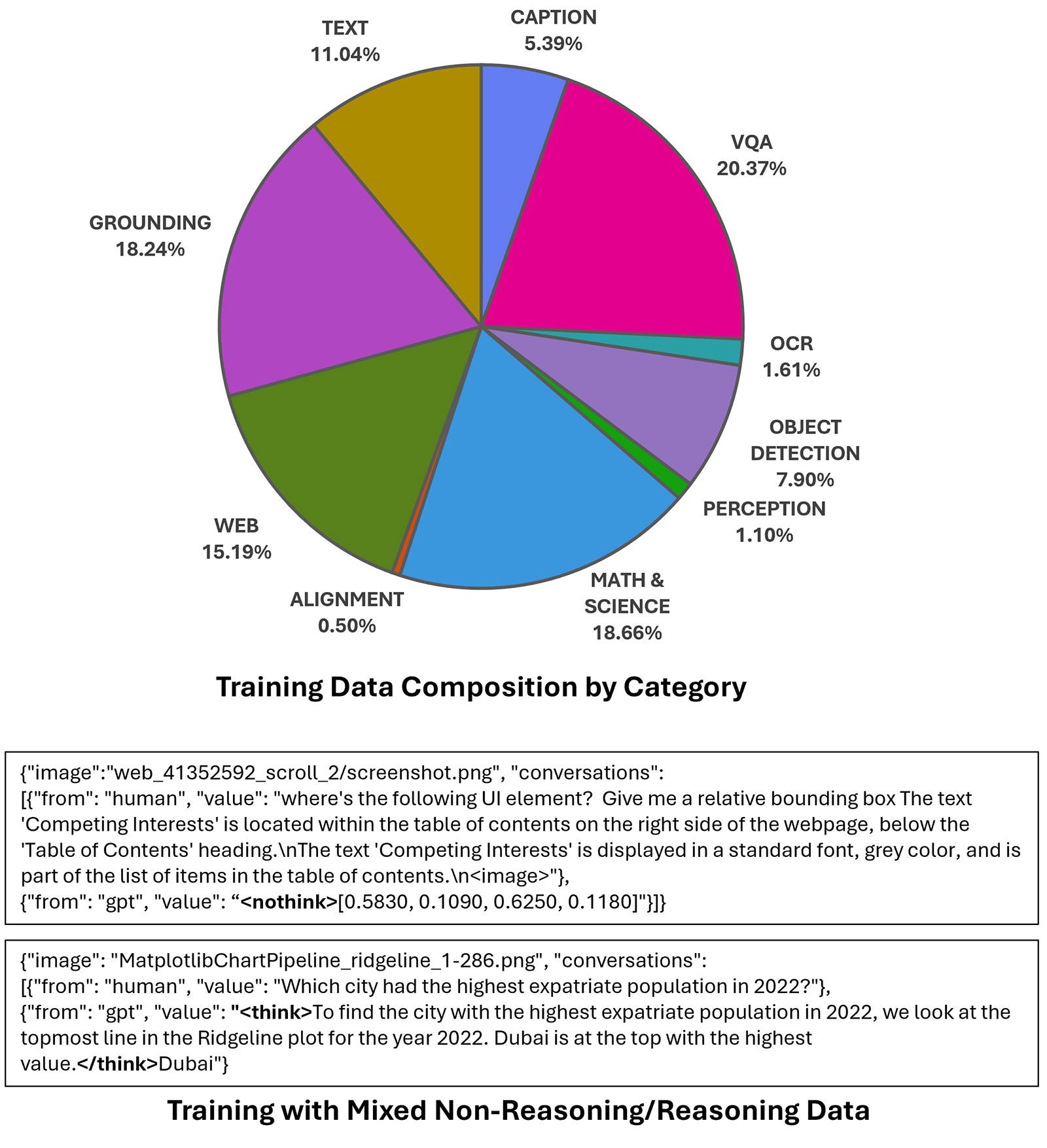
Knowledge: High quality and composition
As with its language spine Phi-4-Reasoning, Phi-4-reasoning-vision-15B was educated with a deliberate deal with information high quality. Our last dataset consists primarily of knowledge from three sources: open-source datasets which had been meticulously filtered and improved; high-quality domain-specific inside information; and high-quality information from focused acquisitions. The overwhelming majority of our information lies within the first class: information which originated as open-source information, which had been considerably filtered and improved, whether or not by eradicating low-quality datasets or data, programmatically fixing errors in information formatting, or utilizing open-source pictures as seeds to synthetically generate higher-quality accompanying textual content.
The method of enhancing open-source information started by manually reviewing samples from every dataset. Usually, 5 to 10 minutes had been ample to categorise information as excellent-quality, good questions with flawed solutions, low-quality questions or pictures, or high-quality with formatting errors. Wonderful information was stored largely unchanged. For information with incorrect solutions or poor-quality captions, we re-generated responses utilizing GPT-4o and o4-mini, excluding datasets the place error charges remained too excessive. Low-quality questions proved tough to salvage, however when the pictures themselves had been top quality, we repurposed them as seeds for brand new caption or visible query answering (VQA) information. Datasets with essentially flawed pictures had been excluded completely. We additionally fastened a surprisingly massive variety of formatting and logical errors throughout broadly used open-source datasets.
