

{kind=link}
The rise of distributed knowledge processing frameworks similar to Apache Spark has revolutionized the way in which organizations handle and analyze large-scale knowledge. Nonetheless, as the amount and complexity of knowledge proceed to develop, the necessity for fine-grained entry management (FGAC) has develop into more and more vital. That is notably true in eventualities the place delicate or proprietary knowledge should be shared throughout a number of groups or organizations, similar to within the case of open knowledge initiatives. Implementing strong entry management mechanisms is essential to take care of safe and managed entry to knowledge saved in Open Desk Format (OTF) inside a contemporary knowledge lake.
One strategy to addressing this problem is by utilizing Amazon EMR on Amazon Elastic Kubernetes Service (Amazon EKS) and incorporating FGAC mechanisms. With Amazon EMR on EKS, you’ll be able to run open supply huge knowledge frameworks similar to Spark on Amazon EKS. This integration offers the scalability and adaptability of Kubernetes, whereas additionally utilizing the information processing capabilities of Amazon EMR.
On February 6th 2025, AWS launched fine-grained entry management primarily based on AWS Lake Formation for EMR on EKS from Amazon EMR 7.7 and better model. Now you can considerably improve your knowledge governance and safety frameworks utilizing this function.
On this submit, we exhibit the best way to implement FGAC on Apache Iceberg tables utilizing EMR on EKS with Lake Formation.
Knowledge mesh use case
With FGAC in a knowledge mesh structure, area homeowners can handle entry to their knowledge merchandise at a granular stage. This decentralized strategy permits for higher agility and management, ensuring knowledge is accessible solely to approved customers and companies inside or throughout domains. Insurance policies could be tailor-made to particular knowledge merchandise, contemplating elements like knowledge sensitivity, consumer roles, and supposed use. This localized management enhances safety and compliance whereas supporting the self-service nature of the information mesh.
FGAC is very helpful in enterprise domains that take care of delicate knowledge, similar to healthcare, finance, authorized, human assets, and others. On this submit, we give attention to examples from the healthcare area, showcasing how we will obtain the next:
- Share affected person knowledge securely – Knowledge mesh permits totally different departments inside a hospital to handle their very own affected person knowledge as unbiased domains. FGAC makes positive solely approved personnel can entry particular affected person information or knowledge parts primarily based on their roles and need-to-know foundation.
- Facilitate analysis and collaboration – Researchers can entry de-identified affected person knowledge from numerous hospital domains by means of the information mesh structure, enabling collaboration between multidisciplinary groups throughout totally different healthcare establishments, fostering data sharing, and accelerating analysis and discovery. FGAC helps compliance with privateness rules (similar to HIPAA) by proscribing entry to delicate knowledge parts or permitting entry solely to aggregated, anonymized datasets.
- Enhance operational effectivity – Knowledge mesh can streamline knowledge sharing between hospitals and insurance coverage firms, simplifying billing and claims processing. FGAC makes positive solely approved personnel inside every group can entry the required knowledge, defending delicate monetary data.
Resolution overview
On this submit, we discover the best way to implement FGAC on Iceberg tables inside an EMR on EKS software, utilizing the capabilities of Lake Formation. For particulars on the best way to implement FGAC on Amazon EMR on EC2, seek advice from Nice-grained entry management in Amazon EMR Serverless with AWS Lake Formation.
The next parts play important roles on this resolution design:
- Apache Iceberg OTF:
- Excessive-performance desk format for large-scale analytics
- Helps schema evolution, ACID transactions, and time journey
- Suitable with Spark, Trino, Presto, and Flink
- Amazon S3 Tables totally managed Iceberg tables for analytics workload
- AWS Lake Formation:
- FGAC for knowledge lakes
- Column-, row-, and cell-level safety controls
- Knowledge mesh producers and customers:
- Producers: Create and serve domain-specific knowledge merchandise
- Shoppers: Entry and combine knowledge merchandise
- Allows self-service knowledge consumption
To exhibit how you should utilize Lake Formation to implement cross-account FGAC inside an EMR on EKS surroundings, we create tables within the AWS Glue Knowledge Catalog in a central AWS account appearing as producer and provision totally different consumer personas to mirror numerous roles and entry ranges in a separate AWS account appearing as a number of customers. Shoppers could be unfold throughout a number of accounts in real-world eventualities.
The next diagram illustrates the high-level resolution structure.
