

{kind=link}
There are a number of benchmarks that probe the frontier of agent capabilities (GDPval, Humanity’s Final Examination (HLE), ARC-AGI-2), however we don’t discover them consultant of the sorts of duties which might be vital to our clients. To fill this hole, we have created and are open-sourcing OfficeQA—a benchmark that proxies for economically useful duties carried out by Databricks’ enterprise clients. We give attention to a quite common but difficult enterprise activity: Grounded Reasoning, which includes answering questions based mostly on complicated proprietary datasets that embody unstructured paperwork and tabular knowledge.
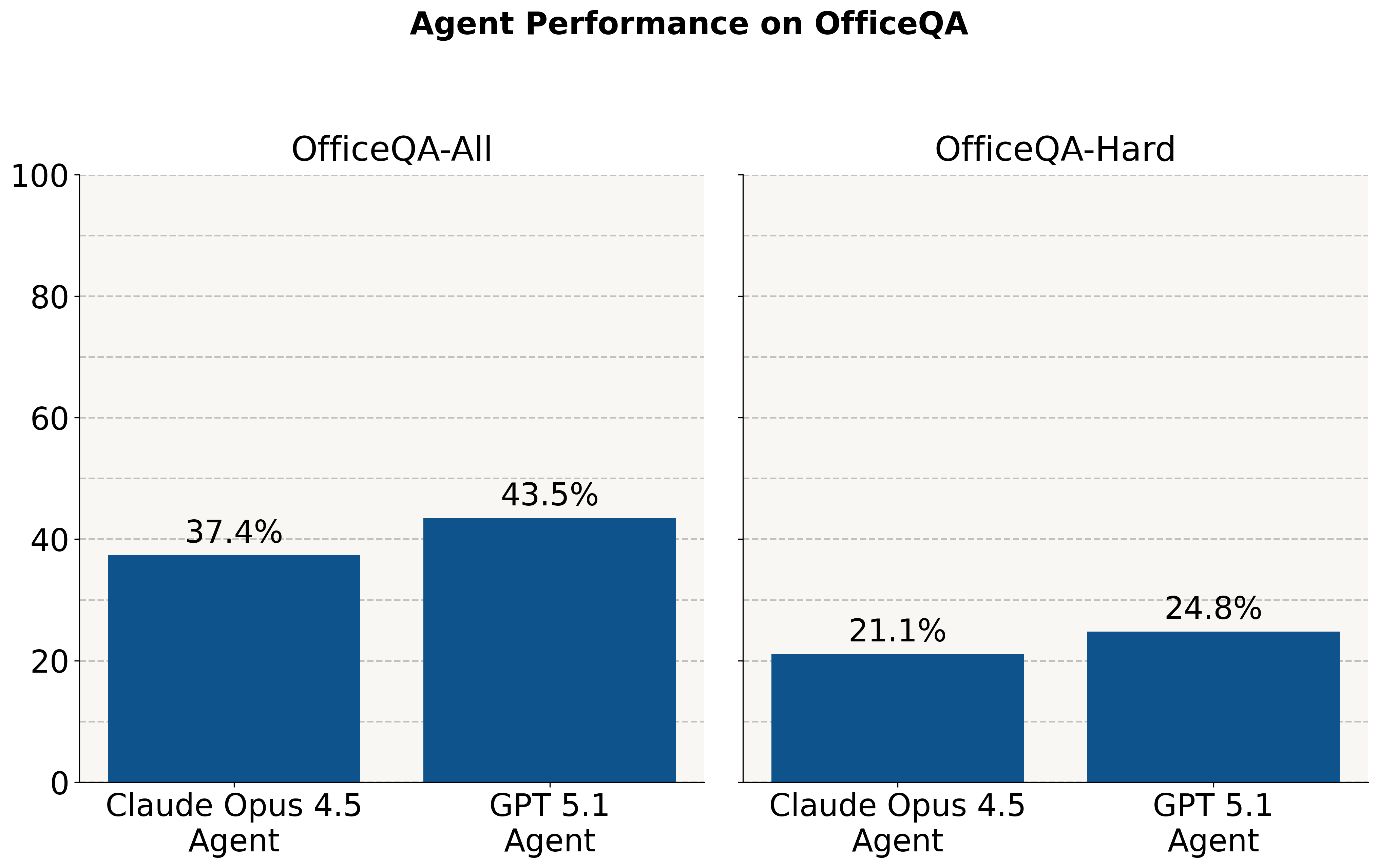
Regardless of frontier fashions performing properly on Olympiad-style questions, we discover they nonetheless wrestle on these economically vital duties. With out entry to the corpus, they reply ~2% of questions accurately. When supplied with a corpus of PDF paperwork, brokers carry out at <45% accuracy throughout all questions and <25% on a subset of the toughest questions.
