

{kind=link}
 |
Right now, I’m excited to announce that Amazon S3 Vectors is now typically accessible with considerably elevated scale and production-grade efficiency capabilities. S3 Vectors is the primary cloud object storage with native help to retailer and question vector knowledge. You should utilize it that can assist you scale back the full value of storing and querying vectors by as much as 90% when in comparison with specialised vector database options.
Since we introduced the preview of S3 Vectors in July, I’ve been impressed by how shortly you adopted this new functionality to retailer and question vector knowledge. In simply over 4 months, you created over 250,000 vector indexes and ingested greater than 40 billion vectors, performing over 1 billion queries (as of November twenty eighth).
Now you can retailer and search throughout as much as 2 billion vectors in a single index, that’s as much as 20 trillion vectors in a vector bucket and a 40x improve from 50 million per index throughout preview. This implies that you may consolidate your total vector dataset into one index, eradicating the necessity to shard throughout a number of smaller indexes or implement advanced question federation logic.
Question efficiency has been optimized. Rare queries proceed to return leads to underneath one second, with extra frequent queries now leading to latencies round 100ms or much less, making it well-suited for interactive purposes similar to conversational AI and multi-agent workflows. You can even retrieve as much as 100 search outcomes per question, up from 30 beforehand, offering extra complete context for retrieval augmented era (RAG) purposes.
The write efficiency has additionally improved considerably, with help for as much as 1,000 PUT transactions per second when streaming single-vector updates into your indexes, delivering considerably larger write throughput for small batch sizes. This larger throughput helps workloads the place new knowledge have to be instantly searchable, serving to you ingest small knowledge corpora shortly or deal with many concurrent sources writing concurrently to the identical index.
The totally serverless structure removes infrastructure overhead—there’s no infrastructure to arrange or sources to provision. You pay for what you utilize as you retailer and question vectors. This AI-ready storage gives you with fast entry to any quantity of vector knowledge to help your full AI improvement lifecycle, from preliminary experimentation and prototyping by way of to large-scale manufacturing deployments. S3 Vectors now gives the dimensions and efficiency wanted for manufacturing workloads throughout AI brokers, inference, semantic search, and RAG purposes.
Two key integrations that had been launched in preview are actually typically accessible. You should utilize S3 Vectors as a vector storage engine for Amazon Bedrock Data Base. Specifically, you need to use it to construct RAG purposes with production-grade scale and efficiency. Furthermore, S3 Vectors integration with Amazon OpenSearch is now typically accessible, so that you could use S3 Vectors as your vector storage layer whereas utilizing OpenSearch for search and analytics capabilities.
Now you can use S3 Vectors in 14 AWS Areas, increasing from 5 AWS Areas in the course of the preview.
Let’s see the way it works
On this put up, I display how one can use S3 Vectors by way of the AWS Console and CLI.
First, I create an S3 Vector bucket and an index.
echo "Creating S3 Vector bucket..."
aws s3vectors create-vector-bucket
--vector-bucket-name "$BUCKET_NAME"
echo "Creating vector index..."
aws s3vectors create-index
--vector-bucket-name "$BUCKET_NAME"
--index-name "$INDEX_NAME"
--data-type "float32"
--dimension "$DIMENSIONS"
--distance-metric "$DISTANCE_METRIC"
--metadata-configuration "nonFilterableMetadataKeys=AMAZON_BEDROCK_TEXT,AMAZON_BEDROCK_METADATA"The dimension metric should match the dimension of the mannequin used to compute the vectors. The gap metric signifies to the algorithm to compute the space between vectors. S3 Vectors helps cosine and euclidian distances.
I may also use the console to create the bucket. We’ve added the potential to configure encryption parameters at creation time. By default, indexes use the bucket-level encryption, however I can override bucket-level encryption on the index degree with a customized AWS Key Administration Service (AWS KMS) key.
I can also add tags for the vector bucket and vector index. Tags on the vector index assist with entry management and value allocation.