We extracted further worth from present datasets by way of reformatting, diversification, and utilizing pictures as seeds for brand new information era. We generated detailed picture descriptions alongside authentic QA pairs for math and science information, had information carry out “double-duty” by embedding instruction-following necessities immediately into domain-specific QA, created “scrambled,” “caption-matching,” and “what’s modified?” data to enhance multi-image reasoning and sequential navigation for CUA eventualities, and diversifying immediate kinds to encourage robustness past completely structured questions.
To complement the improved open-source information, we make the most of high-quality inside datasets, a number of math-specific datasets which had been acquired throughout coaching of the Phi-4 language mannequin, and likewise some domain-specific curated information; for instance, latex-OCR information generated by processing and rendering equations from arXiv paperwork.
 earlier than returning a bounding field coordinates for a UI grounding activity, and the opposite makes use of a
earlier than returning a bounding field coordinates for a UI grounding activity, and the opposite makes use of a 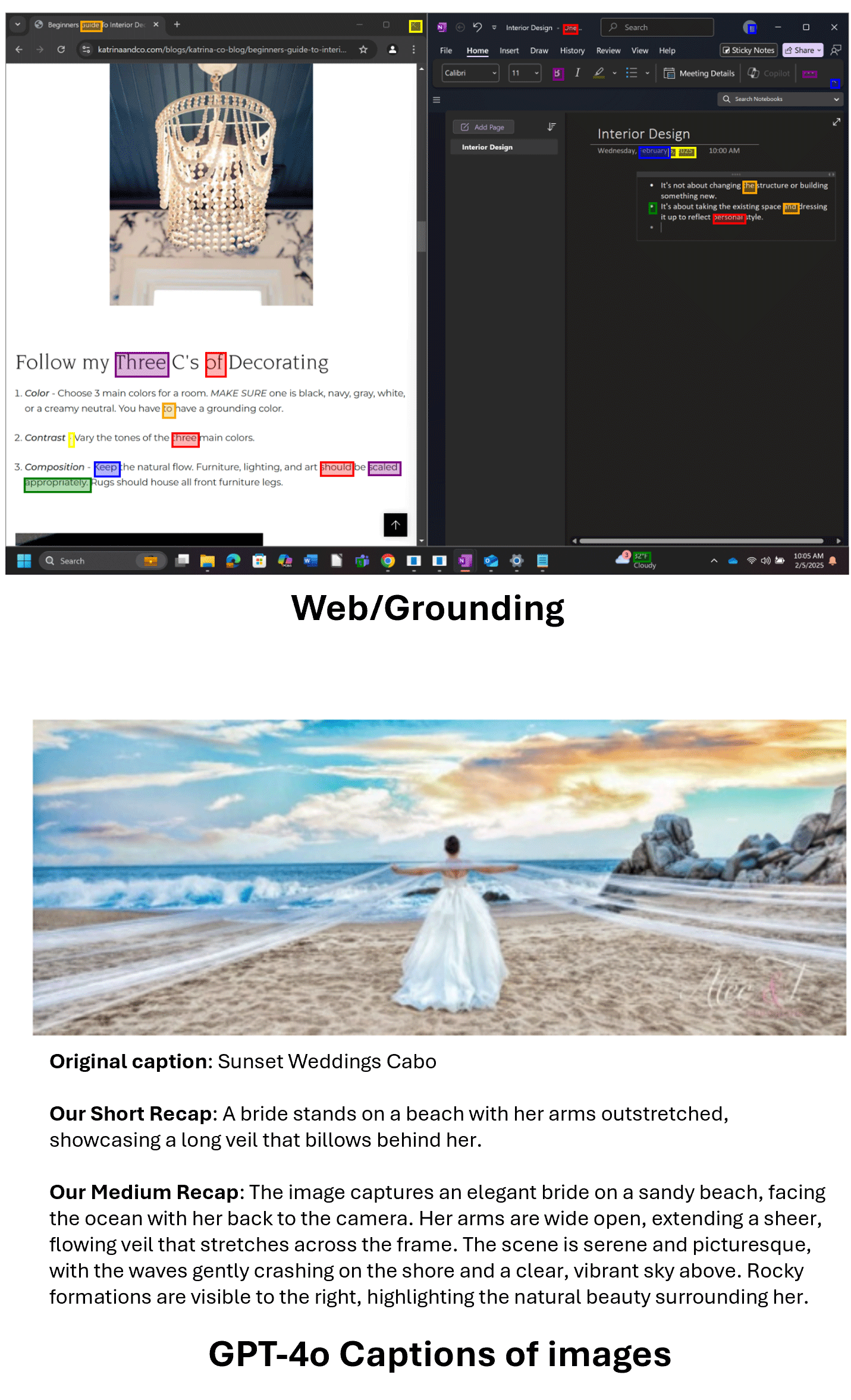
Knowledge: Arithmetic vs. computer-use information proportion
One in every of our objectives was to coach a mannequin that performs properly throughout basic vision-language duties, whereas excelling at mathematical and scientific reasoning and computer-use eventualities. How you can construction datasets for generalizable reasoning stays an open query—significantly as a result of the connection between information scale and reasoning efficiency can result in starkly totally different design choices, akin to coaching a single mannequin on a big dataset versus a number of specialised fashions with focused post-training.