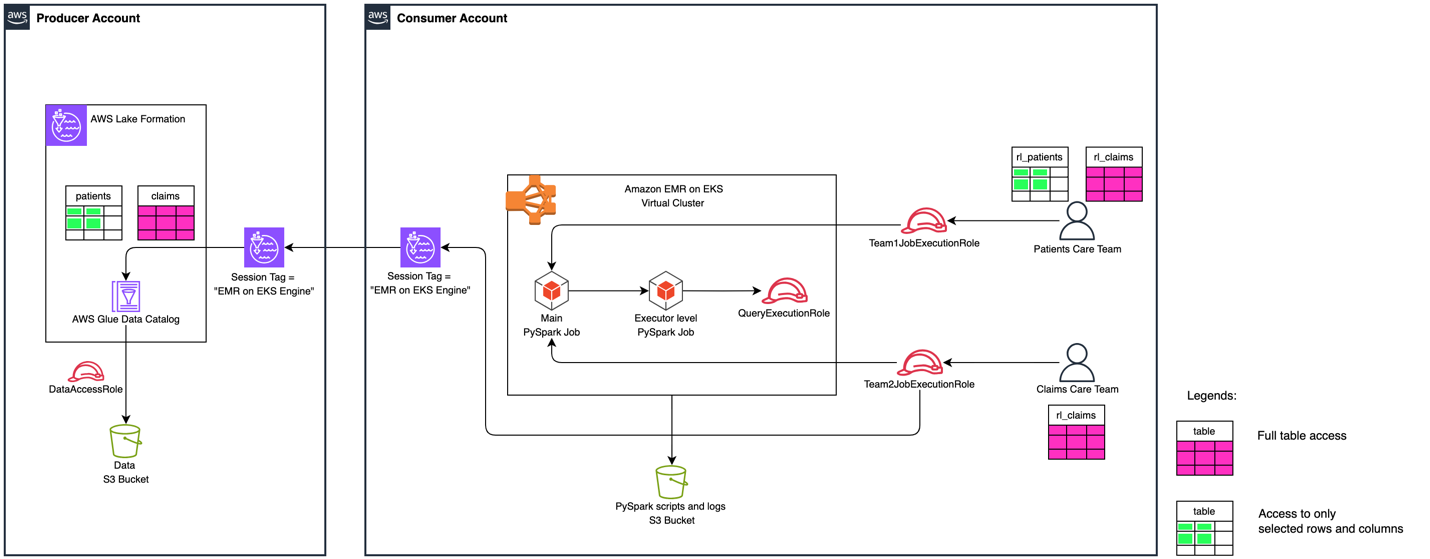
Determine 1: Excessive Stage Resolution Structure
To exhibit the cross-account knowledge sharing and knowledge filtering with Lake Formation FGAC, the answer deploys two totally different Iceberg tables with different entry for various customers. The permission mapping for customers are with cross-account desk shares and knowledge cell filters.
It has two totally different groups with totally different ranges of Lake Formation permissions to entry Sufferers and Claims Iceberg tables. The next desk summarizes the answer’s consumer personas.
| Persona/Desk Identify | Sufferers | Claims |
Sufferers Care Crew ( |
| Full desk entry |
Claims Care Crew ( | No entry | Full desk entry |
Stipulations
This resolution requires an AWS account with an AWS Id and Entry Administration (IAM) energy consumer position that may create and work together with AWS companies, together with Amazon EMR, Amazon EKS, AWS Glue, Lake Formation, and Amazon Easy Storage Service (Amazon S3). Extra particular necessities for every account are detailed within the related sections.
Clone the venture
To get began, obtain the venture both to your pc or the AWS CloudShell console:
Arrange infrastructure in producer account
To arrange the infrastructure within the producer account, you should have the next further assets:
The setup script deploys the next infrastructure:
- An S3 bucket to retailer pattern knowledge in Iceberg desk format, registered as an information location in Lake Formation
- An AWS Glue database named
healthcare_db - Two AWS Glue tables:
SufferersandClaimsIceberg tables - A Lake Formation knowledge entry IAM position
- Cross-account permissions enabled for the buyer account:
- Enable the buyer to explain the database
healthcare_dbwithin the producer account - Enable to entry the
Sufferersdesk utilizing an information cell filter, primarily based on row-level chosenstate, and exclude columnssn - Enable full desk entry to the
Claimsdesk
- Enable the buyer to explain the database
Run the next producer_iceberg_datalake_setup.sh script to create a growth surroundings within the producer account. Replace its parameters based on your necessities:
Allow cross-account Lake Formation entry in producer account
A shopper account ID and an EMR on EKS Engine session tag should set within the producer’s surroundings. It permits the buyer to entry the producer’s AWS Glue tables ruled by Lake Formation. Full the next steps to allow cross-account entry:
- Open the Lake Formation console within the producer account.
- Select Utility integration settings beneath Administration within the navigation pane.
- Choose Enable exterior engines to filter knowledge in Amazon S3 places registered with Lake Formation.
- For Session tag values, enter EMR on EKS Engine.
- For AWS account IDs, enter your shopper account ID.
- Select Save.
