

{kind=link}

Pure Storage at present unveiled FlashBlade//EXA, a brand new all-flash storage array designed to satisfy the demanding wants of AI factories and multi-modal AI coaching. FlashBlade//EXA separates the metadata layer from the information path within the I/O stream, which Pure says permits the array to maneuver knowledge charges exceeding 10 terabytes per second per namespace.
FlashBlade//EXA is an enlargement of Pure Storage’s current choices, together with FlashBlade//S, its high-performance array for file and object workloads, in addition to FlashBlade//E, its giant scale array designed for storing unstructured knowledge.
The brand new array splits the high-speed I/O into two elements. The metadata is routed via the metadata core element of the FlashBlade//EXA, which is predicated on high-speed DirectFlash Module (DFM) nodes that home the corporate’s scale-out distributed key-value retailer. The metadata core nodes run on the Purity//FB working system, which has been bolstered with assist for Parallel NFS (pNFS) to speak with the compute nodes.
Block knowledge is individually routed over Distant Direct Reminiscence Entry (RDMA) to the information nodes, that are trade customary Linux-based servers with this launch (the corporate plans to include its DFM tech in a future launch). This structure permits FlashBlade//EXA to achieve the utmost allowable bandwidth between the information storage and the compute nodes.
“This segregation offers non-blocking knowledge entry that will increase exponentially in high-performance computing eventualities the place the metadata requests can equal, if not outnumber, knowledge I/O operations,” writes Alex Castro, a Pure Storage vp, in a weblog publish.

FlashBlade//EXA separates the metadata stream from the block knowledge stream, eradicating an I/O bottleneck, Pure Storage says
When Solar Microsystems created NFS again in 1984, performance was the first focus, not efficiency, Castro says. Nonetheless, legacy NAS gadgets that require extra I/O controllers to be added with every new knowledge node have created a bottleneck to efficiency. Splitting the I/O is the important thing to unlocking the bottleneck created by legacy NAS arrays, he says.
“Many storage distributors focusing on the high-performance nature of huge AI workloads solely remedy for half of the parallelism downside–providing the widest networking bandwidth potential for purchasers to get to knowledge targets,” Castro writes. “They don’t handle how metadata and knowledge are serviced at large throughput, which is the place the bottlenecks at giant scale emerge.”
Some storage distributors have resorted to utilizing specliazed file techniques, akin to Lustre, to ship the parallelism wanted for big scale tasks, Castro writes, however these environments had been susceptible to metadata latency and required Phd-level expertise to handle. On the opposite facet, different distributors have inserted a compute aggregation layer between the compute purchasers and the information supply.
“This mannequin suffers from enlargement rigidity and extra administration complexity challenges than pNFS when scaling for enormous efficiency as a result of it entails including extra transferring elements with compute aggregation nodes,” Castro says. “This rigidity forces knowledge and metadata to scale in lockstep, creating inefficiencies for multimodal and dynamic workloads.”
Supply: Pure Storage
Pure says it developed the FlashBlade//EXA to satisfy the rising wants of “AI factories,” and specifically the necessity to hold hundreds of high-end GPUs fed with knowledge.
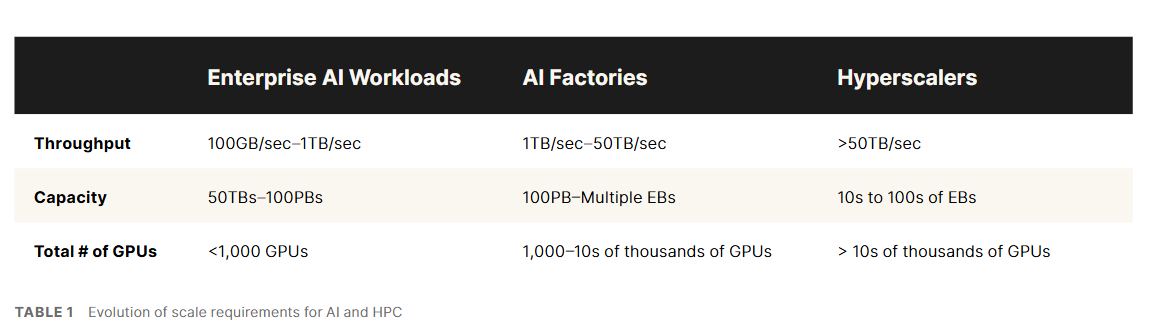
When it comes to scale, AI factories sit within the center. On the low finish are enterprise AI workloads, akin to inference and RAG, that work on 50TB to 100PB of information, whereas AI factories will want entry to as much as 10,000 GPUs on knowledge units from 100PB to a number of exabytes. On the excessive finish, hyperscalers can have upwards of 100EBs and greater than 10,000 GPUs. In any respect ranges, having idle GPUs is an obstacle to productiveness.
“Knowledge is the gasoline for enterprise AI factories, straight impacting efficiency and reliability of AI purposes,” Rob Davis, Nvidia’s vp of storage networking know-how, stated in a press launch. “With Nvidia networking, the FlashBlade//EXA platform permits organizations to leverage the total potential of AI applied sciences whereas sustaining knowledge safety, scalability, and efficiency for mannequin coaching, nice tuning, and the most recent agentic AI and reasoning inference necessities.”
Pure Storage says it expects to start out transport FlashBlade//EXA this summer time.
Associated Gadgets:
AI to Goose Demand for All Flash Arrays, Pure Storage Says