On this publish, we first describe OfficeQA and our design rules. We then consider present AI agent options — together with a GPT-5.1 Agent utilizing OpenAI’s File Search & Retrieval API and a Claude Opus 4.5 Agent utilizing Claude’s Agent SDK — on the benchmark. We experiment with utilizing Databricks’ ai_parse_document to parse OfficeQA’s corpus of PDFs, and discover that this delivers important positive aspects. Even with these enhancements, we discover that every one techniques nonetheless fall wanting 70% accuracy on the complete benchmark and solely attain round 40% accuracy on the toughest break up, indicating substantial room for enchancment on this activity. Lastly, we announce the Databricks Grounded Reasoning Cup, a contest in Spring 2026 the place AI brokers will compete towards human groups to drive innovation on this area.
Dataset Desiderata
We had a number of key objectives in constructing OfficeQA. First, questions ought to be difficult as a result of they require cautious work—precision, diligence, and time—not as a result of they demand PhD-level experience. Second, every query will need to have a single, clearly right reply that may be checked mechanically towards floor reality, so techniques might be educated and evaluated with none human or LLM judging. Lastly and most significantly, the benchmark ought to precisely replicate frequent issues that enterprise clients face.
We distilled frequent enterprise issues into three fundamental elements:
- Doc complexity: Enterprises have giant collections of supply supplies—equivalent to scans, PDFs, or images—that always include substantial numerical or tabular knowledge.
- Data retrieval and aggregation: They should effectively search, extract, and mix data throughout many such paperwork.
- Analytical reasoning and query answering: They require techniques able to answering questions and performing analyses grounded in these paperwork, generally involving calculations or exterior information.
We additionally notice that many enterprises demand extraordinarily excessive precision when performing these duties. Shut will not be adequate. Being off by one on a product or bill quantity can have catastrophic downstream outcomes. Forecasting income and being off by 5% can result in dramatically incorrect enterprise selections.
Present benchmarks don’t meet our wants: | ||
|
| Instance |
GDPVal | Duties are clear examples of economically useful duties, however most don’t particularly take a look at for issues our clients care about. Skilled human judging is beneficial. This benchmark additionally offers solely the set of paperwork wanted to reply every query instantly, which doesn’t permit for analysis of agent retrieval capabilities over a big corpus. | “You’re a Music Producer in Los Angeles in 2024. You might be employed by a consumer to create an instrumental observe for a music video for a track referred to as ‘Deja Vu’” |
ARC-AGI-2 | Duties are so summary as to be divorced from the connection to actual world economically useful duties – they contain summary visible manipulation of coloured grids. Very small, specialised fashions are able to matching the efficiency of far bigger (1000x) basic function LLMs. | 
|
Humanity’s Final Examination (HLE) | Not clearly consultant of most economically useful work, and definitely not consultant of the workloads of Databricks’ clients. Questions require PhD-level experience and no single human is probably going capable of reply all of the questions. | “Compute the decreased twelfth dimensional Spin bordism of the classifying area of the Lie group G2. “Lowered” means that you may ignore any bordism lessons that may be represented by manifolds with trivial principal G2 bundle.” |
Introducing the OfficeQA Benchmark
We introduce OfficeQA, a dataset approximating proprietary enterprise corpora, however freely out there and supporting quite a lot of numerous and fascinating questions. We leverage the U.S. Treasury Bulletins to create this benchmark, traditionally printed month-to-month for 5 a long time starting in 1939 and quarterly thereafter. Every bulletin is 100-200 pages lengthy and consists of prose, many complicated tables, charts and figures describing the operations of the U.S. Treasury – the place cash got here from, the place it’s, the place it went and the way it financed operations. The overall dataset contains ~89,000 pages. Till 1996, the bulletins had been scans of bodily paperwork and afterwards, digitally produced PDFs.
