

{kind=link}
Google simply launched its new agent-based internet browser from Google DeepMind, powered by Gemini 2.5 Professional. Constructed on the Gemini API, it might probably “see” and work together with internet and app interfaces: clicking, typing, and scrolling identical to a human. This new AI internet automation mannequin bridges the hole between understanding and motion. On this article, we’ll discover the important thing options of Gemini Pc Use, its capabilities, and tips on how to combine it into your agentic AI workflows.
What’s Gemini 2.5 Pc Use?
Gemini 2.5 Pc Use is an AI assistant that may management a browser utilizing pure language. You describe a aim, and it performs the steps wanted to finish it. Constructed on the brand new computer_use software within the Gemini API, it analyzes screenshots of a webpage or app, then generates actions like “click on,” “sort,” or “scroll.” A consumer comparable to Playwright executes these actions and returns the subsequent display till the duty is completed.
The mannequin interprets buttons, textual content fields, and different interface parts to determine tips on how to act. As a part of Gemini 2.5 Professional, it inherits robust visible reasoning, enabling it to finish complicated on-screen duties with minimal human enter. At present, it’s centered on browser environments and doesn’t management desktop apps exterior the browser.
Key Capabilities
- Automate information entry and filling out kinds on web sites. The agent will be capable to discover fields, enter textual content, and submit kinds the place acceptable.
- Conduct testing of internet functions and person flows, via clicking pages, triggering occasions, and making certain that parts present up precisely.
- Conduct analysis throughout a number of web sites. For instance, it might accumulate details about merchandise, pricing, or opinions throughout a number of e-commerce pages and summarize outcomes.
The right way to Entry Gemini 2.5 Pc Use?
The experimental capabilities of Gemini 2.5 Pc Use at the moment are publicly out there for any developer to play with. Builders simply want to enroll in the Gemini API by way of AI Studio or Vertex AI, after which request entry to the computer-use mannequin. Google gives documentation, runnable code samples and reference implementation you can check out. For instance, the Gemini API docs present an instance of the four-step agent loop, full with examples in Python utilizing the Google Cloud GenAI SDK and Playwright.
You’ll arrange both a browser automation surroundings, comparable to Playwright for this observe these steps:
- Join the Gemini API via AI Studio or Vertex AI.
- Request entry to the computer-use mannequin.
- Assessment Google’s documentation, runnable code samples, and reference implementations.
For example, there’s an agent loop instance utilizing 4 steps in Python supplied by Google with the GenAI SDK and Playwright to automate the browser.
Additionally Learn: The right way to Entry and Use the Gemini API?
Setting Up the Setting
Right here is the overall instance of what the setup appears to be like like along with your code:
Preliminary Configuration and Gemini Consumer
# Load surroundings variables
from dotenv import load_dotenv
load_dotenv()
# Initialize Gemini API consumer
from google import genai
consumer = genai.Consumer()
# Set display dimensions (advisable by Google)
SCREEN_WIDTH = 1440
SCREEN_HEIGHT = 900 We’ll start by organising the surroundings variables are loaded for the API credentials, and the Gemini consumer is initialized. The advisable display dimensions by Google are outlined, and later used to transform normalized coordinates to the precise pixel values vital for actions within the UI.
Browser Automation with Playwright
Subsequent, the code units up Playwright for browser automation:
from playwright.sync_api import sync_playwright
playwright = sync_playwright().begin()
browser = playwright.chromium.launch(
headless=False,
args=[
'--disable-blink-features=AutomationControlled',
'--disable-dev-shm-usage',
'--no-sandbox',
]
)
context = browser.new_context(
viewport={"width": SCREEN_WIDTH, "peak": SCREEN_HEIGHT},
user_agent="Mozilla/5.0 (Home windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/131.0.0.0 Safari/537.36",
)
web page = context.new_page() Defining the Process and Mannequin Configuration
Right here we’re launching a Chromium browser, using the anti-detection flags to stop webpages from recognizing automation. Then we outline a practical viewport and user-agent as a way to emulate a traditional person and create a brand new web page as a way to navigate and automate interplay.
After the browser is ready up and able to go, the mannequin is supplied with the person’s aim and given the preliminary screenshot:
from google.genai.varieties import Content material, Half
USER_PROMPT = "Go to BBC Information and discover at the moment's high know-how headlines"
initial_screenshot = web page.screenshot(sort="png")
contents = [
Content(role="user", parts=[
Part(text=USER_PROMPT),
Part.from_bytes(data=initial_screenshot, mime_type="image/png")
])
] The USER_PROMPT defines what natural-language activity the agent will undertake. It captures an preliminary screenshot of the state of the browser web page, which is able to then be despatched, together with the immediate to the mannequin. They’re encapsulated with the Content material object that can later even be handed to the Gemini mannequin.