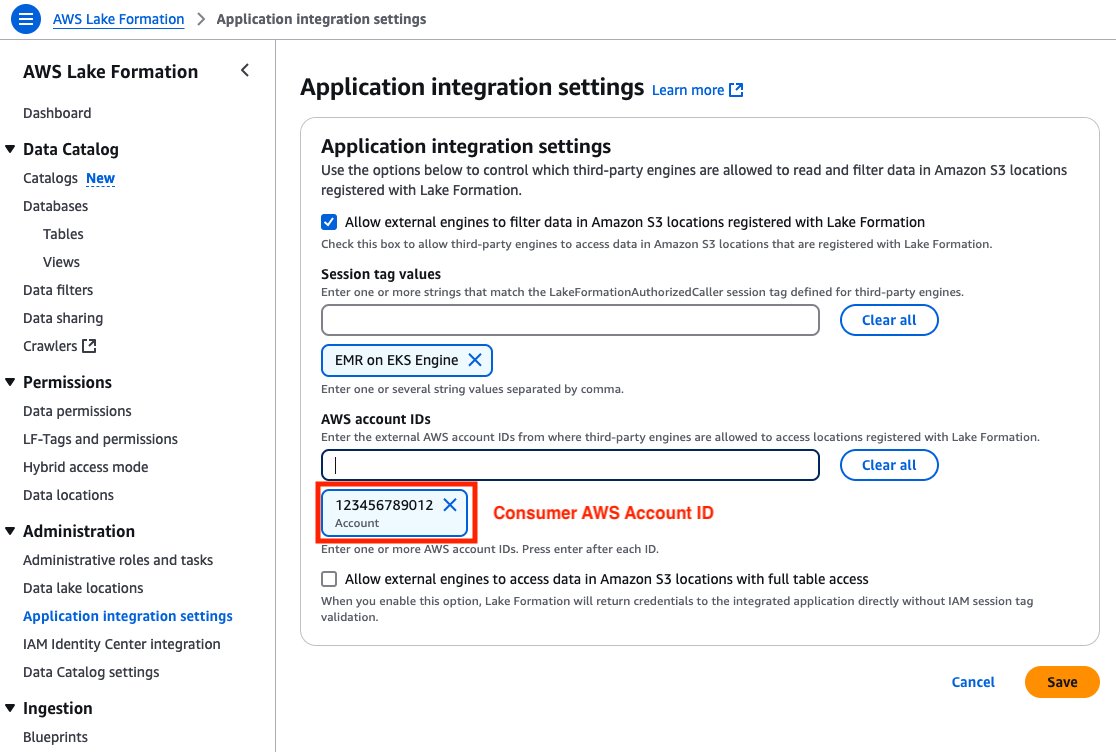
Determine 2: Producer Account – Lake Formation third-party engine configuration display screen with session tags, account IDs, and knowledge entry permissions.
Validate FGAC setup in producer surroundings
To validate the FGAC setup within the producer account, verify the Iceberg tables, knowledge filter, and FGAC permission settings.
Iceberg tables
Two AWS Glue tables in Iceberg format have been created by producer_iceberg_datalake_setup.sh. On the Lake Formation console, select Tables beneath Knowledge Catalog within the navigation pane to see the tables listed.
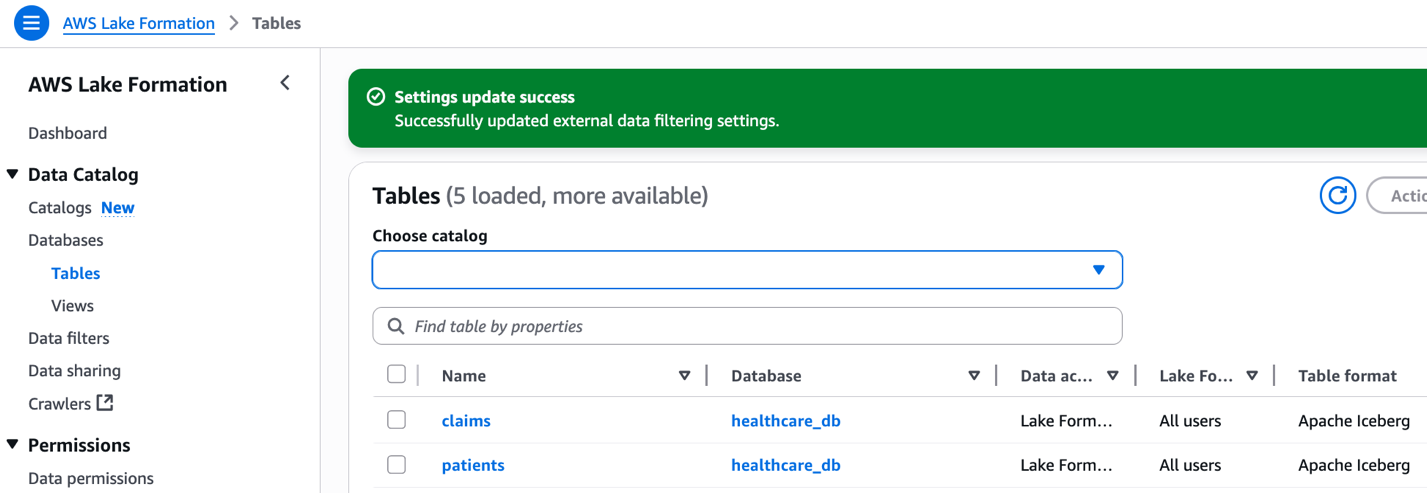
Determine 3: Lake Formation interface displaying claims and sufferers tables from healthcare_db with Apache Iceberg format.
The next screenshot reveals an instance of the sufferers desk knowledge.