Analysis on long-tailed classification robustness has recommended that balancing or eradicating information from overrepresented duties or subgroups (opens in new tab) is an efficient technique for guaranteeing good efficiency. However, these insights should not absolutely utilized or explored in the case of coaching VLMs, which at occasions have favored scale over cautious information balancing. To realize our objectives, we performed a set of experiments to research a variety of knowledge ratios between our focus domains.
Utilizing the identical 5 billion parameter proxy mannequin as for earlier experiments, we educated whereas various the quantity of arithmetic and science vs. computer-use information for every run. Every dataset included the identical subset of 1 million basic image-text pairs as a baseline. For arithmetic and science information, we used a subsample of 150,000 data, optionally duplicating each as much as 3 times. Subsequent, we included as much as 450,000 computer-use data, and optionally a further 400,000 from Phi-Floor.
We discovered that that multimodal arithmetic and science efficiency weren’t harmed by further computer-use information, and vice versa. Curiously, we discovered that rising arithmetic information by 3x whereas retaining computer-use information fixed improved math, science, and computer-use benchmarks.
| Normal | Math and Science | CUA | Whole | MMMU | MathVista | ScreenSpot-V2 |
|---|---|---|---|---|---|---|
| 1M | 150K | 450K | 1.6M | 44.0 | 37.4 | 48.2 |
| 1M | 150K | 850K | 2.0M | 44.1 | 37.3 | 60.0 |
| 1M | 450K | 450K | 1.9M | 45.3 | 36.0 | 48.3 |
| 1M | 450K | 850K | 2.3M | 43.4 | 38.9 | 63.1 |
| 1M | 150K | 150K | 1.3M | 44.2 | 36.9 | 29.8 |
| 1M | 150K | 250K | 1.4M | 45.4 | 37.4 | 37.7 |
Knowledge: Artificial information for text-rich visible reasoning
Latest work (opens in new tab) means that focused artificial information can materially enhance multimodal reasoning, significantly for text-rich visible domains akin to charts, paperwork, diagrams, and rendered arithmetic. Utilizing pictures, questions, and solutions which might be programmatically generated and grounded within the visible construction permits exact management over visible content material and supervision high quality, leading to information that avoids many annotation errors, ambiguities, and distributional biases widespread in scraped datasets. This permits cleaner alignment between visible notion and multi-step inference, which has been proven to translate into measurable positive factors on reasoning-heavy benchmarks.
Artificial text-rich pictures develop protection of long-tail visible codecs which might be underrepresented in actual information however disproportionately influence reasoning accuracy, enhancing not solely visible grounding but in addition downstream reasoning by guaranteeing that failures are much less typically attributable to perceptual errors. We discovered that programmatically generated artificial information is a helpful augmentation to high-quality actual datasets — not a substitute, however a scalable mechanism for strengthening each notion and reasoning that enhances the coaching goals in compact multimodal fashions akin to Phi-4-reasoning-vision-15B.
Mixing non-reasoning and reasoning as a design goal
In language-only settings, reasoning traces have improved efficiency on many duties, however they require further compute which provides undesired latency. In multimodal settings, this tradeoff is much less clear-cut, for duties akin to picture captioning and optical character recognition (OCR), reasoning is usually pointless and might even be dangerous (opens in new tab), whereas mathematical and scientific problem-solving profit from multi-step reasoning. Thus, the selection of when to cause or not might be fairly nuanced.
Coaching approaches for multimodal reasoning fashions
Language-only reasoning fashions are usually created by way of supervised fine-tuning (SFT) or reinforcement studying (RL): SFT is less complicated however requires massive quantities of pricy reasoning hint information, whereas RL reduces information necessities at the price of considerably elevated coaching complexity and compute. Multimodal reasoning fashions comply with an identical course of, however the design house is extra advanced. With a mid-fusion structure, the primary resolution is whether or not the bottom language mannequin is itself a reasoning or non-reasoning mannequin. This results in a number of attainable coaching pipelines:
- Non-reasoning LLM → reasoning multimodal coaching: Reasoning and multimodal capabilities are educated collectively.
- Non-reasoning LLM → non-reasoning multimodal → reasoning multimodal coaching: Multimodal capabilities are discovered first, then reasoning is added.
- Reasoning LLM → reasoning multimodal coaching: A reasoning base is used, however all multimodal information should embody reasoning traces.
- Our strategy: Reasoning LLM → blended non-reasoning / reasoning multimodal coaching. A reasoning-capable base is educated on a hybrid information combination, studying when to cause and when to reply immediately.
Approaches 1 and a couple of supply flexibility in designing multimodal reasoning habits from scratch utilizing broadly out there non-reasoning LLM checkpoints however place a heavy burden on multimodal coaching. Strategy 1 should educate visible understanding and reasoning concurrently and requires a considerable amount of multimodal reasoning information, whereas Strategy 2 might be educated with much less reasoning information however dangers catastrophic forgetting, as reasoning coaching could degrade beforehand discovered visible capabilities. Each threat weaker reasoning than ranging from a reasoning-capable base. Strategy 3 inherits sturdy reasoning foundations, however like Strategy 1, it requires reasoning traces for all coaching information and produces reasoning traces for all queries, even when not useful.
Our strategy: A blended reasoning and non-reasoning mannequin
Phi-4-reasoning-vision-15B adopts the 4th strategy listed beforehand, because it balances reasoning functionality, inference effectivity, and information necessities. It inherits a powerful reasoning basis however makes use of a hybrid strategy to mix the strengths of options whereas mitigating their drawbacks. Our mannequin defaults to direct inference for perception-focused domains the place reasoning provides latency with out enhancing accuracy, avoiding pointless verbosity and lowering inference prices, and it invokes longer reasoning paths for domains, akin to math and science, that profit from structured multi-step reasoning (opens in new tab).