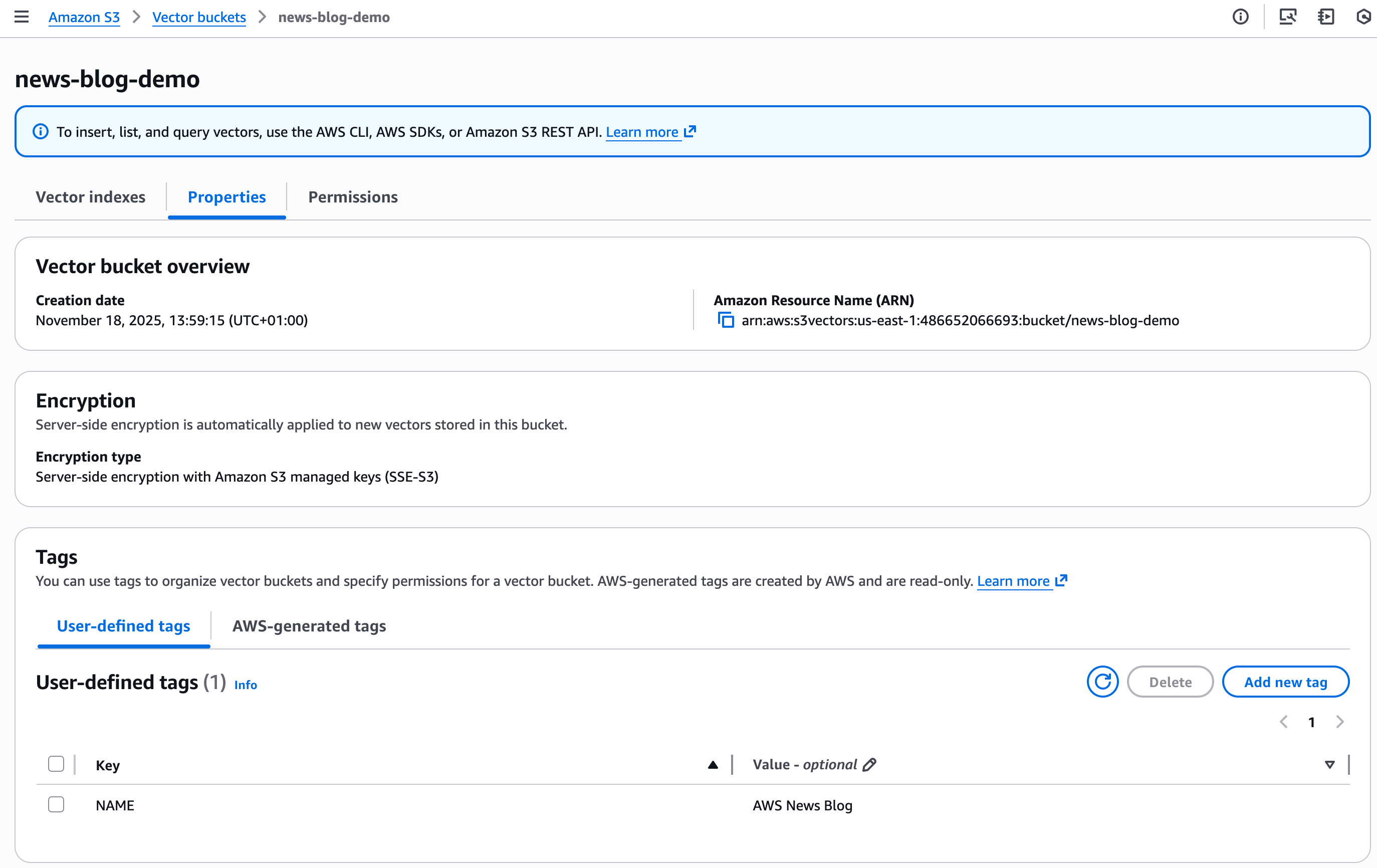
And I can now handle Properties and Permissions instantly within the console.