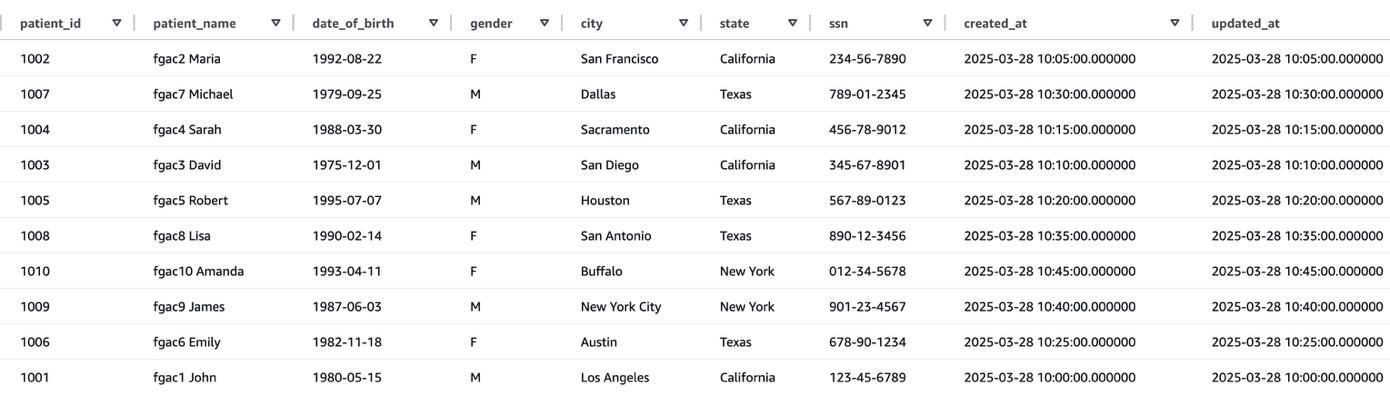
Determine 4: Sufferers desk knowledge
The next screenshot reveals an instance of the claims desk knowledge.
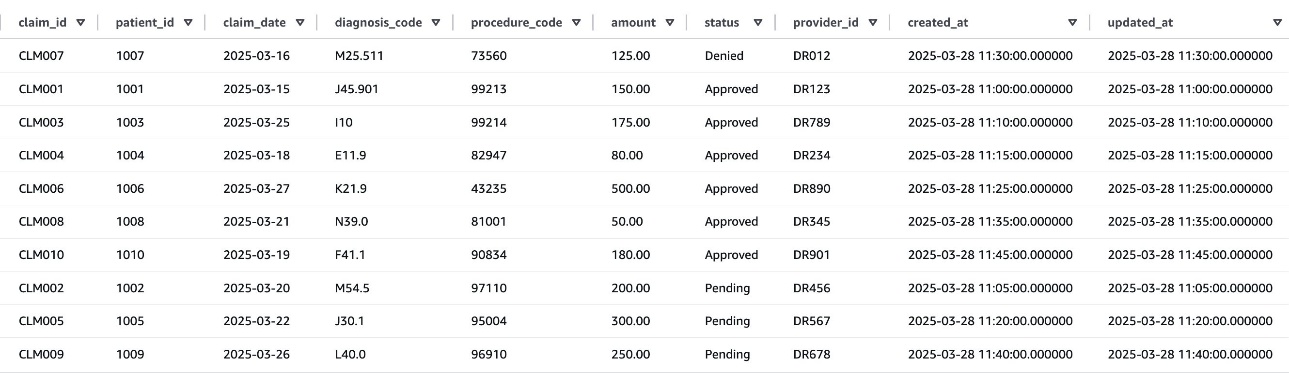
Determine 5: Claims desk knowledge
Knowledge cell filter in opposition to sufferers desk
After efficiently operating the producer_iceberg_datalake_setup.sh script, a brand new knowledge cell filter named patients_column_row_filter was created in Lake Formation. This filter performs two features:
- Exclude the
ssncolumn from thesufferersdesk knowledge - Embrace rows the place the state is Texas or New York
To view the information cell filter, select Knowledge filters beneath Knowledge Catalog within the navigation pane of the Lake Formation console, and open the filter. Select View permission to view the permission particulars.