Our mannequin is educated with SFT, the place reasoning samples embody “…” sections with chain-of-thought reasoning earlier than the ultimate reply, overlaying domains like math and science. Non-reasoning samples are tagged to begin with a “” token, signaling a direct response, and canopy perception-focused duties akin to captioning, grounding, OCR, and easy VQA. Reasoning information includes roughly 20% of the overall combine. Ranging from a reasoning-capable spine means this information grounds present reasoning in visible contexts quite than instructing it to cause from scratch.
This strategy shouldn’t be with out limitations. The stability between modes is a direct operate of design selections we made, knowledgeable by latest literature (opens in new tab) and noticed mannequin habits throughout coaching—although the boundary between modes might be imprecise as it’s discovered implicitly from the information distribution. Our mannequin permits management by way of specific prompting with “” or “” tokens when the person desires to override the default reasoning habits. The 20/80 reasoning-to-non-reasoning information cut up might not be optimum for all domains or deployment contexts. Evaluating the best stability of knowledge and the mannequin’s potential to change appropriately between modes stays an open drawback.
We view this blended strategy not as a definitive answer, however as one sensible and well-motivated level within the design house for balancing latency, accuracy, and adaptability in multimodal methods.
Functions
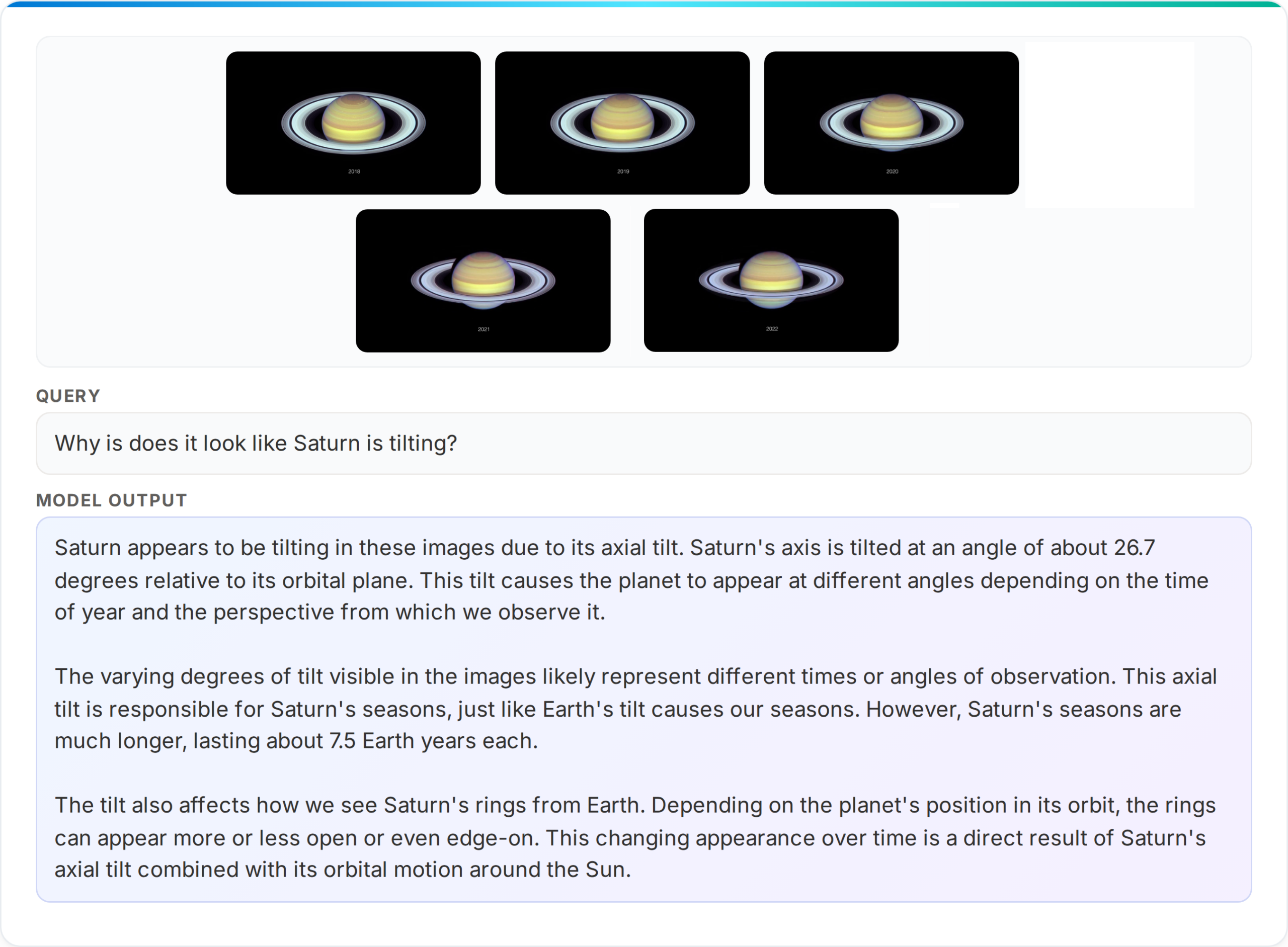
Phi-4-reasoning-vision-15B is a high-performing mannequin throughout many vision-language duties. It sees and understands the world by taking a look at a photograph, doc, chart, or display screen and making sense of it. In apply that covers an unlimited vary of purposes — only a few examples embody: describing pictures and answering questions on them, deciphering modifications and traits in pictures sequences, and recognizing objects, landmarks, and transcribing textual content.