Lastly, the agent loop runs sending the standing to the mannequin and executing the actions it returns:
The computer_use software prompts the mannequin to create perform calls, that are then executed within the browser surroundings. thinking_config holds the intermediate steps of reasoning to offer transparency to the person, which can be helpful for later debugging or understanding the agent’s decision-making course of.
from google.genai.varieties import varieties
config = varieties.GenerateContentConfig(
instruments=[types.Tool(
computer_use=types.ComputerUse(
environment=types.Environment.ENVIRONMENT_BROWSER
)
)],
thinking_config=varieties.ThinkingConfig(include_thoughts=True),
)The way it Works?
Gemini 2.5 Pc Use runs as a closed-loop agent. You give it a aim and a screenshot, it predicts the subsequent motion, executes it via the consumer, after which opinions the up to date display to determine what to do subsequent. This suggestions loop permits Gemini to see, motive, and act very similar to a human navigating a browser. Your entire course of is powered by the computer_use software within the Gemini API.
The Core Suggestions Loop
The agent operates in a steady cycle till the duty is full:
- Enter aim and screenshot: The mannequin receives the person’s instruction (e.g., “discover high tech headlines”) and the screenshot of the present state of the browser.
- Generate actions: The mannequin suggests a number of perform calls that correspond to UI actions utilizing the computer_use software.
- Execute actions: The consumer program carries out these perform calls within the browser.
- Seize suggestions: A brand new screenshot and URL are captured and despatched again to the mannequin.
What the Mannequin Sees in Every Iteration
With each iteration, the mannequin receives three key items of knowledge:
- Consumer request: The natural-language aim or instruction (instance: “discover the highest information headlines”)
- Present screenshot: A picture of your browser or app window and its present state
- Motion historical past: A file of latest actions taken up to now (for context)
The mannequin analyzes the screenshot and the person’s aim, then generates a number of perform calls—every representing a UI motion. For instance:
{"title": "click_at", "args": {"x": 400, "y": 600}}This may instruct the agent to click on at these coordinates.
Executing Actions within the Browser
The consumer program (utilizing Playwright’s mouse and keyboard APIs) executes these actions within the browser. Right here’s an instance of how perform calls are executed:
def execute_function_calls(candidate, web page, screen_width, screen_height):
for half in candidate.content material.elements:
if half.function_call:
fname = half.function_call.title
args = half.function_call.args
if fname == "click_at":
actual_x = int(args["x"] / 1000 * screen_width)
actual_y = int(args["y"] / 1000 * screen_height)
web page.mouse.click on(actual_x, actual_y)
elif fname == "type_text_at":
actual_x = int(args["x"] / 1000 * screen_width)
actual_y = int(args["y"] / 1000 * screen_height)
web page.mouse.click on(actual_x, actual_y)
web page.keyboard.sort(args["text"])
# ...different supported actions...The perform parses the FunctionCall entries returned by the mannequin and executes every motion within the browser. It converts normalized coordinates (0–1000) into precise pixel values primarily based on the display measurement.
Capturing Suggestions for the Subsequent Cycle
After executing actions, the system captures the brand new state and sends it again to the mannequin:
def get_function_responses(web page, outcomes):
screenshot_bytes = web page.screenshot(sort="png")
current_url = web page.url
function_responses = []
for title, end result, extra_fields in outcomes:
response_data = {"url": current_url}
response_data.replace(end result)
response_data.replace(extra_fields)
function_responses.append(
varieties.FunctionResponse(
title=title,
response=response_data,
elements=[types.FunctionResponsePart(
inline_data=types.FunctionResponseBlob(
mime_type="image/png",
data=screenshot_bytes
)
)]
)
)
return function_responsesThe brand new state of the browser is wrapped in FunctionResponse objects, which the mannequin makes use of to motive about what to do subsequent. The loop continues till the mannequin not returns any perform calls or till the duty is accomplished.
Additionally Learn: High 7 Pc Use Brokers
Agent Loop Steps
After loading the computer_use software, a typical agent loop follows these steps:
- Ship a request to the mannequin: Embody the person’s aim and a screenshot of the present browser state within the API name
- Obtain mannequin response: The mannequin returns a response containing textual content and/or a number of FunctionCall entries.
- Execute the actions: The consumer code parses every perform name and performs the motion within the browser.