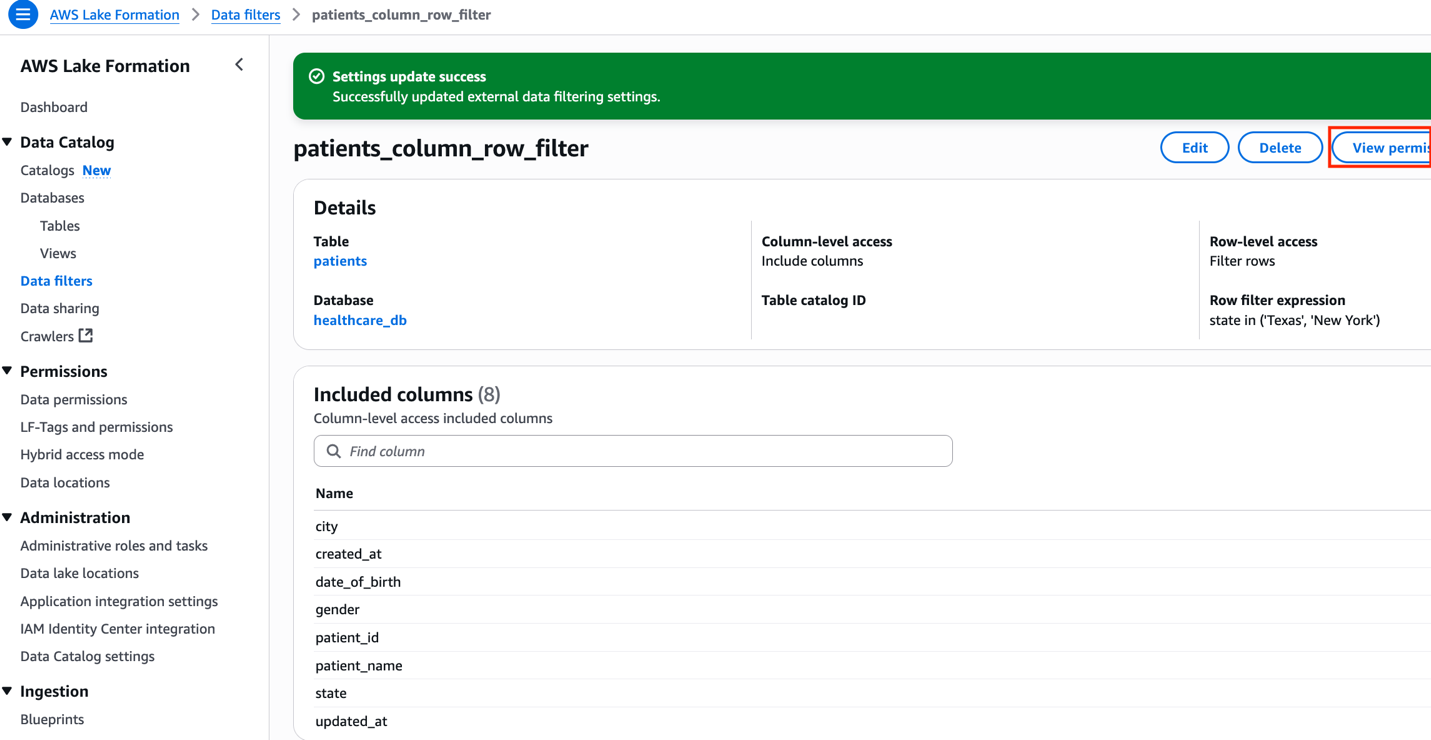
Determine 6: Column and Row stage filter configuration for sufferers desk
FGAC permissions permitting cross-account entry
To view all of the FGAC permissions, select Knowledge permissions beneath Permissions within the navigation pane of the Lake Formation console, and filter by the database title healthcare_db.
Be sure to revoke knowledge permissions with the IAMAllowedPrincipals principal related to the healthcare_db tables, as a result of it can trigger cross-account knowledge sharing to fail, notably with AWS Useful resource Entry Supervisor (AWS RAM).
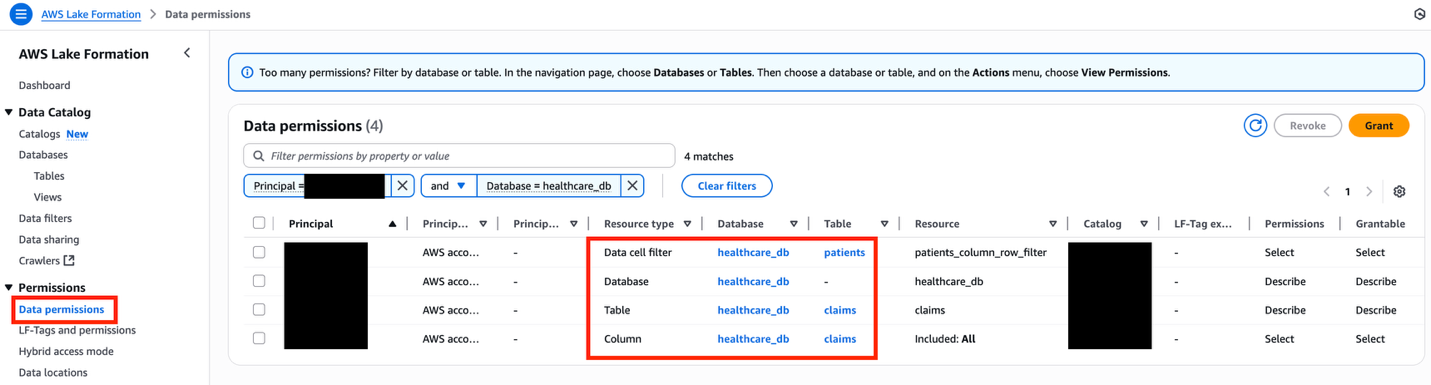
Determine 7: Lake Formation knowledge permissions interface displaying filtered healthcare database assets with granular entry controls
The next desk summarizes the general FGAC setup.