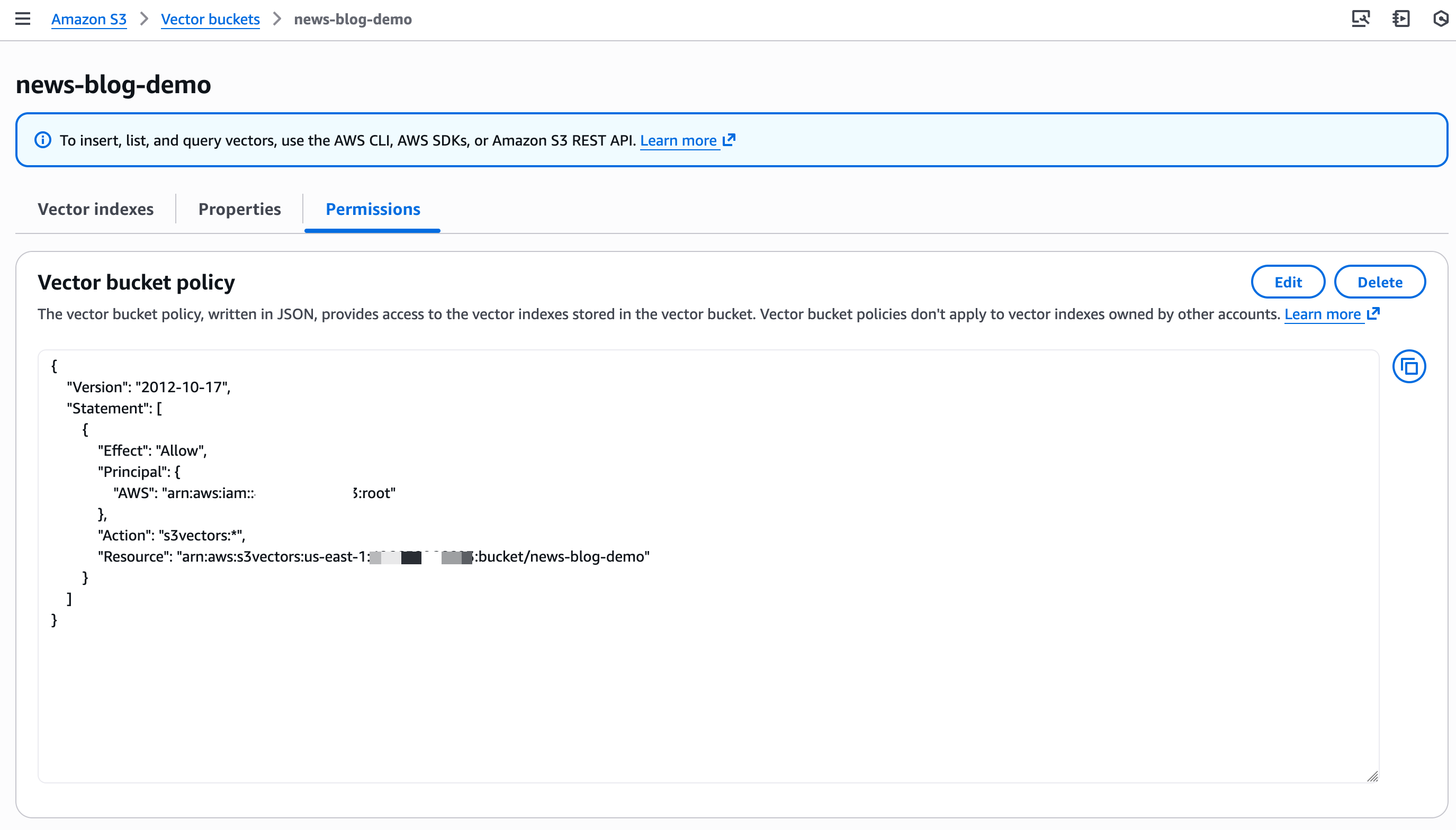
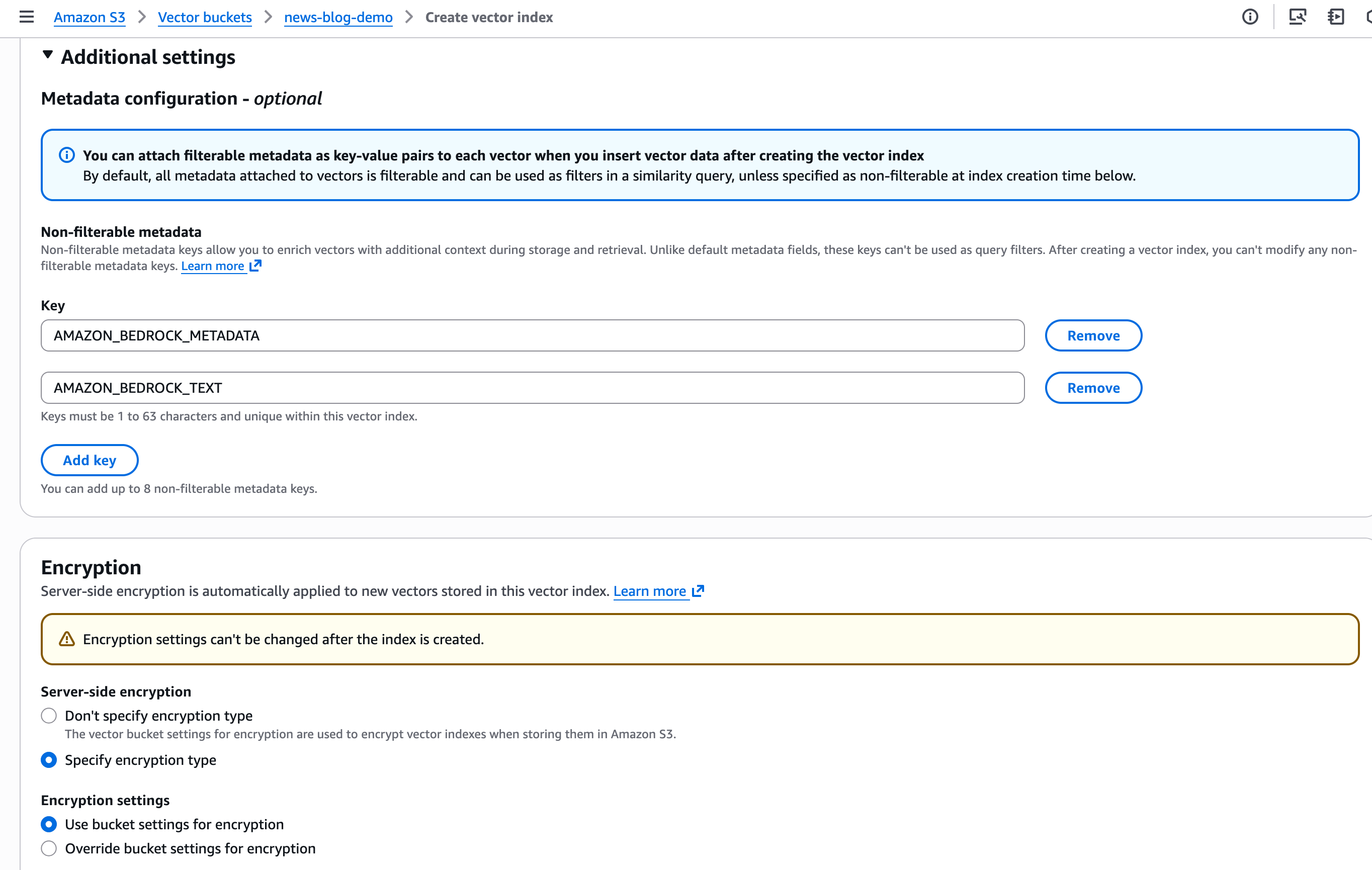
Equally, I outline Non-filterable metadata and I configure Encryption parameters for the vector index.
Subsequent, I create and retailer the embeddings (vectors). For this demo, I ingest my fixed companion: the AWS Fashion Information. That is an 800-page doc that describes how one can write posts, technical documentation, and articles at AWS.
I take advantage of Amazon Bedrock Data Bases to ingest the PDF doc saved on a basic goal S3 bucket. Amazon Bedrock Data Bases reads the doc and splits it in items referred to as chunks. Then, it computes the embeddings for every chunk with the Amazon Titan Textual content Embeddings mannequin and it shops the vectors and their metadata on my newly created vector bucket. The detailed steps for that course of are out of the scope of this put up, however you possibly can learn the directions within the documentation.
When querying vectors, you possibly can retailer as much as 50 metadata keys per vector, with as much as 10 marked as non-filterable. You should utilize the filterable metadata keys to filter question outcomes based mostly on particular attributes. Subsequently, you possibly can mix vector similarity search with metadata situations to slim down outcomes. You can even retailer extra non-filterable metadata for bigger contextual info. Amazon Bedrock Data Bases computes and shops the vectors. It additionally provides giant metadata (the chunk of the unique textual content). I exclude this metadata from the searchable index.