- Seize and ship suggestions: After executing, the consumer takes a brand new screenshot and notes the present URL. It wraps these in a FunctionResponse and sends them again to the mannequin as the subsequent person message. This tells the mannequin the results of its motion so it might probably plan the subsequent step.
This course of runs mechanically in a loop. When the mannequin stops producing new perform calls, it indicators that the duty is full. At that time, it returns any last textual content output, comparable to a abstract of what it achieved. Most often, the agent will undergo a number of cycles earlier than both finishing the aim or reaching the set flip restrict.
Extra Supported Actions
Gemini’s Pc Use software has dozens of built-in UI actions. The essential set contains actions which can be typical for web-based functions, together with:
- open_web_browser: Initializes the browser earlier than the agent loop begins (usually dealt with by the consumer).
- click_at: Clicks on a particular (x, y) coordinate on the web page.
- type_text_at: Clicks at a degree and kinds a given string, optionally urgent Enter.
- navigate: Opens a brand new URL within the browser.
- go_back / go_forward: Strikes backward or ahead within the browser historical past.
- hover_at: Strikes the mouse to a particular level to set off hover results.
- scroll_document / scroll_at: Scrolls all the web page or a particular part.
- key_combination: Simulates urgent keyboard shortcuts.
- wait_5_seconds: Pauses execution, helpful for ready on animations or web page masses.
- drag_and_drop: Clicks and drags a component to a different location on the web page.
Google’s documentation mentions that the pattern implementation contains the three most typical actions: open_web_browser, click_at, and type_text_at. You’ll be able to lengthen this by including some other actions you want or excluding ones that aren’t related to your workflow.
Efficiency and Benchmarks
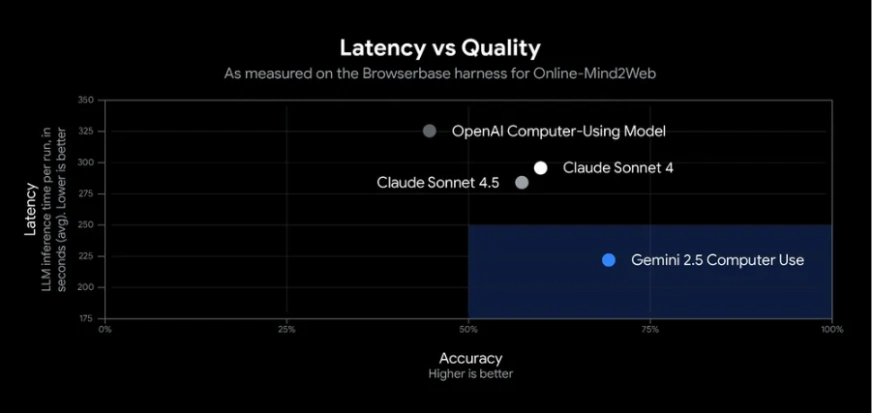
Gemini 2.5 Pc Use performs strongly in UI management duties. In Google’s exams, it achieved over 70% accuracy with round 225 ms latency, outperforming different fashions in internet and cell benchmarks comparable to looking websites and finishing app workflows.
In apply, the agent can reliably deal with duties like filling kinds and retrieving information. Impartial benchmarks rank it as probably the most correct and quickest public AI mannequin for easy browser automation. Its robust efficiency comes from Gemini 2.5 Professional’s visible reasoning and an optimized API pipeline. Because it’s nonetheless in preview, it’s best to monitor its actions, occasional errors could happen.
Additionally Learn:
Conclusion
The Gemini 2.5 Pc Use is a big improvement in AI-Supported Automation, permitting brokers to successfully and effectively work together with actual interfaces. With it, builders can automate duties like internet looking, information entry, or information extraction with nice accuracy and velocity.
In its publicly out there state, we are able to provide builders a technique to safely experiment with the capabilities of Gemini 2.5 Pc Use, adapting it into their very own workflows. General, it represents a versatile framework via which to construct next-generation sensible assistants or highly effective automation workflows for quite a lot of makes use of and domains.
Whats up! I am Vipin, a passionate information science and machine studying fanatic with a robust basis in information evaluation, machine studying algorithms, and programming. I’ve hands-on expertise in constructing fashions, managing messy information, and fixing real-world issues. My aim is to use data-driven insights to create sensible options that drive outcomes. I am desperate to contribute my abilities in a collaborative surroundings whereas persevering with to study and develop within the fields of Knowledge Science, Machine Studying, and NLP.
Login to proceed studying and luxuriate in expert-curated content material.