| Useful resource Sort | Useful resource | Permissions | Grant Permissions |
| Database | Describe | Describe | |
| Knowledge Cell Filter | Choose | Choose | |
| Desk | Choose, Describe | Choose, Describe |
Arrange infrastructure in shopper account
To arrange the infrastructure within the shopper account, you should have the next further assets:
- eksctl and kubectl packages should be put in
- An IAM position within the shopper account should be a Lake Formation administrator to run
consumer_emr_on_eks_setup.shscript - The Lake Formation admin should settle for the AWS RAM useful resource share invitations utilizing the AWS RAM console, if the buyer account is outdoors of the producer’s organizational unit
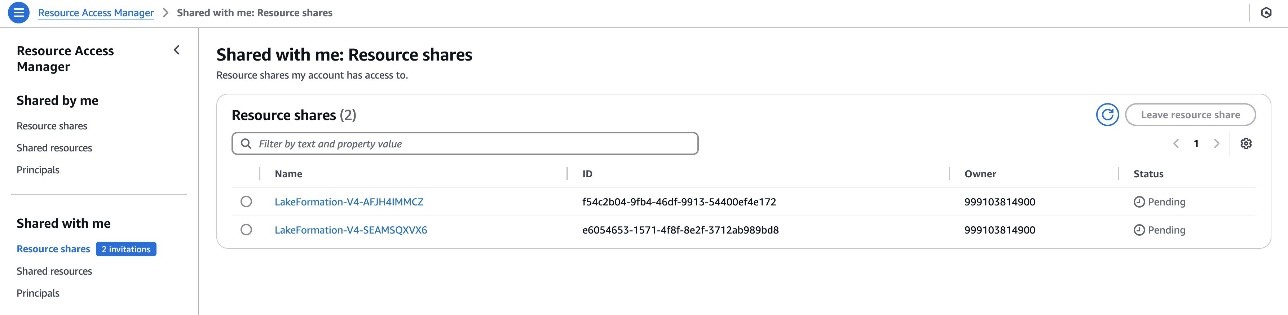
Determine 8: Client account – Cross-account RAM share for Lake Formation useful resource
The setup script deploys the next infrastructure:
- An EKS cluster known as
fgac-blogwith two namespaces:- Person namespace:
lf-fgac-user - System namespace:
lf-fgac-secure
- Person namespace:
- An EMR on EKS digital cluster
emr-on-eks-fgac-blog:- Arrange with a safety configuration
emr-on-eks-fgac-sec-conifg - Two EMR on EKS job execution IAM roles:
- Position for the Sufferers Care Crew (
team1):emr_on_eks_fgac_job_team1_execution_role - Position for Claims Care Crew (
team2):emr_on_eks_fgac_job_team2_execution_role
- Position for the Sufferers Care Crew (
- A question engine IAM position utilized by FGAC safe house:
emr_on_eks_fgac_query_execution_role
- Arrange with a safety configuration
- An S3 bucket to retailer PySpark job scripts and logs
- An AWS Glue native database named
consumer_healthcare_db - Two useful resource hyperlinks to cross-account shared AWS Glue tables:
rl_patientsandrl_claims - Lake Formation permission on Amazon EMR IAM roles
Run the next consumer_emr_on_eks_setup.sh script to arrange a growth surroundings within the shopper account. Replace the parameters based on your use case:
Allow cross-account Lake Formation entry in shopper account
The buyer account should add the buyer account ID with an EMR on EKS Engine session tag in Lake Formation. This session tag shall be utilized by EMR on EKS job execution IAM roles to entry Lake Formation tables. Full the next steps:
- Open the Lake Formation console within the shopper account.
- Select Utility integration settings beneath Administration within the navigation pane.
- Choose Enable exterior engines to filter knowledge in Amazon S3 places registered with Lake Formation.
- For Session tag values, enter EMR on EKS Engine.
- For AWS account IDs, enter your shopper account ID.
- Select Save.
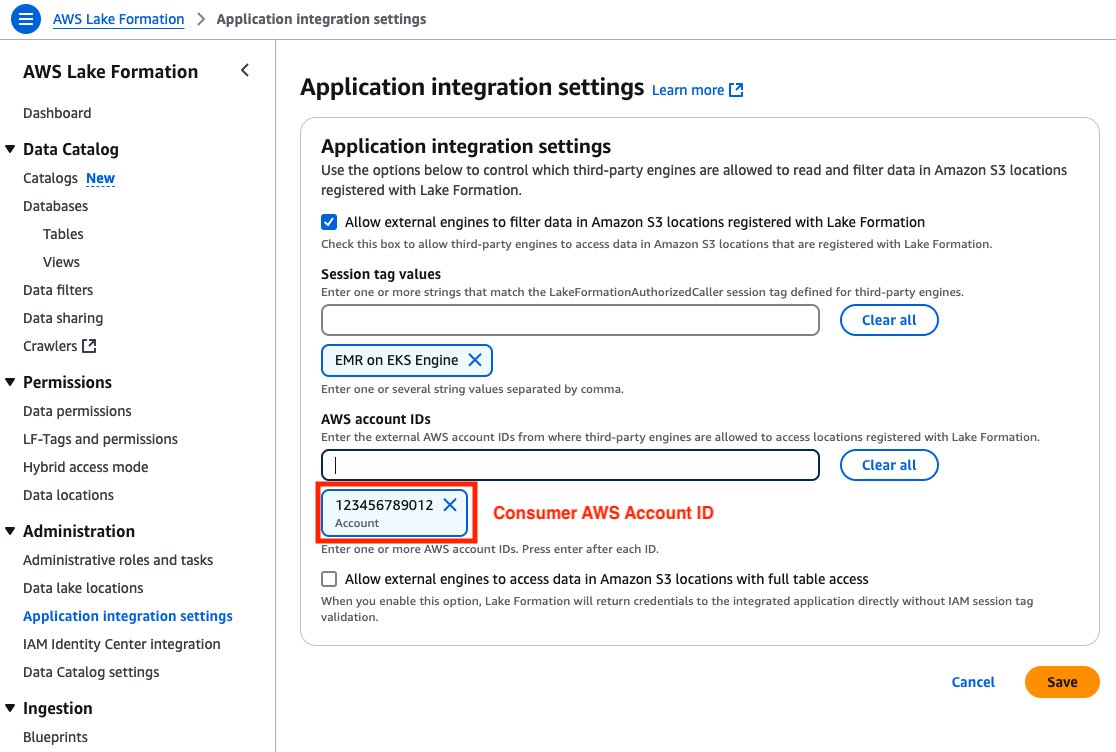
Determine 9: Client Account – Lake Formation third-party engine configuration display screen with session tags, account IDs, and knowledge entry permissions
Validate FGAC setup in shopper surroundings
To validate the FGAC setup within the producer account, verify the EKS cluster, namespaces, and Spark job scripts to check knowledge permissions.
