

{kind=link}
Organizations handle content material throughout a number of languages as they broaden globally. Ecommerce platforms, buyer assist programs, and information bases require environment friendly multilingual search capabilities to serve numerous consumer bases successfully. This unified search strategy helps multinational organizations keep centralized content material repositories whereas ensuring customers, no matter their most popular language, can successfully discover and entry related info.
Constructing multi-language functions utilizing language analyzers with OpenSearch generally includes a big problem: multi-language paperwork require guide preprocessing. Which means in your utility, for each doc, you will need to first establish every area’s language, then categorize and label it, storing content material in separate, pre-defined language fields (for instance, name_en, name_es, and so forth) with a view to use language analyzers in search to enhance search relevancy. This client-side effort is complicated, including workload for language detection, doubtlessly slowing information ingestion, and risking accuracy points if languages are misidentified. It’s a labor-intensive strategy. Nevertheless, Amazon OpenSearch Service 2.15+ introduces an AI-based ML inference processor. This new function robotically identifies and tags doc languages throughout ingestion, streamlining the method and eradicating the burden out of your utility.
By harnessing the ability of AI and utilizing context-aware information modeling and clever analyzer choice, this automated resolution streamlines doc processing by minimizing guide language tagging, and allows automated language detection throughout ingestion, offering organizations refined multilingual search capabilities.
Utilizing language identification in OpenSearch Service provides the next advantages:
- Enhanced consumer expertise – Customers can now discover related content material whatever the language they search in
- Elevated content material discovery – The service can floor invaluable content material throughout language silos
- Improved search accuracy – Language-specific analyzers present higher search relevance
- Automated processing – You possibly can scale back guide language tagging and classification
On this put up, we share the best way to implement a scalable multilingual search resolution utilizing OpenSearch Service.
Answer overview
The answer eliminates guide language preprocessing by robotically detecting and dealing with multilingual content material throughout doc ingestion. As an alternative of manually creating separate language fields (en_notes, es_notes, and so forth) or implementing customized language detection programs, the ML inference processor identifies languages and creates acceptable area mappings.
This automated strategy improves accuracy in comparison with conventional guide strategies and reduces improvement complexity and processing overhead, permitting organizations to concentrate on delivering higher search experiences to their world customers.
The answer contains the next key elements:
- ML inference processor – Invokes ML fashions throughout doc ingestion to counterpoint content material with language metadata
- Amazon SageMaker integration – Hosts pre-trained language identification fashions that analyze textual content fields and return language predictions
- Language-specific indexing – Applies acceptable analyzers based mostly on detected languages, offering correct dealing with of stemming, cease phrases, and character normalization
- Connector framework – Allows safe communication between OpenSearch Service and Amazon SageMaker endpoints by way of AWS Id and Entry Administration (IAM) role-based authentication.
The next diagram illustrates the workflow of the language detection pipeline.
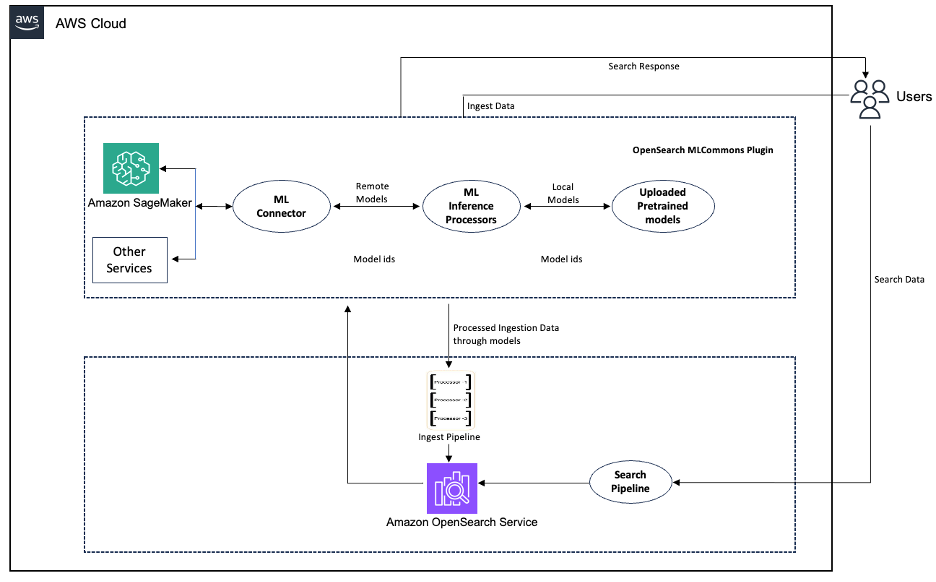
Determine 1: Workflow of the language detection pipeline
This instance demonstrates textual content classification utilizing XLM-RoBERTa-base for language detection on Amazon SageMaker. You may have flexibility in selecting your fashions and might alternatively use the built-in language detection capabilities of Amazon Comprehend.