Highlights: Scientific and mathematical reasoning and supporting computer-using brokers (CUA)
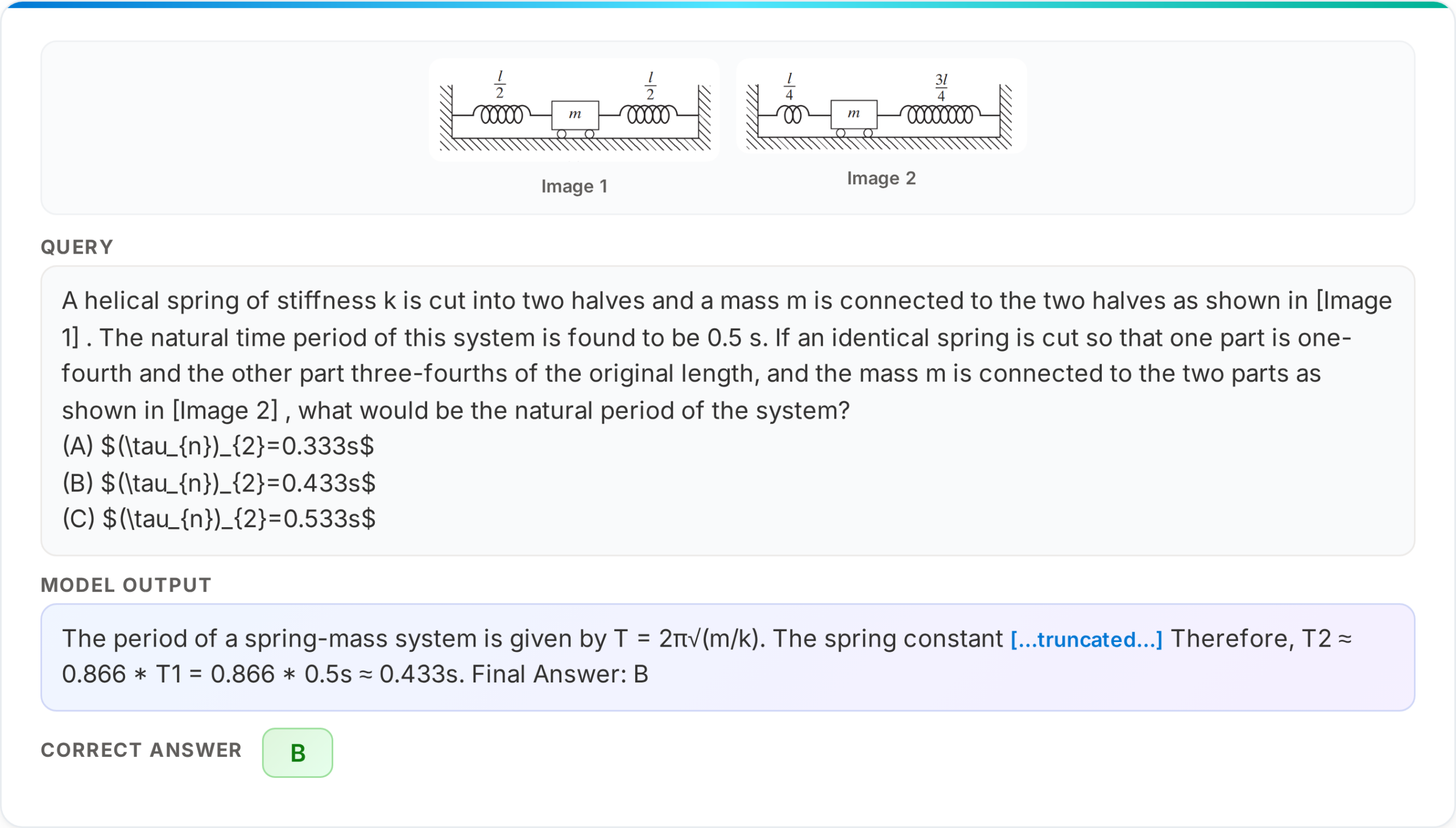
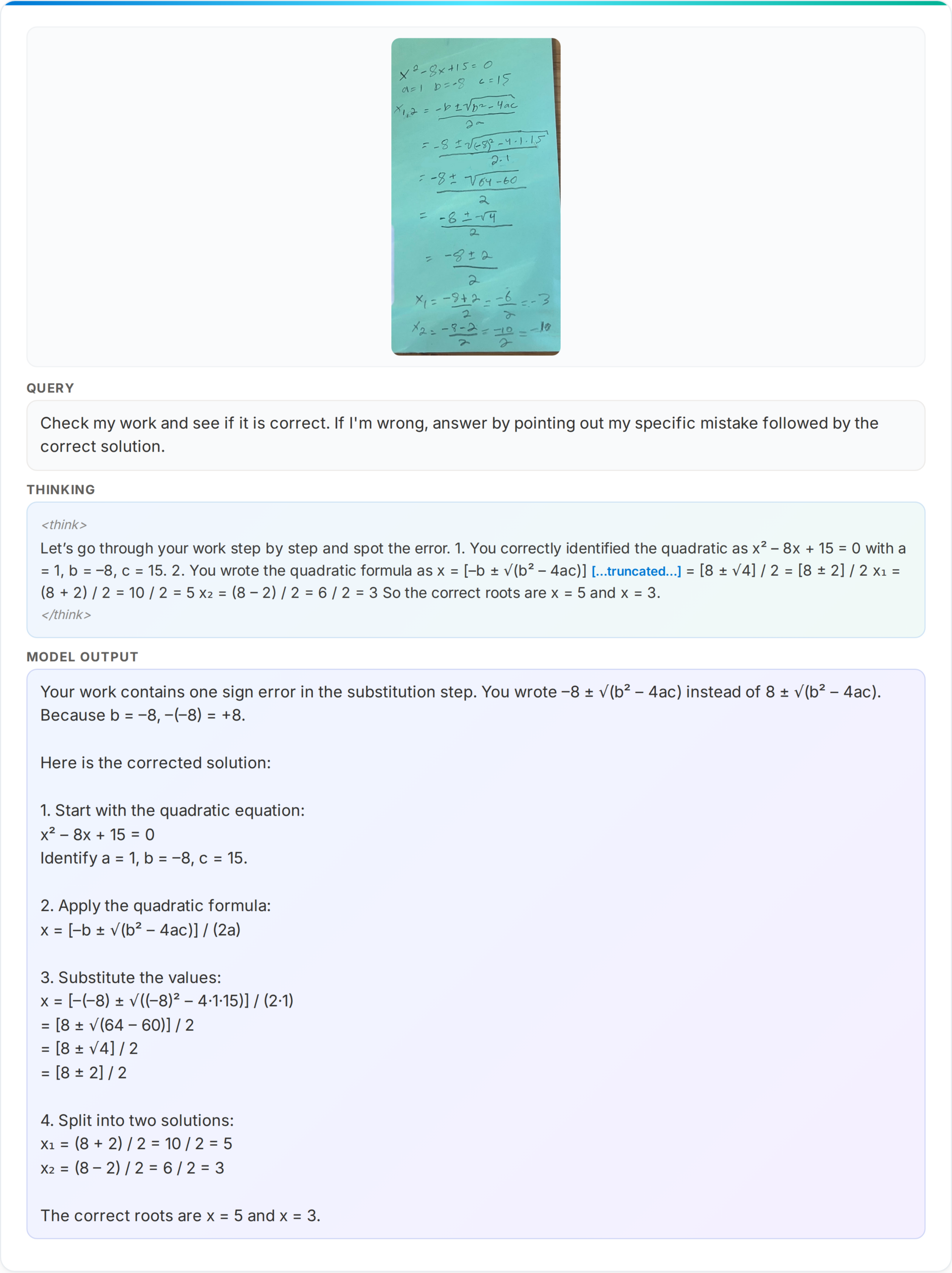
Along with basic imaginative and prescient and language duties, Phi-4-reasoning-vision-15B was designed to excel at duties that mix visible enter with structured inference, akin to fixing math issues offered in visible type, akin to handwritten or diagram-based questions, extracting and reasoning over quantitative info in paperwork and charts, and supporting multi-step reasoning in academic or scientific evaluation contexts.
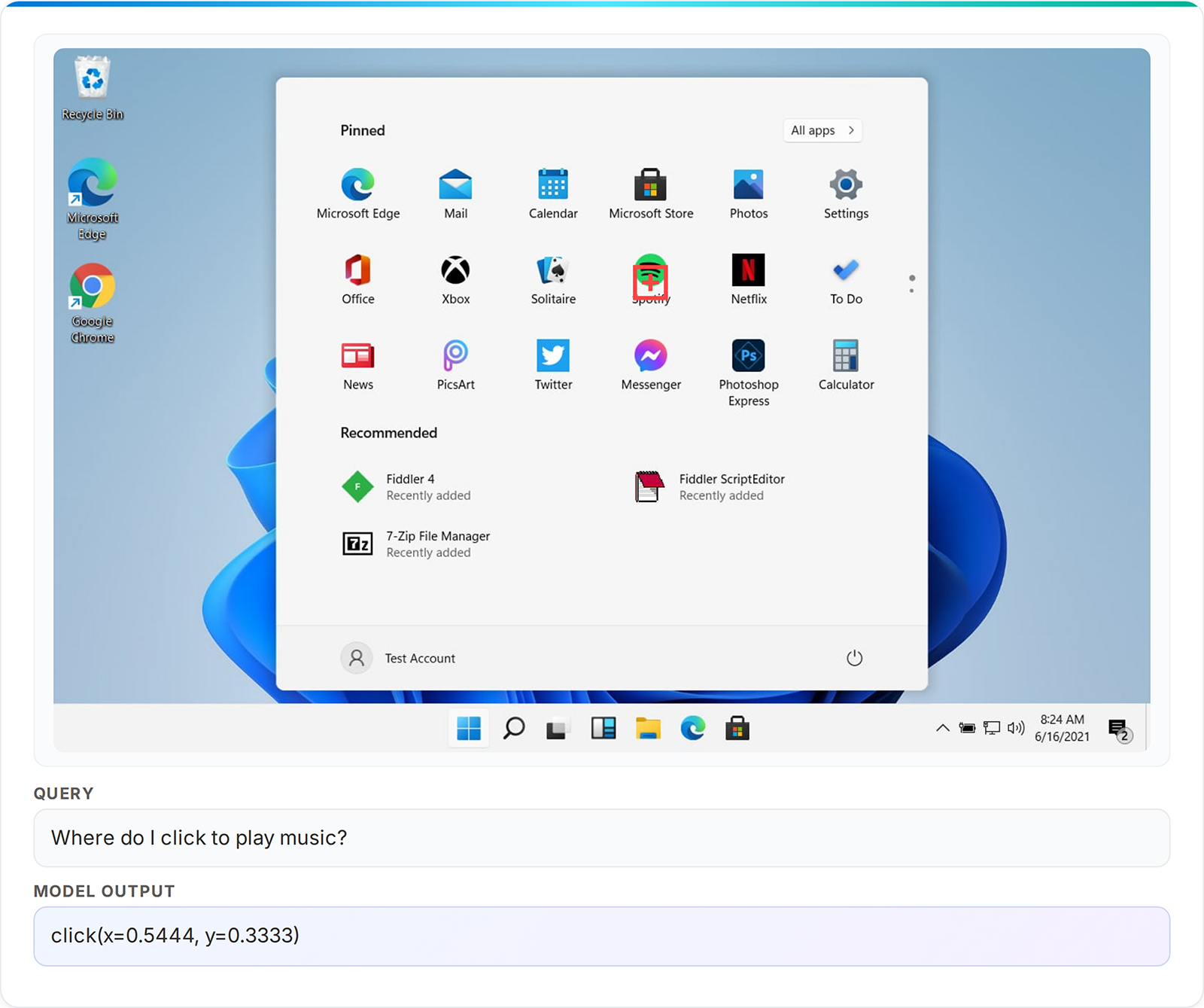
As well as, we educated Phi-4-reasoning-vision-15B to have expertise that may allow brokers to work together with graphical person interfaces by deciphering display screen content material and deciding on actions. With sturdy high-resolution notion and fine-grained grounding capabilities, Phi-4-reasoning-vision-15B is a compelling choice as a base-model for coaching agentic fashions akin to ones that navigate desktop, internet, and cell interfaces by figuring out and localizing interactive components akin to buttons, menus, and textual content fields. As a result of its low inference-time wants it’s nice for interactive environments the place low latency and compact mannequin measurement are important.
Analysis
Phi-4-reasoning-vision-15B was evaluated for accuracy and timing utilizing two complementary open-source frameworks to make sure each rigorous and standardized evaluation: Eureka ML Insights (opens in new tab) and VLMEvalKit (opens in new tab).
| Benchmark | Phi-4-reasoning-vision-15B | Phi-4-reasoning-vision-15B – drive nothink | Phi-4-mm-instruct | Kimi-VL-A3B-Instruct | gemma-3-12b-it | Qwen3-VL-8B-Instruct-4K | Qwen3-VL-8B-Instruct-32K | Qwen3-VL-32B-Instruct-4K | Qwen3-VL-32B-Instruct-32K |
|---|---|---|---|---|---|---|---|---|---|
| AI2D_TEST | 84.8 | 84.7 | 68.6 | 84.6 | 80.4 | 82.7 | 83 | 84.8 | 85 |
| ChartQA_TEST | 83.3 | 76.5 | 23.5 | 87 | 39 | 83.1 | 83.2 | 84.3 | 84 |