EKS cluster
On the Amazon EKS console, select Clusters within the navigation pane and ensure the EKS cluster fgac-blog is listed.
Determine 10: Client Account – EKS Cluster console web page
Namespaces in Amazon EKS
Kubernetes makes use of namespaces as logical partitioning system for organizing objects similar to Pods and Deployments. Namespaces additionally function as a privilege boundary within the Kubernetes role-based entry management (RBAC) system. Multi-tenant workloads in Amazon EKS could be secured utilizing namespaces.
This resolution creates two namespaces:
lf-fgac-userlf-fgac-secure
The StartJobRun API makes use of the backend workflows to submit a Spark job’s UserComponents (JobRunner, Driver, Executors) within the consumer namespace, and the corresponding system parts within the system namespace to perform the specified FGAC behaviors.
You may confirm the namespaces with the next command:kubectl get namespaceThe next screenshot reveals an instance of the anticipated output.

Determine 11: EKS Cluster namespaces
Spark job script to check Sufferers Care Crew’s knowledge permissions
Beginning with Amazon EMR model 6.6.0, you should utilize Spark on EMR on EKS with the Iceberg desk format. For extra data on how Iceberg works in an immutable knowledge lake, see Construct a high-performance, ACID compliant, evolving knowledge lake utilizing Apache Iceberg on Amazon EMR.
The next script is a snippet of the PySpark job that retrieves filtered knowledge for the Claims and Affected person tables:
Spark job script to check Claims Care Crew’s knowledge permissions
The next script is a snippet of the PySpark job that retrieves knowledge from the Claims desk:
Validate job execution roles for EMR on EKS
The Sufferers Care Crew makes use of the emr_on_eks_fgac_job_team1_execution_role IAM position to execute a PySpark job on EMR on EKS. The job execution position has permission to question each the Sufferers and Claims tables.
The Claims Care Crew makes use of the emr_on_eks_fgac_job_team2_execution_role IAM position to execute jobs on EMR on EKS. The job execution position solely has permission to entry Claims knowledge.
Each IAM job execution roles have the next permissions:
The next code is the job execution IAM position belief coverage:
The next code is the question engine IAM position coverage (emr_on_eks_fgac_query_execution_role-policy):
The next code is the question engine IAM position belief coverage:
Run PySpark jobs on EMR on EKS with FGAC
For extra particulars about the best way to work with Iceberg tables in EMR on EKS jobs, seek advice from Utilizing Apache Iceberg with Amazon EMR on EKS. Full the next steps to run the PySpark jobs on EMR on EKS with FGAC:
- Run the next instructions to run the sufferers and claims jobs:
- Watch the applying logs from the Spark driver pod:
kubectl logs drive-pod-name -c spark-kubernetes-driver -n lf-fgac-user -f
Alternatively, you’ll be able to navigate to the Amazon EMR console, open your digital cluster, and select the open icon subsequent to the job to open the Spark UI and monitor the job progress.