We additionally see worth in making this historic Treasury knowledge extra accessible to the general public, researchers, and teachers. USAFacts is a corporation that naturally shares this imaginative and prescient, on condition that its core mission is “to make authorities knowledge simpler to entry and perceive.” They partnered with us to develop this benchmark, figuring out the Treasury Bulletins as a great dataset and making certain our questions mirrored sensible use circumstances for these paperwork.
In line with our purpose that the questions ought to be answerable by non-expert people, not one of the questions require greater than highschool math operations. We do anticipate most people would want to search for among the monetary or statistical phrases by way of the net.
Dataset Overview
OfficeQA consists of 246 questions organized into two issue ranges – simple and laborious – based mostly on the efficiency of present AI techniques on the questions. “Straightforward” questions are outlined as questions that each of the frontier agent techniques (detailed under) received right, and “Exhausting” questions are questions that at the very least one of many brokers answered incorrectly.
The questions on common require data from ~2 totally different Treasury Bulletin paperwork. Throughout a consultant pattern of the benchmark, human solvers averaged a completion time of fifty minutes per query. Nearly all of this time was spent finding the knowledge required to reply the query throughout quite a few tables and figures throughout the corpus.
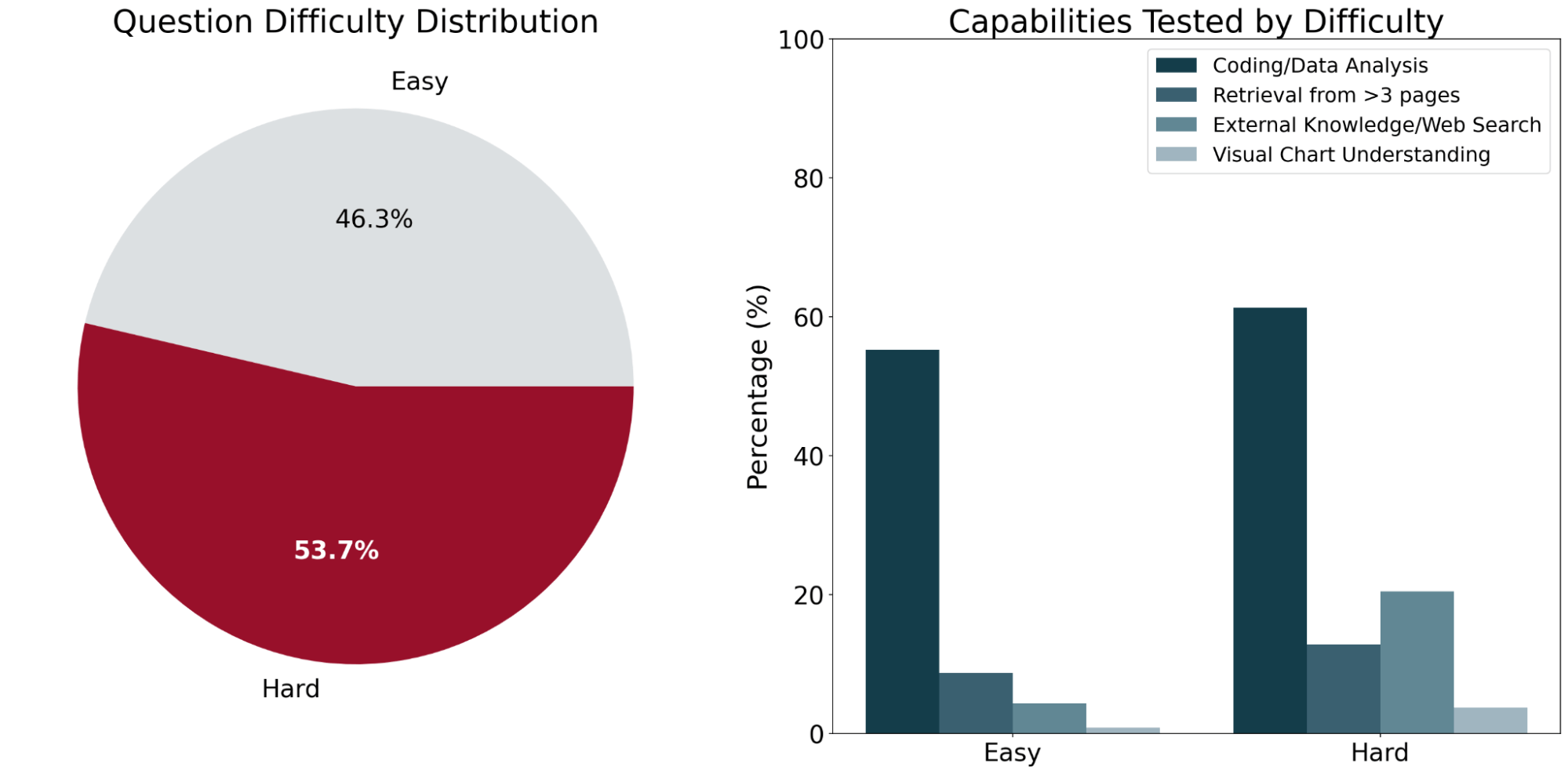
To make sure the questions in OfficeQA required document-grounded retrieval, we made finest effort to filter out any questions that LLMs may reply accurately with out entry to the supply paperwork (i.e., may very well be answered by way of a mannequin’s parametric information or internet search). Most of those filtered questions tended to be easier, or ask about extra basic information, like “Within the fiscal 12 months that George H.W. Bush first grew to become president, which U.S federal belief fund had the most important improve in funding?”
Apparently, there have been just a few seemingly extra complicated questions that fashions had been capable of reply with parametric information alone like “Conduct a two-sample t-test to find out whether or not the imply U.S Treasury bond rate of interest modified between 1942–1945 (earlier than the tip of World Battle II) and 1946–1949 (after the tip of World Battle II) on the 5% significance stage. What’s the calculated t-statistic, rounded to the closest hundredth?” On this case, the mannequin leverages historic monetary data that had been memorized throughout pre-training after which computes the ultimate worth accurately. Examples like these had been filtered from the ultimate benchmark.