There are different strategies to ingest your vectors. You may attempt the S3 Vectors Embed CLI, a command line software that helps you generate embeddings utilizing Amazon Bedrock and retailer them in S3 Vectors by way of direct instructions. You can even use S3 Vectors as a vector storage engine for OpenSearch.
Now I’m prepared to question my vector index. Let’s think about I ponder how one can write “open supply”. Is it “open-source”, with a hyphen, or “open supply” and not using a hyphen? Ought to I take advantage of uppercase or not? I need to search the related sections of the AWS Fashion Information relative to “open supply.”
# 1. Create embedding request
echo '{"inputText":"Ought to I write open supply or open-source"}' | base64 | tr -d 'n' > body_encoded.txt
# 2. Compute the embeddings with Amazon Titan Embed mannequin
aws bedrock-runtime invoke-model
--model-id amazon.titan-embed-text-v2:0
--body "$(cat body_encoded.txt)"
embedding.json
# Search the S3 Vectors index for comparable chunks
vector_array=$(cat embedding.json | jq '.embedding') &&
aws s3vectors query-vectors
--index-arn "$S3_VECTOR_INDEX_ARN"
--query-vector "{"float32": $vector_array}"
--top-k 3
--return-metadata
--return-distance | jq -r '.vectors[] | "Distance: (.distance) | Supply: (.metadata."x-amz-bedrock-kb-source-uri" | break up("/")[-1]) | Textual content: (.metadata.AMAZON_BEDROCK_TEXT[0:100])..."'The primary end result exhibits this JSON:
{
"key": "348e0113-4521-4982-aecd-0ee786fa4d1d",
"metadata": {
"x-amz-bedrock-kb-data-source-id": "0SZY6GYPVS",
"x-amz-bedrock-kb-source-uri": "s3://sst-aws-docs/awsstyleguide.pdf",
"AMAZON_BEDROCK_METADATA": "{"createDate":"2025-10-21T07:49:38Z","modifiedDate":"2025-10-23T17:41:58Z","supply":{"sourceLocation":"s3://sst-aws-docs/awsstyleguide.pdf"",
"AMAZON_BEDROCK_TEXT": "[redacted] open supply (adj., n.) Two phrases. Use open supply as an adjective (for instance, open supply software program), or as a noun (for instance, the code all through this tutorial is open supply). Do not use open-source, opensource, or OpenSource. [redacted]",
"x-amz-bedrock-kb-document-page-number": 98.0
},
"distance": 0.63120436668396
}It finds the related part within the AWS Fashion Information. I need to write “open supply” and not using a hyphen. It even retrieved the web page quantity within the authentic doc to assist me cross-check the suggestion with the related paragraph within the supply doc.
Yet one more factor
S3 Vectors has additionally expanded its integration capabilities. Now you can use AWS CloudFormation to deploy and handle your vector sources, AWS PrivateLink for personal community connectivity, and useful resource tagging for value allocation and entry management.
Pricing and availability
S3 Vectors is now accessible in 14 AWS Areas, including Asia Pacific (Mumbai, Seoul, Singapore, Tokyo), Canada (Central), and Europe (Eire, London, Paris, Stockholm) to the present 5 Areas from preview (US East (Ohio, N. Virginia), US West (Oregon), Asia Pacific (Sydney), and Europe (Frankfurt))
Amazon S3 Vectors pricing relies on three dimensions. PUT pricing is calculated based mostly on the logical GB of vectors you add, the place every vector consists of its logical vector knowledge, metadata, and key. Storage prices are decided by the full logical storage throughout your indexes. Question expenses embody a per-API cost plus a $/TB cost based mostly in your index dimension (excluding non-filterable metadata). As your index scales past 100,000 vectors, you profit from decrease $/TB pricing. As typical, the Amazon S3 pricing web page has the main points.
To get began with S3 Vectors, go to the Amazon S3 console. You may create vector indexes, begin storing your embeddings, and start constructing scalable AI purposes. For extra info, try the Amazon S3 Person Information or the AWS CLI Command Reference.
I sit up for seeing what you construct with these new capabilities. Please share your suggestions by way of AWS re:Publish or your typical AWS Assist contacts.