Determine 12: EMR on EKS job runs
View PySpark jobs output on EMR on EKS with FGAC
In Amazon S3, navigate to the Spark output logs folder:
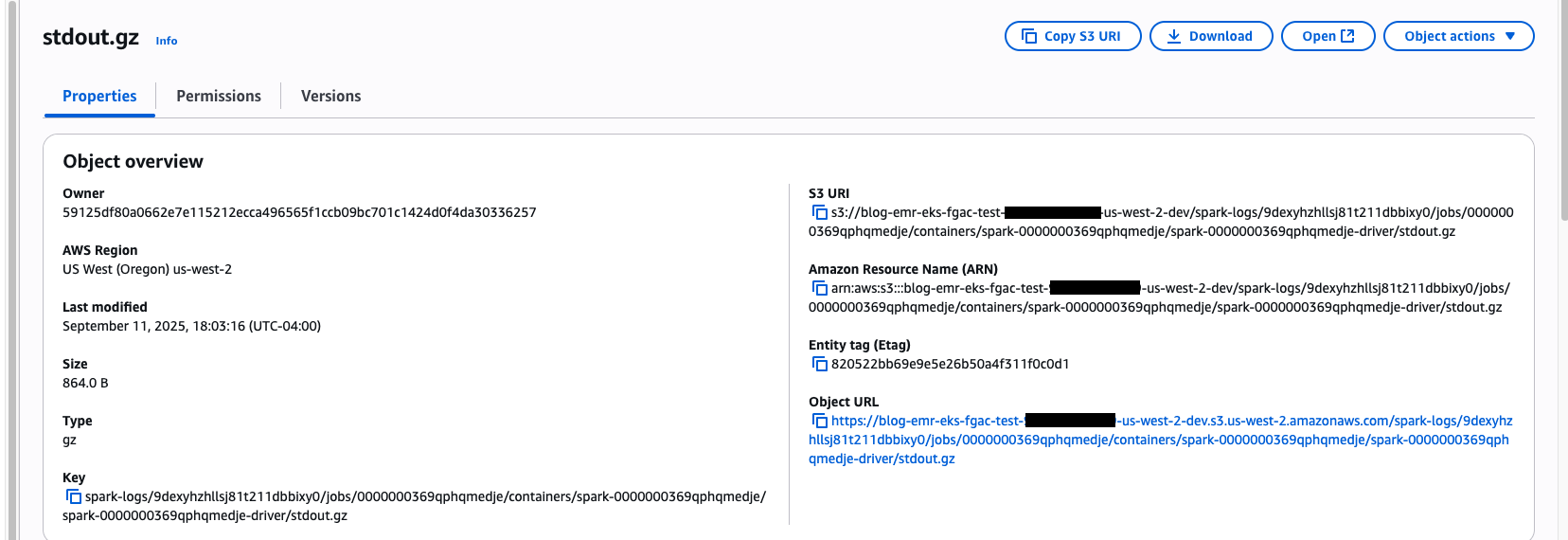
Determine 13: EMR on EKS job’s stdout.gz location on S3 Bucket
The Sufferers Care Crew PySpark job has question entry to the Sufferers and Claims tables. The Sufferers desk has filtered out the SSN column and solely reveals information for Texas and New York declare information, as laid out in our FGAC setup.
The next screenshot reveals the Claims desk for less than Texas and New York.

Determine 14: EMR on EKS Spark job output
The next screenshot reveals the Sufferers desk with out the SSN column.
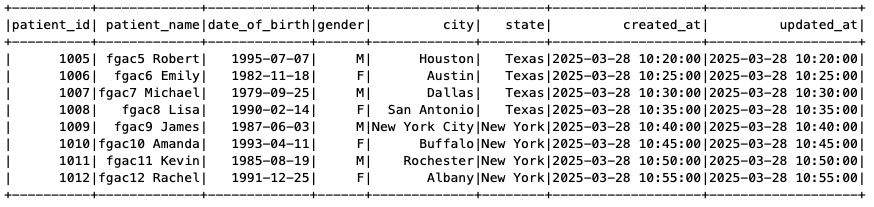
Determine 15: EMR on EKS Spark job output
Equally, navigate to the Spark output log folder for the Claims Care Crew job:
As proven within the following screenshot, the Claims Care Crew solely has entry to the Claims desk, so when the job tried to entry the Sufferers desk, it obtained an entry denied error.
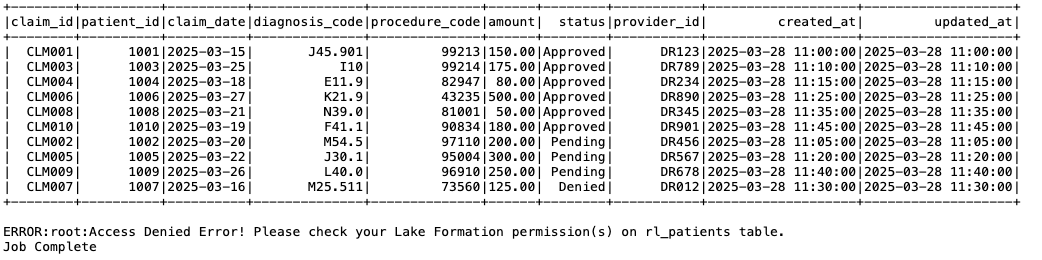
Determine 16: EMR on EKS Spark job output
Issues and limitations
Though the strategy mentioned on this submit offers beneficial insights and sensible implementation methods, it’s vital to acknowledge the important thing concerns and limitations earlier than you begin utilizing this function. To be taught extra about utilizing EMR on EKS with Lake Formation, seek advice from How Amazon EMR on EKS works with AWS Lake Formation.
Clear up
To keep away from incurring future expenses, delete the assets generated for those who don’t want the answer anymore. Run the next cleanup scripts (change the AWS Area if obligatory).Run the next script within the shopper account:
Run the next script within the producer account:
Conclusion
On this submit, we demonstrated the best way to combine Lake Formation with EMR on EKS to implement fine-grained entry management on Iceberg tables. This integration gives organizations a contemporary strategy to implementing detailed knowledge permissions inside a multi-account open knowledge lake surroundings. By centralizing knowledge administration in a main account and punctiliously regulating consumer entry in secondary accounts, this technique can simplify governance and improve safety.
For extra details about Amazon EMR 7.7 in reference to EMR on EKS, see Amazon EMR on EKS 7.7.0 releases. To be taught extra about utilizing Lake Formation with EMR on EKS, see Allow Lake Formation with Amazon EMR on EKS.
We encourage you to discover this resolution to your particular use instances and share your suggestions and questions within the feedback part.