Instance OfficeQA Questions
Straightforward: “What had been the whole expenditures (in tens of millions of nominal {dollars}) for U.S nationwide protection within the calendar 12 months of 1940?”
This requires a fundamental worth look-up, and summing of the values for the months within the specified calendar 12 months in a single desk (highlighted in crimson). Notice that the totals for prior years are for fiscal and never calendar years.
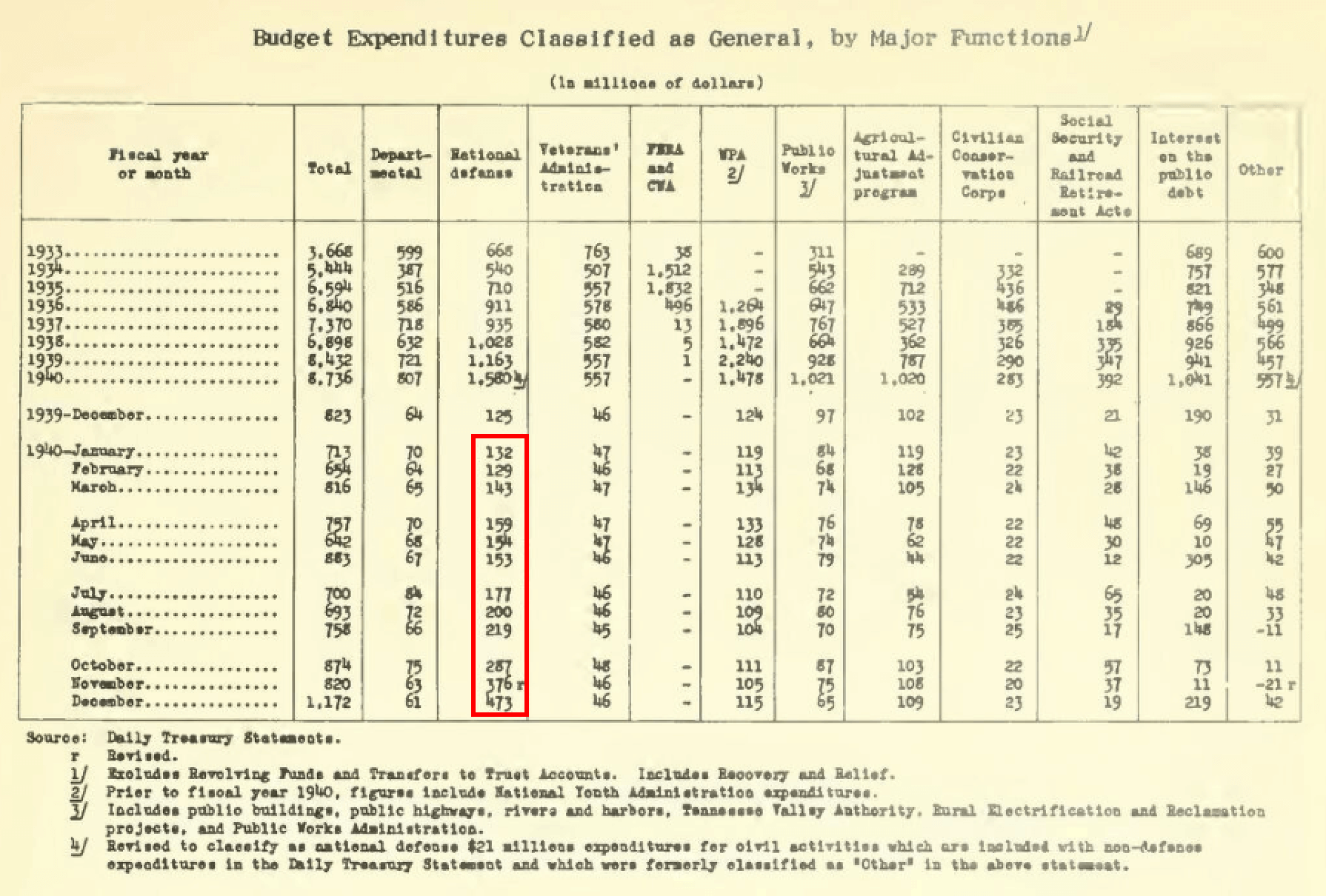
Exhausting: “Predict the whole outlays of the US Division of Agriculture in 1999 utilizing annual knowledge from the years 1990-1998 (inclusive). Use a fundamental linear regression match to supply the slope and y-intercept. Deal with 1990 as 12 months “0” for the time variable. Carry out all calculations in nominal {dollars}. You don’t want to bear in mind postyear changes. Report all values inside sq. brackets, separated by commas, with the primary worth because the slope rounded to the closest hundredth, the second worth because the y-intercept rounded to the closest complete quantity and the third worth as the expected worth rounded to the closest complete quantity.”
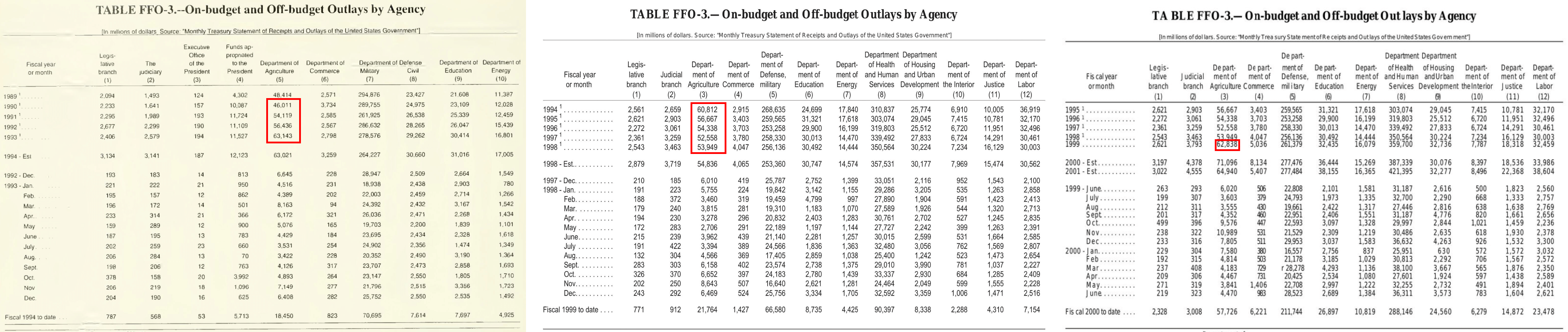
This requires discovering data whereas navigating throughout a number of paperwork (pictured above), and includes extra superior reasoning and statistical calculation with detailed answering tips.