| HallusionBench | 64.4 | 63.1 | 56 | 65.2 | 65.3 | 73.5 | 74.1 | 74.4 | 74.9 |
| MathVerse_MINI | 44.9 | 43.8 | 32.4 | 41.7 | 29.8 | 54.5 | 57.4 | 64.2 | 64.2 |
| MathVision_MINI | 36.2 | 34.2 | 20 | 28.3 | 31.9 | 45.7 | 50 | 54.3 | 60.5 |
| MathVista_MINI | 75.2 | 68.7 | 50.5 | 67.1 | 57.4 | 77.1 | 76.4 | 82.5 | 81.8 |
| MMMU_VAL | 54.3 | 52 | 42.3 | 52 | 50 | 60.7 | 64.6 | 68.6 | 70.6 |
| MMStar | 64.5 | 63.3 | 45.9 | 60 | 59.4 | 68.9 | 69.9 | 73.7 | 74.3 |
| OCRBench | 76 | 75.6 | 62.6 | 86.5 | 75.3 | 89.2 | 90 | 88.5 | 88.5 |
| ScreenSpot_v2 | 88.2 | 88.3 | 28.5 | 89.8 | 3.5 | 91.5 | 91.5 | 93.7 | 93.9 |
| Benchmark | Phi-4-reasoning-vision-15B | Phi-4-reasoning-vision-15B – drive pondering | Kimi-VL-A3B-Considering | gemma-3-12b-it | Qwen3-VL-8B-Considering-4K | Qwen3-VL-8B-Considering-40K | Qwen3-VL-32B-Thiking-4K | Qwen3-VL-32B-Considering-40K |
|---|---|---|---|---|---|---|---|---|
| AI2D_TEST | 84.8 | 79.7 | 81.2 | 80.4 | 83.5 | 83.9 | 86.9 | 87.2 |
| ChartQA_TEST | 83.3 | 82.9 | 73.3 | 39 | 78 | 78.6 | 78.5 | 79.1 |
| HallusionBench | 64.4 | 63.9 | 70.6 | 65.3 | 71.6 | 73 | 76.4 | 76.6 |
| MathVerse_MINI | 44.9 | 53.1 | 61 | 29.8 | 67.3 | 73.3 | 78.3 | 78.2 |
| MathVision_MINI | 36.2 | 36.2 | 50.3 | 31.9 | 43.1 | 50.7 | 60.9 | 58.6 |
| MathVista_MINI | 75.2 | 74.1 | 78.6 | 57.4 | 77.7 | 79.5 | 83.9 | 83.8 |
| MMMU_VAL | 54.3 | 55 | 60.2 | 50 | 59.3 | 65.3 | 72 | 72.2 |
| MMStar | 64.5 | 63.9 | 69.6 | 59.4 | 69.3 | 72.3 | 75.5 | 75.7 |
| OCRBench | 76 | 73.7 | 79.9 | 75.3 | 81.2 | 82 | 83.7 | 85 |
| ScreenSpot_v2 | 88.2 | 88.1 | 81.8 | 3.5 | 93.3 | 92.7 | 83.1 | 83.1 |
Our mannequin balances pondering and non-thinking efficiency – on common displaying higher accuracy within the default “mixed-reasoning” habits than when forcing pondering vs. non-thinking. Solely in a number of instances does forcing a particular mode enhance efficiency (MathVerse and MMU_val for pondering and ScreenSpot_v2 for non-thinking). In comparison with latest fashionable, open-weight fashions, our mannequin supplies a fascinating trade-off between accuracy and price (as a operate of inference time compute and output tokens), as mentioned beforehand.