Within the following sections, we stroll by way of the steps to deploy the answer. For detailed implementation directions, together with code examples and configuration templates, seek advice from the excellent tutorial within the OpenSearch ML Commons GitHub repository.
Stipulations
You should have the next stipulations:
Deploy the mannequin
Deploy a pre-trained language identification mannequin on Amazon SageMaker. The XLM-RoBERTa mannequin gives strong multilingual language detection capabilities appropriate for many use circumstances.
Configure the connector
Create an ML connector to determine a safe connection between OpenSearch Service and Amazon SageMaker endpoints, primarily for language detection duties. The method begins with organising authentication by way of IAM roles and insurance policies, making use of correct permissions for each companies to speak securely.
After you configure the connector with the suitable endpoint URLs and credentials, the mannequin is registered and deployed in OpenSearch Service and its modelID is utilized in subsequent steps.
Pattern response:
After you configure the connector, you may check is by sending textual content to the mannequin by way of OpenSearch Service, and it’ll return the detected language (for instance, sending “Say this can be a check” returns en for English).
Arrange the ingest pipeline
Configure the ingest pipeline, which makes use of ML inference processors to robotically detect the language of the content material within the identify and notes fields of incoming paperwork. After language detection, the pipeline creates new language-specific fields by copying the unique content material to new fields with language suffixes (for instance, name_en for English content material).
The pipeline makes use of an ml_inference processor to carry out the language detection and replica processors to create the brand new language-specific fields, making it easy to deal with multilingual content material in your OpenSearch Service index.
Configure the index and ingest paperwork
Create an index with the ingest pipeline that robotically detects the language of incoming paperwork and applies acceptable language-specific evaluation. When paperwork are ingested, the system identifies the language of key fields, creates language-specific variations of these fields, and indexes them utilizing the right language analyzer. This enables for environment friendly and correct looking out throughout paperwork in a number of languages with out requiring guide language specification for every doc.
Right here’s a pattern index creation API name demonstrating totally different language mappings.
Subsequent, ingest this enter doc in German
The German textual content used within the previous code shall be processed utilizing a German-specific analyzer, supporting correct dealing with of language-specific traits equivalent to compound phrases and particular characters.
After profitable ingestion into OpenSearch Service, the ensuing doc seems as follows:
Search paperwork
This step demonstrates the search functionality after the multilingual setup. Through the use of a multi_match question with name_* fields, it searches throughout all language-specific identify fields (name_en, name_es, name_de) and efficiently finds the Spanish doc when trying to find “comprar” as a result of the content material was correctly analyzed utilizing the Spanish analyzer. This instance exhibits how the language-specific indexing allows correct search ends in the right language while not having to specify which language you’re looking out in.
This search appropriately finds the Spanish doc as a result of the name_es area is analyzed utilizing the Spanish analyzer:
Cleanup
To keep away from ongoing fees and delete the sources created on this tutorial, carry out the next cleanup steps
- Delete the Opensearch service area. This stops each storage prices in your vectorized information and any related compute fees.
- Delete the ML connector that hyperlinks your OpenSearch service to your machine studying mannequin.
- Lastly, delete your Amazon SageMaker endpoints and sources.
Conclusion
Implementing multilingual search with OpenSearch Service may help organizations break down language limitations and unlock the complete worth of their world content material. The ML inference processor gives a scalable, automated strategy to language detection that improves search accuracy and consumer expertise.
This resolution addresses the rising want for multilingual content material administration as organizations broaden globally. By robotically detecting doc languages and making use of acceptable linguistic processing, companies can ship complete search experiences that serve numerous consumer bases successfully.