Baseline Brokers: Implementation and Efficiency
We consider the next baselines1:
- GPT-5.1 Agent with File Search: We use GPT-5.1, configured with reasoning_effort=excessive, by way of the OpenAI Responses API and provides it entry to instruments like file search and internet search. The PDFs are uploaded to the OpenAI Vector Retailer, the place they’re mechanically parsed and listed. We additionally experiment with offering the Vector Retailer with pre-parsed paperwork utilizing ai_parse_document.
- Claude Opus 4.5 Agent: We use Claude’s Agent Python SDK with Claude Opus 4.5 as a backend (default considering=excessive) and configure this agent with the SDK-offered autonomous capabilities like context administration and a built-in device ecosystem containing instruments like file search (learn, grep, glob, and so on.), internet search, programming execution and different device functionalities. Because the Claude Agent SDK didn’t present its personal built-in parsing answer, we experimented with (1) offering the agent with the PDFs saved in a neighborhood folder sandbox and talent to put in PDF reader packages like
pdftotextandpdfplumber, and (2) offering the agent with pre-parsed paperwork utilizing ai_parse_document. - LLM with Oracle PDF Web page(s): We consider Claude Opus 4.5 and GPT 5.1 by instantly offering the mannequin with the precise oracle PDF(s) web page(s) required for answering the query. This can be a non-agentic baseline that measures how properly LLMs can carry out with the supply materials obligatory for reasoning and deriving the proper response, representing an higher sure of efficiency assuming an oracle retrieval system.
- LLM with Oracle Parsed PDF Web page(s): We additionally take a look at offering Claude Opus 4.5 and GPT-5.1 instantly with the pre-parsed Oracle PDF web page(s) required to reply the query, which have been parsed utilizing ai_parse_document.
For all experiments, we take away any present OCR layer from the U.S. Treasury Bulletin PDFs resulting from their low accuracy. This ensures truthful analysis of every agent’s capacity to extract and interpret data instantly from the scanned paperwork.
We plot the correctness of all of the brokers under on the y-axis whereas the x-axis is the allowable absolute relative error to be thought-about right. For instance, if the reply to a query is ‘5.2 million’ and the agent solutions ‘5.1 million’ (1.9% off from the unique reply), the agent could be scored as right at something above a 1.9% allowable absolute relative error, and incorrect at something <1.9%.
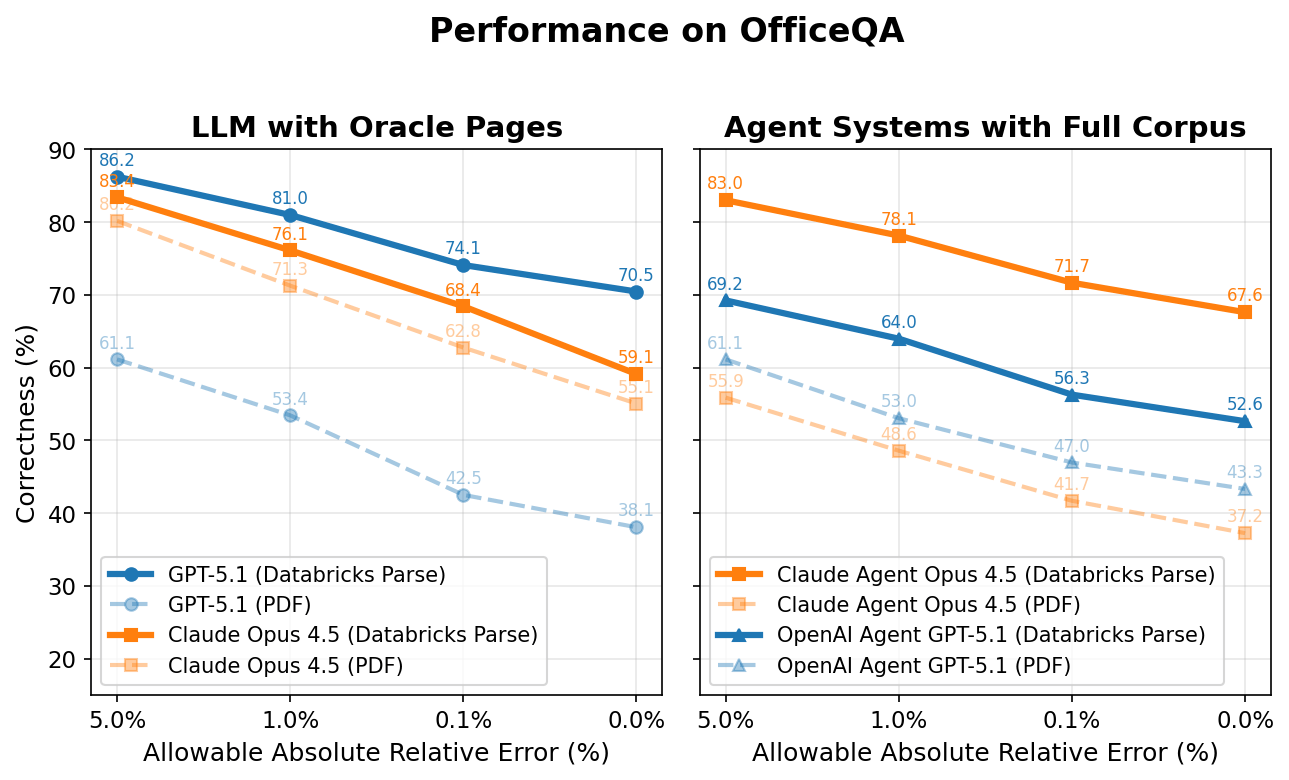
LLM with Oracle Web page(s)