Word: All numbers listed here are the results of working benchmarks ourselves and could also be decrease than different beforehand shared numbers. As an alternative of quoting leaderboards, we carried out our personal benchmarking, so we may perceive scaling efficiency as a operate of output token counts for associated fashions. We made our greatest effort to run truthful evaluations and used advisable analysis platforms with model-specific advisable settings and prompts offered for all third-party fashions. For Qwen fashions we use the advisable token counts and likewise ran evaluations matching our max output token rely of 4096. For Phi-4-reasoning-vision-15B, we used our system immediate and chat template however didn’t do any customized user-prompting or parameter tuning, and we ran all evaluations with temperature=0.0, grasping decoding, and 4096 max output tokens. These numbers are offered for comparability and evaluation quite than as leaderboard claims. For max transparency and equity, we’ll launch all our analysis logs publicly. For extra particulars on our analysis methodology, please see our technical report (opens in new tab).
Security
As with different Phi fashions, Phi-4-reasoning-vision-15B was developed with security as a core consideration all through coaching and analysis. The mannequin was educated on a combination of public security datasets and internally generated examples designed to elicit behaviors the mannequin ought to appropriately refuse, in alignment with Microsoft’s Accountable AI Rules. For additional particulars, try our technical report (opens in new tab).
Open launch and neighborhood engagement
Phi-4-reasoning-vision-15B is offered on Microsoft Foundry (opens in new tab) and HuggingFace (opens in new tab) with further examples and particulars on GitHub (opens in new tab). For added steering on find out how to use our mannequin correctly and safely, please consult with our Mannequin card (opens in new tab). For additional particulars on the technical points of the mannequin, coaching, and analysis, see our technical report (opens in new tab).