Apparently, each Claude Opus 4.5 and GPT 5.1 carry out poorly even when supplied instantly with the oracle PDF web page(s) wanted for every query. Nonetheless, when these similar pages are preprocessed utilizing Databricks ai_parse_document, efficiency jumps considerably—by +4.0 and +32.4 share factors for Claude Opus 4.5 and GPT 5.1 respectively (representing +7.5% and +85.0% relative will increase).
With parsing, the best-performing mannequin (GPT-5.1) reaches roughly 70% accuracy. The remaining ~30% hole stems from a number of elements: (1) these non-agent baselines lack entry to instruments like internet search, which ~13% of questions require; (2) parsing and extraction errors from tables and charts happen; and (3) computational reasoning errors stay.
Agent Techniques with Full Corpus
When supplied with the OfficeQA corpus instantly, each brokers reply over half of OfficeQA questions incorrectly – reaching a most efficiency of 43.3% at 0% allowable error. Offering brokers with paperwork parsed with Databricks ai_parse_document improves efficiency as soon as once more: the Claude 4.5 Opus Agent improves by +30.4 share factors and the GPT 5.1 Agent by +9.3 share factors (81.7% and 21.5% relative will increase, respectively).
Nonetheless, even the very best agent – Claude Agent with Claude Opus 4.5 – nonetheless achieves lower than 70% % correctness at 0% allowable error with parsed paperwork, underscoring the problem of those duties for frontier AI techniques. Attaining this greater efficiency additionally requires greater latency and related price. On common, the Claude Agent takes ~5 minutes to reply every query, whereas the lower-scoring OpenAI agent takes ~3 minutes.
As anticipated, correctness scores progressively improve when greater absolute relative errors are allowed. Such discrepancies come up from precision divergence, the place the brokers could use supply values which have slight variations that drift throughout cascading operations and produce small ultimate deviations within the ultimate reply. Errors embody incorrect parsing (studying ‘508’ as ‘608’, for instance), misinterpretation of statistical values, or an agent’s incapacity to retrieve related and correct data from the corpus. As an example, an agent produces an incorrect but shut reply to the bottom reality for this query: “What’s the sum of every 12 months’s complete Public debt securities excellent held by US Authorities accounts, in nominal tens of millions of {dollars} recorded on the finish of the fiscal years 2005 to 2009 inclusive, returned as a single worth?” The agent finally ends up retrieving data from the June 2010 bulletin, however the related and proper values are discovered within the September 2010 publication (upon reported revisions), leading to a distinction of 21 million {dollars} (0.01% off from the bottom reality).
One other instance that leads to a bigger distinction is inside this query, “Carry out a time sequence evaluation on the reported complete surplus/deficit values from calendar years 1989-2013, treating all values as nominal values in tens of millions of US {dollars} after which match a cubic polynomial regression mannequin to estimate the anticipated surplus or deficit for calendar 12 months 2025 and report absolutely the distinction with the U.S. Treasury’s reported estimate rounded to the closest complete quantity in tens of millions of {dollars}.”, an agent incorrectly retrieves the fiscal 12 months values as a substitute of the calendar 12 months values for 8 years, which modifications the enter sequence used for the cubic regression and results in a unique 2025 prediction and absolute-difference outcome that’s off by $286,831 million (31.6% off from the bottom reality).
Failure Modes
Whereas creating OfficeQA, we noticed a number of frequent failure modes of present AI techniques:
- Parsing errors stay a basic problem—complicated tables with nested column hierarchies, merged cells, and strange formatting typically lead to misaligned or incorrectly extracted values. For instance, we noticed circumstances the place column shifts throughout automated extraction brought about numerical values to be attributed to the incorrect headers fully.
- Reply ambiguity additionally poses difficulties: monetary paperwork just like the U.S. Treasury Bulletin are continuously revised and reissued, that means a number of reputable values could exist for a similar knowledge level relying on which publication date the agent references. Brokers typically cease looking out as soon as they discover a believable reply, lacking probably the most authoritative or up-to-date supply, regardless of being prompted to seek out the most recent values.
- Visible understanding represents one other important hole. Roughly 3% of OfficeQA questions reference charts, graphs, or figures that require visible reasoning. Present brokers continuously fail on these duties, as proven within the instance under.
These remaining failure modes showcase that analysis progress continues to be wanted earlier than AI brokers can deal with the complete spectrum of enterprise in-domain reasoning duties.
Databricks Grounded Reasoning Cup
We are going to pit AI Brokers towards groups of people in Spring 2026 to see who can obtain the very best outcomes on the OfficeQA benchmark.
- Timing: We’re concentrating on San Francisco for the primary occasion, probably between late March and late April. Precise dates might be launched shortly to those that join updates.
- In-Individual Finale: The highest groups might be invited to San Francisco for the ultimate competitors.
We’re presently opening an curiosity listing. Go to the hyperlink to get notified as quickly because the official guidelines, dates, and prize swimming pools are introduced. (Coming quickly!)
Conclusion
The OfficeQA benchmark represents a major step towards evaluating AI brokers on economically useful, real-world grounded reasoning duties. By grounding our benchmark within the U.S. Treasury Bulletins, a corpus of practically 89,000 pages spanning over eight a long time, we now have created a difficult testbed that requires brokers to parse complicated tables, retrieve data throughout many paperwork, and carry out analytical reasoning with excessive precision.
The OfficeQA benchmark is freely out there to the analysis neighborhood and might be discovered right here. We encourage groups to discover OfficeQA and current options on the benchmark as a part of the Databricks Grounded Reasoning Cup.
Authors: Arnav Singhvi, Krista Opsahl-Ong, Jasmine Collins, Ivan Zhou, Cindy Wang, Ashutosh Baheti, Jacob Portes, Sam Havens, Erich Elsen, Michael Bendersky, Matei Zaharia, Xing Chen.
We’d prefer to thank Dipendra Kumar Misra, Owen Oertell, Andrew Drozdov, Jonathan Chang, Simon Favreau-Lessard, Erik Lindgren, Pallavi Koppol, Veronica Lyu, in addition to SuperAnnotate and Turing for serving to to create the questions in OfficeQA.
Lastly, we’d additionally prefer to thank USAFacts for his or her steering in figuring out the U.S. Treasury Bulletins and offering suggestions to make sure questions had been topical and related.
1 We tried to guage the lately launched Gemini File Search Device API as a part of a consultant Gemini Agent baseline with Gemini 3. Nonetheless, about 30% of the PDFs and parsed PDFs within the OfficeQA corpus didn’t ingest, and the File Search Device is incompatible with the Google Search Device. Since this could restrict the agent from answering OfficeQA questions that want exterior information, we excluded this setup from our baseline analysis. We’ll revisit it as soon as ingestion works reliably so we are able to measure its efficiency precisely.