In step with our objective of supporting future AI growth locally, Phi-4-reasoning-vision-15B is launched beneath a permissive license with mannequin weights, high-quality‑tuning code, and benchmark logs. We intend this launch to enhance present work by offering concrete artifacts that assist shut gaps in understanding how compact multimodal reasoning fashions might be constructed and studied.
Trying ahead
Smaller imaginative and prescient–language fashions with selective, activity‑conscious reasoning supply one promising route for making multimodal methods extra sensible and accessible. We current our mannequin and its learnings to tell ongoing analysis in multimodal modeling, laptop‑utilizing brokers, and mathematical scientific reasoning. We hope these particulars are helpful to researchers exploring related tradeoffs and invite important analysis, replication, and extension by the neighborhood. When you’d like to affix us and assist form the way forward for multimodal fashions, please apply for one in every of our open roles.
Acknowledgements
We thank Rachel Ward for her intensive work on information assortment and curation. We thank the GenDatasets, PhiGround, SimCity, and Fara-7B efforts for invaluable coaching information. We thank Harkirat Behl, Mojan Javaheripi, and Suriya Gunasekar for offering us with Phi-4 checkpoints and steering on coaching with Phi fashions. We moreover thank Sahaj Agarwal, Ahmed Awadallah, Qi Dai, Gustavo de Rosa, Rafah Hosn, Ece Kamar, Piero Kauffmann, Yash Lara, Chong Luo, Caio César Teodoro Mendes, Akshay Nambi, Craig Presti, Matthew Rosoff, Corby Rosset, Marco Rossi, Kashyap Patel, Adil Salim, Sidhartha Sen, Shital Shah, Pratyusha Sharma, Alexey Taymanov, Vibhav Vineet, John Weiss, Spencer Whitehead, the AI Frontiers Workforce and Management, and Microsoft Analysis Management, for his or her priceless assist, insightful discussions, and continued help all through this work.